




1、Spark調優背景
目前Zeppelin已經上線一段時間,Spark作爲底層SQL執行引擎,需要進行整體性能調優,來提高SQL查詢效率。本文主要給出調優的結論,因爲涉及參數很多,故沒有很細粒度調優,但整體調優方向是可以得出的。
環境:服務器600+,spark 2.0.2,Hadoop 2.6.0
2、調優結果
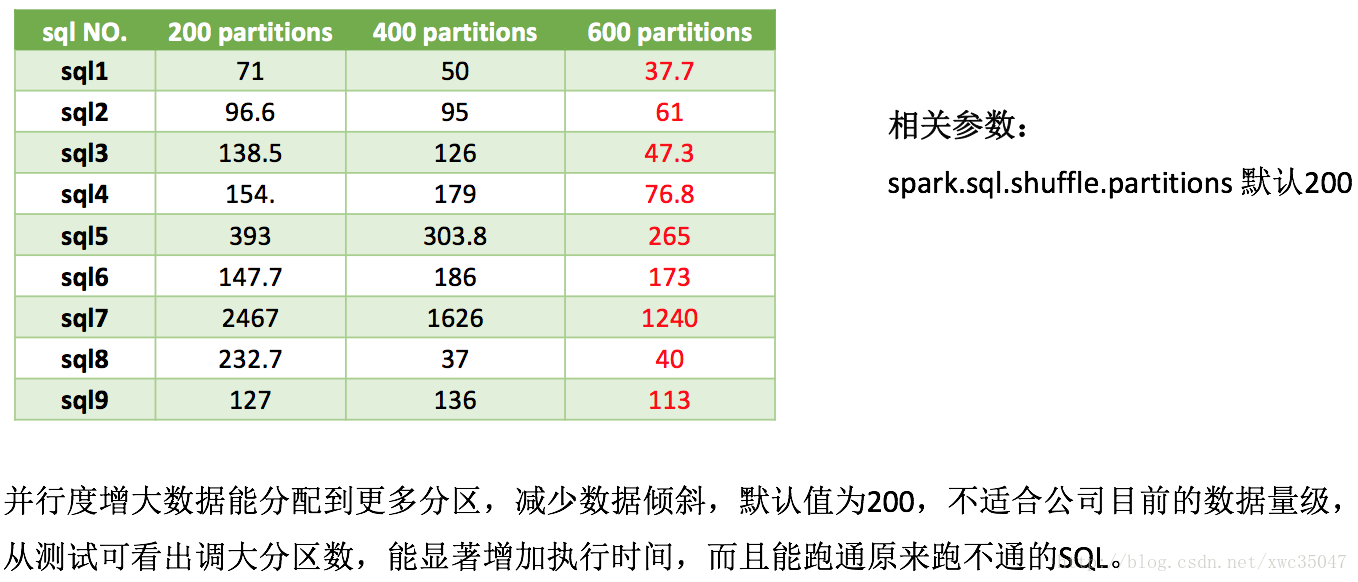
調優隨機選取線上9條SQL,表橫軸是調優測試項目,測試在集羣空閒情況下進行,後一個的測試都是疊加前面測試參數。從數據可參數經過調優,理想環境下性能可提高50%到300%
