




一提到日誌收集方案,大家第一個想到的肯定是ELK(Elasticsearch、Logstash、Kibana ),但Logstash依賴於JVM不管是性能還是簡介性,都不是日誌收集agent的首選。
個人感覺一個好的agent應該是資源佔用少,性能好,不依賴別的組件,可以獨立部署。而Logstash明顯不符合這幾點要求,也許正是基於這些考慮elastic推出了一個新的組件Filebeat。
我們這邊收集日誌應對的場景主要是:文本日誌、docker日誌、k8s日誌,恰恰這些EFK全家桶都支持。
我們希望日誌收集產品可以滿足以下幾個需求:
- 按照項目、應用維度檢索日誌(因爲大家檢索日誌的時候,肯定是檢索某個應用的日誌)
- 支持檢索出某條想要的日誌後,可以查看上下文(查看該日誌所在日誌文件的前後多少條)
- 支持日誌下載(目前支持兩種場景:搜過結果的下載、某條日誌所在日誌文件的下載)
- 支持Elasticsearch Query String查詢
- 支持自動化部署Filebeat,部署過程可視化
基於需求及ELK套件,梳理我們場景中特有的東西:
- docker日誌的場景比較單一,都是通過之前一個產品A發佈部署的,其docker命名規則比較統一,可以通過docker.container.name截取來獲取應用名字
- k8s場景也比較統一,都是通過之前一個產品B發佈部署的,其pod命名規則比較統一,可以通過kubernetes.pod.name截取來獲取應用名字
- 文本日誌,我們強制要求log文件的上層目錄必須是應用名,因此,也可以截取到應用名稱。
其實,我們不太推薦寫日誌,寫到文本文件中,使用標準輸出就好。
到這裏可以發現我們可以選擇Filebeat來作爲日誌的收集端,Elasticsearch來存儲日誌並提供檢索能力。
那麼,日誌的清洗在哪裏做呢?
日誌的清洗一般有兩種方式:
- 先把日誌收集到kafka,再通過Logstash消費kafka的數據,來清洗數據
- 直接通過Elasticsearch的[Ingest Node]來清洗數據,因爲Ingest Node也支持Grok表達式
對於,我們的場景而言,我們需要清洗數據的要求比較簡單,主要是應用名稱的截取還有文本日誌中日誌時間的處理(@timestamp重置,時區處理),所以我們選擇了方案2。
其實,選擇方案二還有個原因就是:系統在滿足需求的同時,儘量保持簡單,減少依賴的組件。
到這裏可以,可以看出我們的架構基本如下:
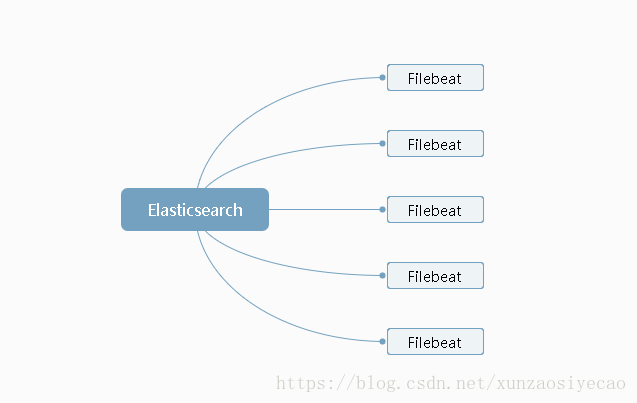
在我們的方案中,並沒有提供Kibana 的界面直接給用戶用,而是我們自己根據需要獨立開發的。
代碼架構:
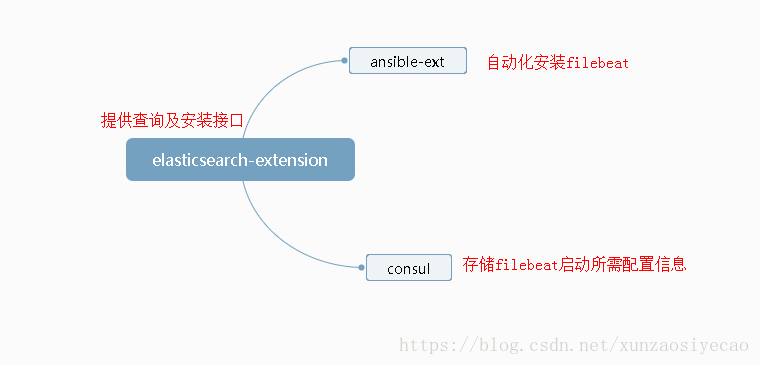
elasticsearch-extension提供的功能可以參見github:elasticsearch-extension
如果日誌需要清洗的比較多,可以採用方案1,或者先不清洗,先把數據落到Elasticsearch,然後在查詢的時候,進行處理。比如在我們的場景中,可以先把日誌落到Elasticsearch中,然後在需要檢索應用名稱的時候,通過代碼來處理並獲取app名字。
個人微信公衆號:

作者:jiankunking 出處:http://blog.csdn.net/jiankunking