3、 下面爲調優分享PPT
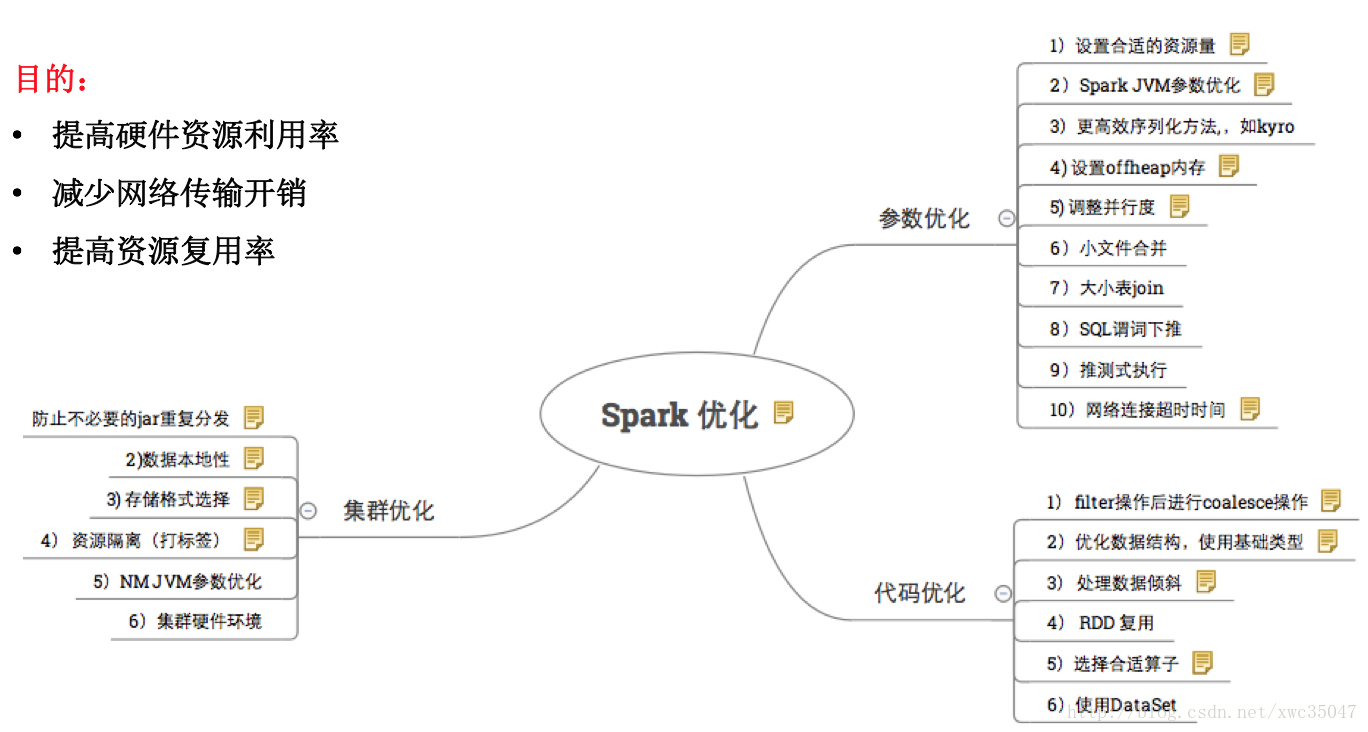
1)一圖概覽
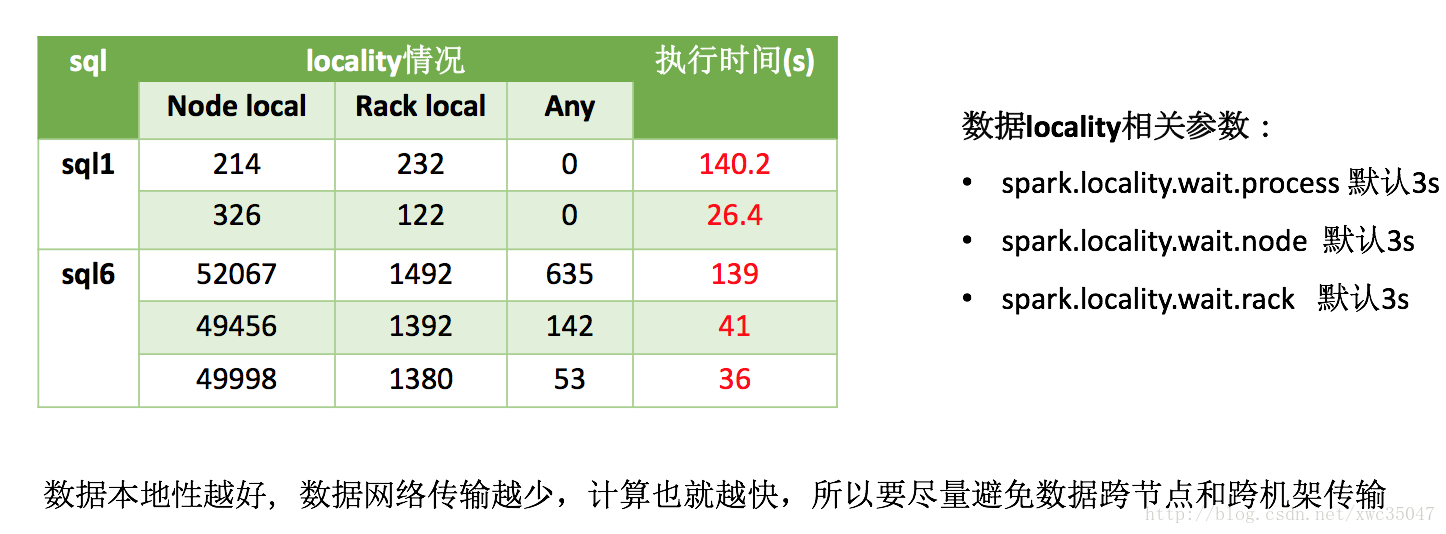
2) Spark集羣優化——數據本地性
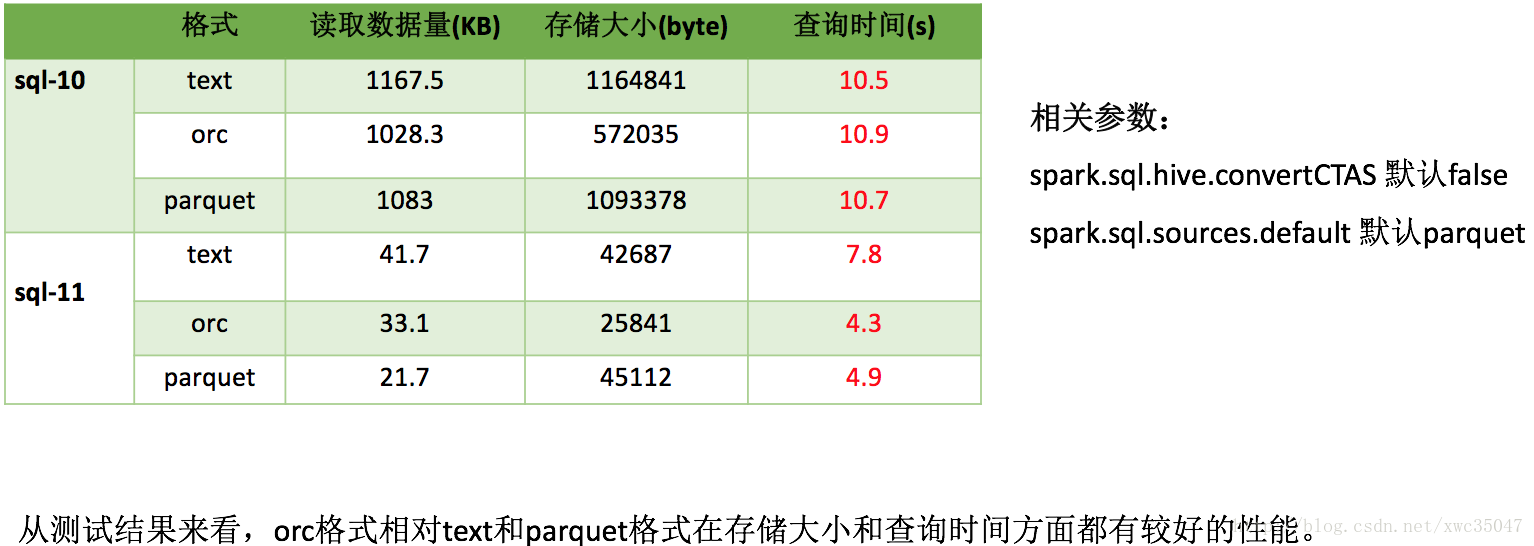
3)Spark集羣優化——存儲格式選擇
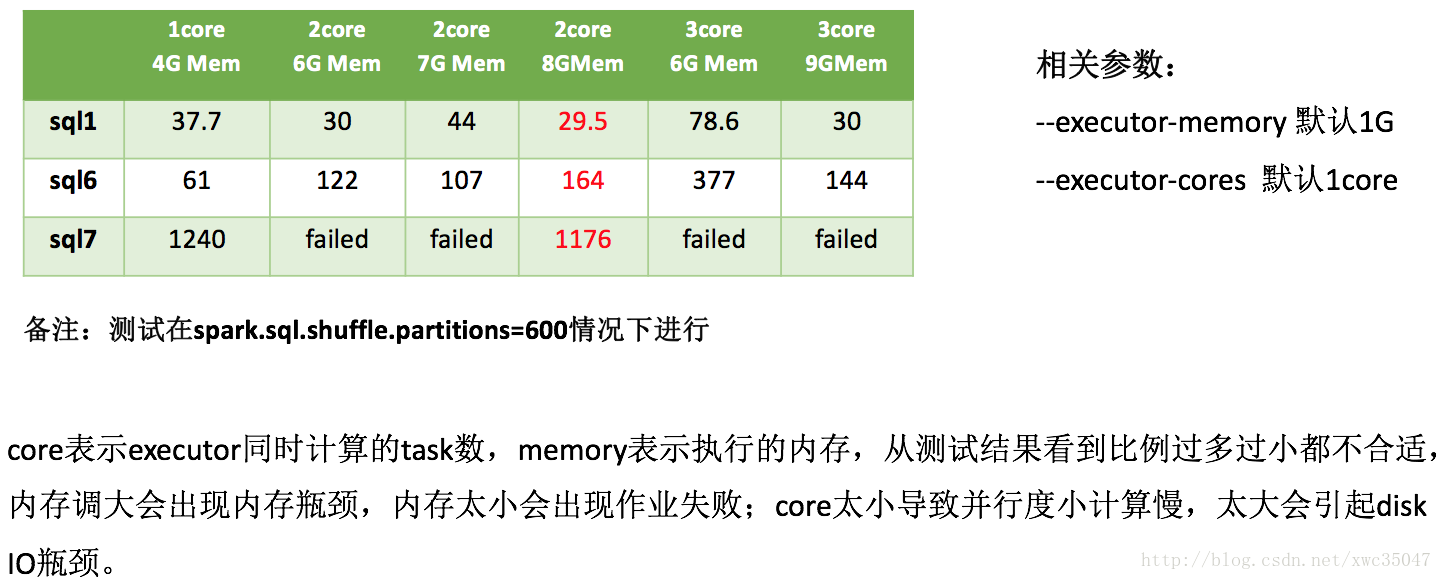
4)Spark參數優化——計算資源
5) Spark參數優化——並行度
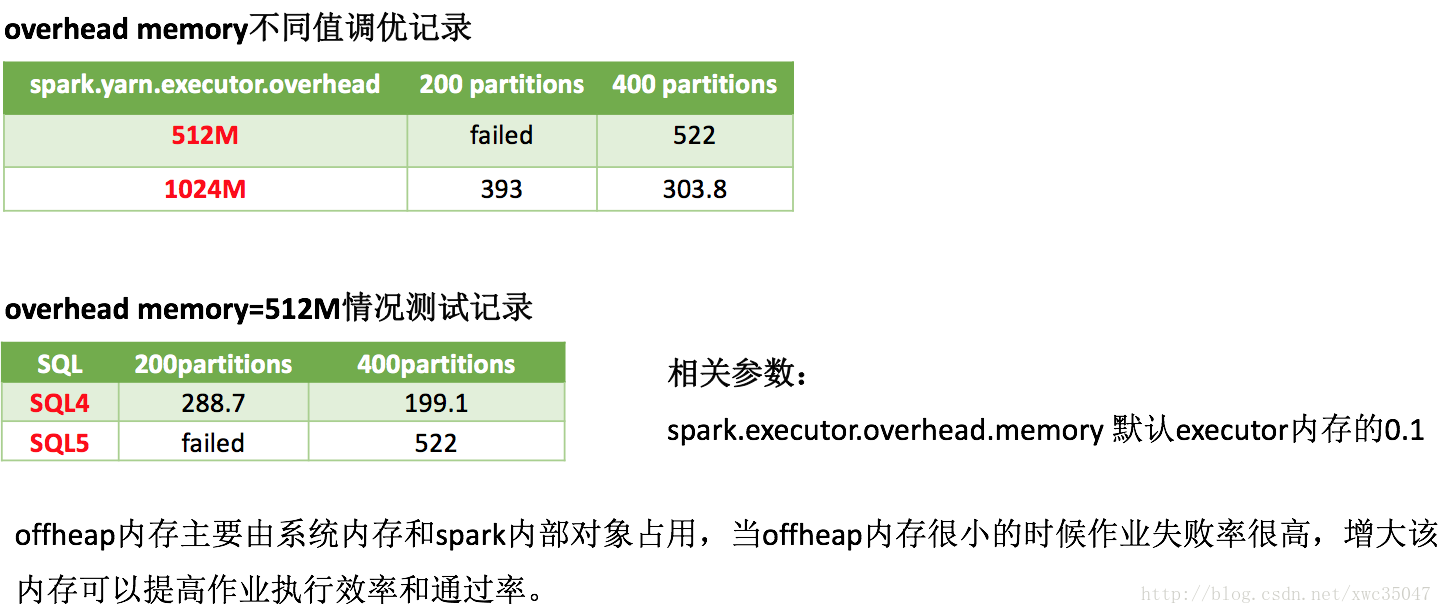
6)Spark參數優化——offheap內存
7)Spark參數優化——大小表join

8)Spark參數優化——其他

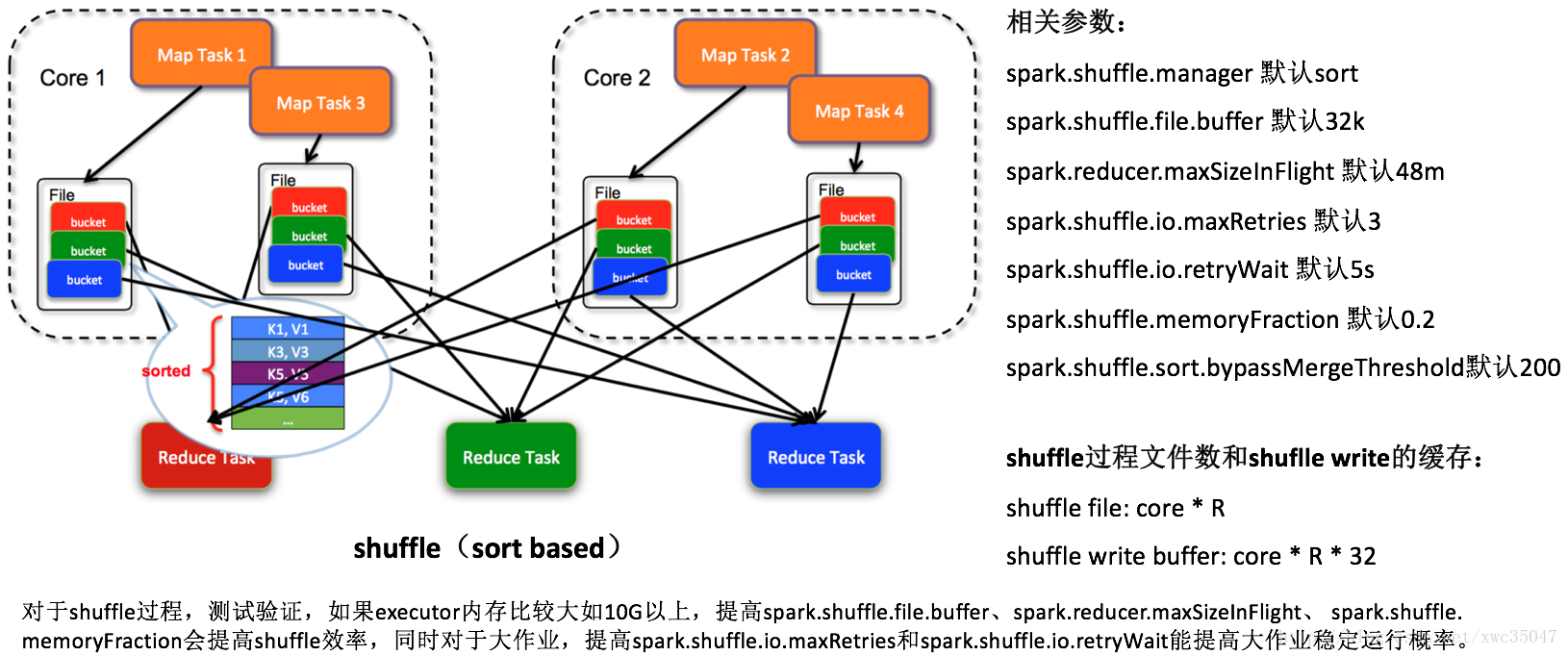
9) Spark參數優化——shuffle過程
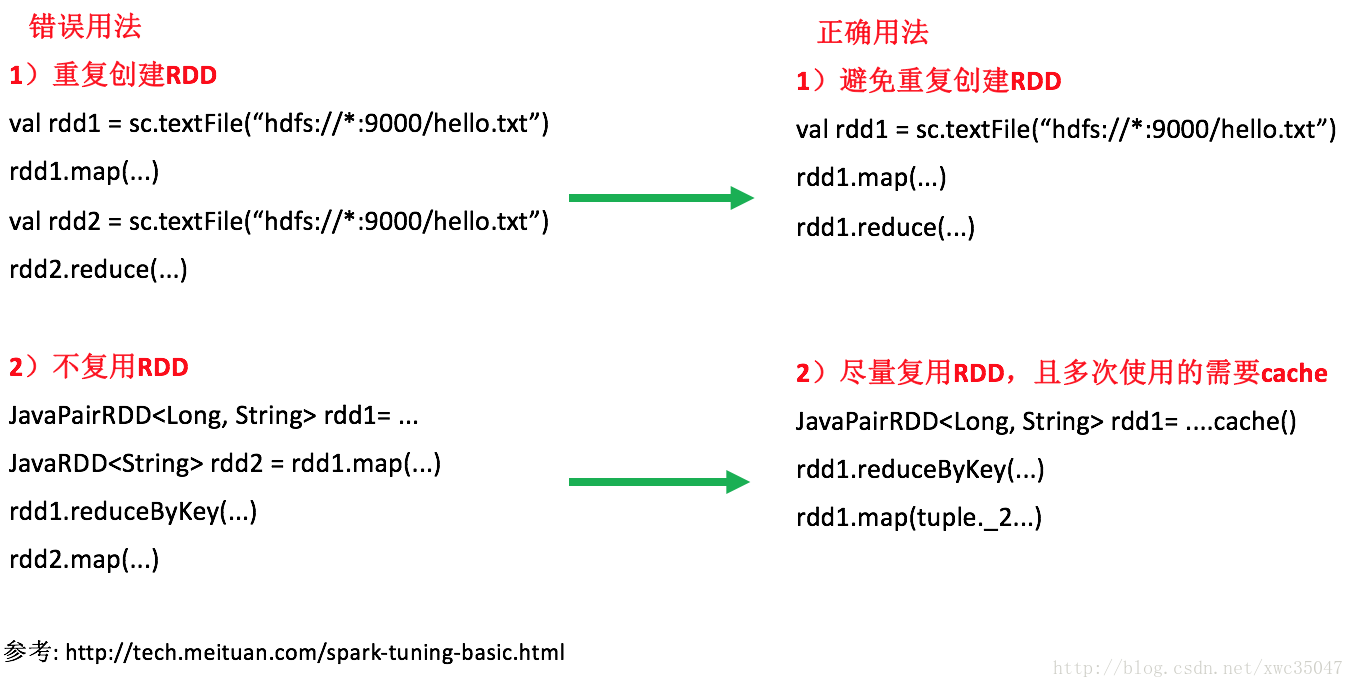
10)Spark代碼優化——RDD複用
11)Spark代碼優化——選擇合適算子

12) Spark代碼優化——shuffle算子並行度調優
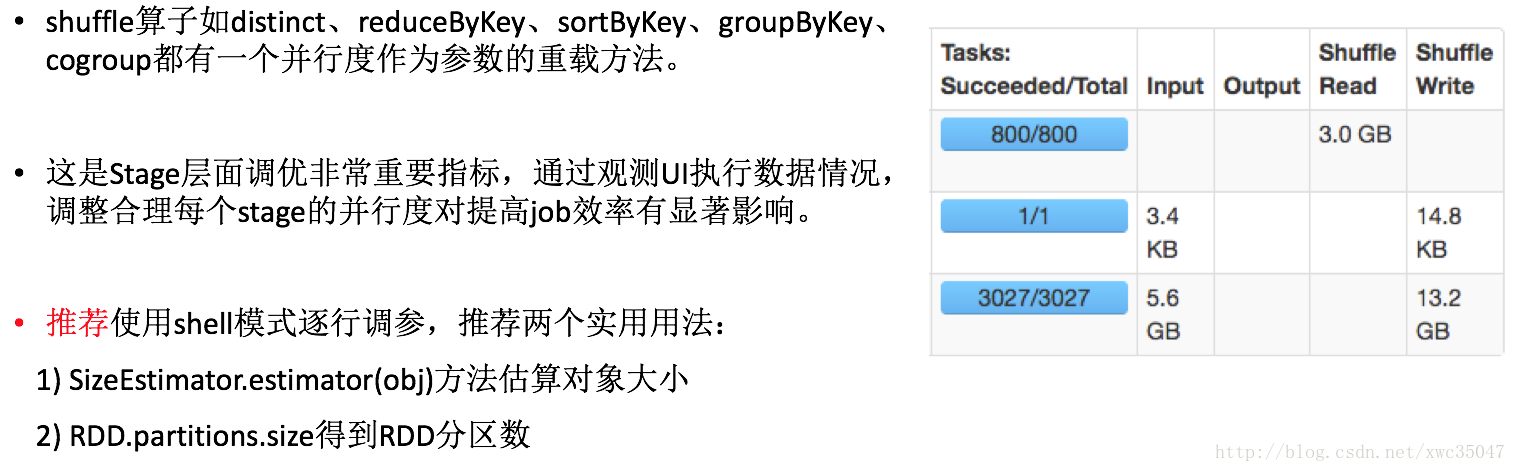
13)Spark代碼優化——數據傾斜

14)Spark代碼優化——優化數據結構

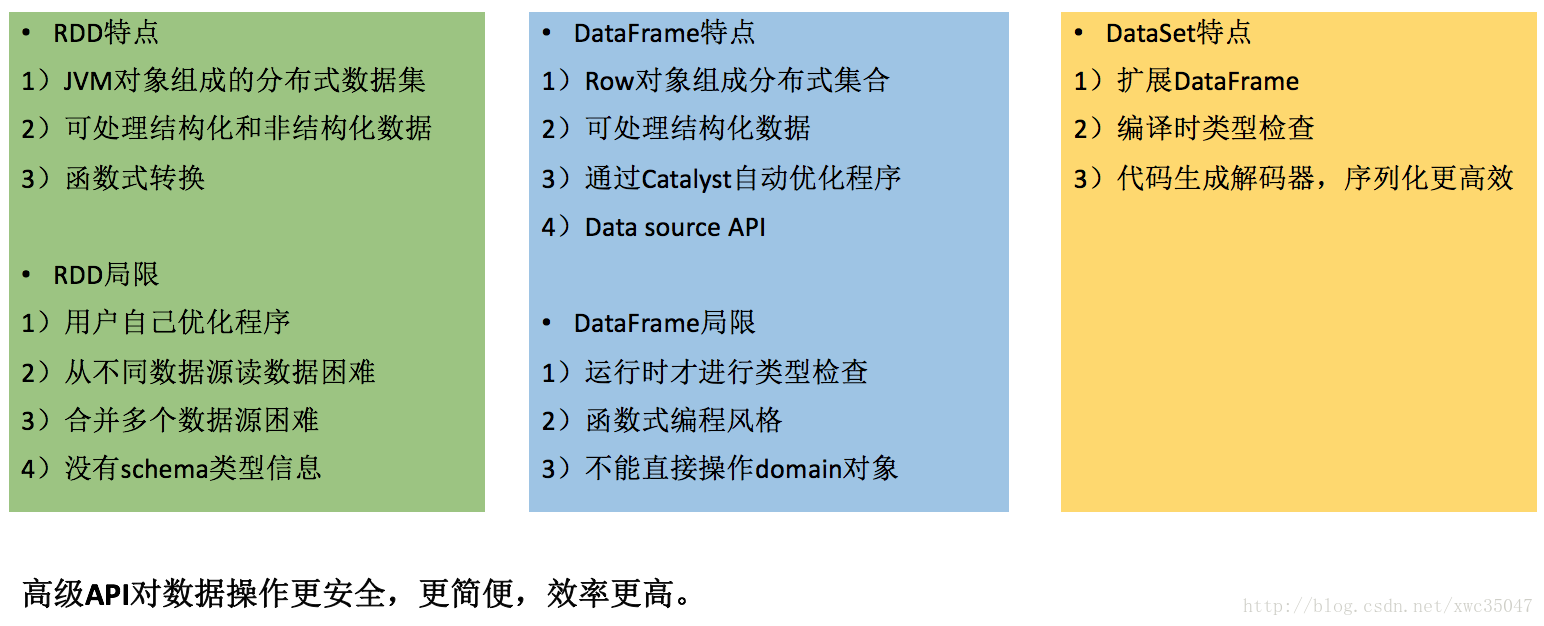
15)Spark代碼優化——使用DateSet API
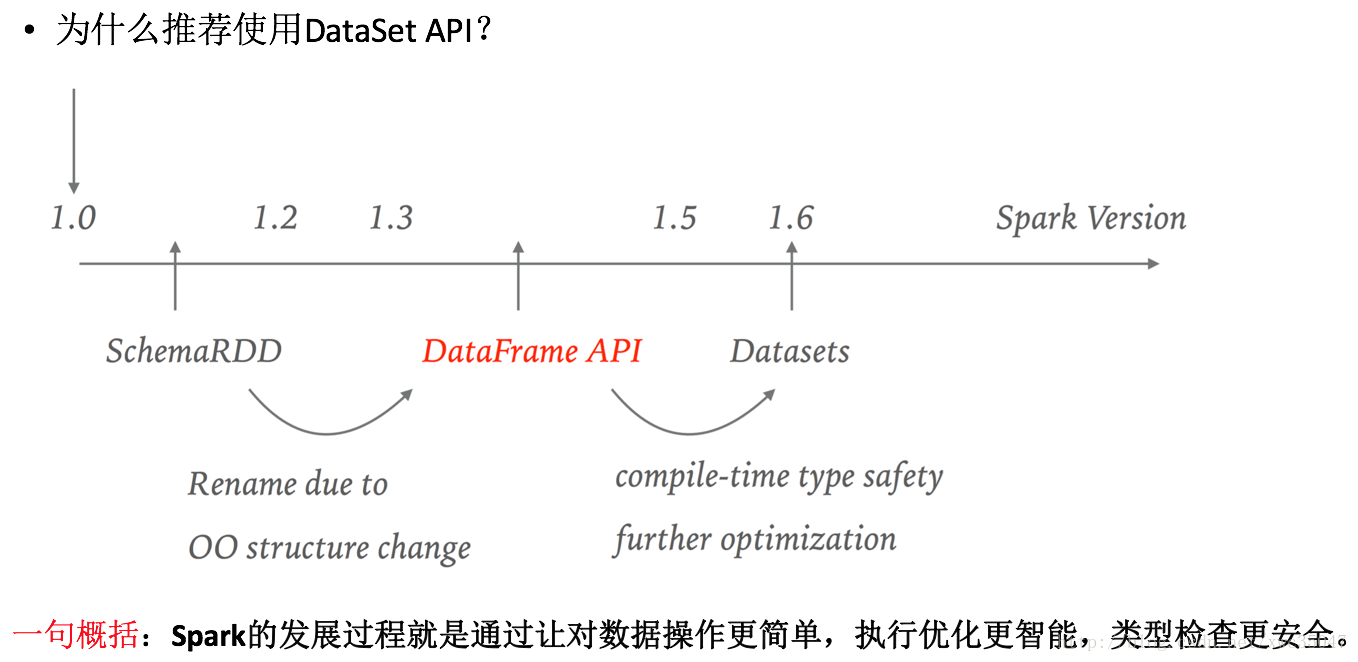
16)Spark代碼優化——使用DateSet API
17) 目前Spark的瓶頸——內存

18) 目前Spark的瓶頸——內存

3、總結
調優參數雖名目多樣,但最終目的是提高CPU利用率,降低帶寬IO,提高緩存命中率,減少數據落盤。
不同數據量的最優參數都不相同,調優目的是讓參數適應數據的量級以最大程度利用資源,經調優發現並不是所有參數有效,有的參數的效果也不明顯,最後折中推薦如下調優參數以適應絕大多數SQL情況,個別SQL需要用戶單獨調參優化。(以下參數主要用於Spark Thriftserver,僅供參考)
| 參數 | 含義 | 默認值 | 調優值 |
|---|---|---|---|
| spark.sql.shuffle.partitions | 併發度 | 200 | 800 |
| spark.executor.overhead.memory | executor堆外內存 | 512m | 1.5g |
| spark.executor.memory | executor堆內存 | 1g | 9g |
| spark.executor.cores | executor擁有的core數 | 1 | 3 |
| spark.locality.wait.process | 進程內等待時間 | 3 | 3 |
| spark.locality.wait.node | 節點內等待時間 | 3 | 8 |
| spark.locality.wait.rack | 機架內等待時間 | 3 | 5 |
| spark.rpc.askTimeout | rpc超時時間 | 10 | 1000 |
| spark.sql.autoBroadcastJoinThreshold | 小表需要broadcast的大小閾值 | 10485760 | 33554432 |
| spark.sql.hive.convertCTAS | 創建表是否使用默認格式 | false | true |
| spark.sql.sources.default | 默認數據源格式 | parquet | orc |
| spark.sql.files.openCostInBytes | 小文件合併閾值 | 4194304 | 6291456 |
| spark.sql.orc.filterPushdown | orc格式表是否謂詞下推 | false | true |
| spark.shuffle.sort.bypassMergeThreshold | shuffle read task閾值,小於該值則shuffle write過程不進行排序 | 200 | 600 |
| spark.shuffle.io.retryWait | 每次重試拉取數據的等待間隔 | 5 | 30 |
| spark.shuffle.io.maxRetries | 拉取數據重試次數 | 3 | 10 |
如果覺得文章有什麼值得討論的歡迎來討論,如果覺得文章不錯,也希望點個贊作爲對我的支持。