筆者最近迷上了數據挖掘和機器學習,要做數據分析首先得有數據才行。對於我等平民來說,最廉價的獲取數據的方法,應該是用爬蟲在網絡上爬取數據了。本文記錄一下筆者爬取天貓某商品的全過程,淘寶上面的店鋪也是類似的做法,不贅述。主要是分析頁面以及用Python實現簡單方便的抓取。
筆者使用的工具如下
Python 3——極其方便的編程語言。選擇3.x的版本是因爲3.x對中文處理更加友好。
Pandas——Python的一個附加庫,用於數據整理。
IE 11——分析頁面請求過程(其他類似的流量監控工具亦可)。
剩下的還有requests,re,這些都是Python自帶的庫。
實例頁面(美的某熱水器):http://detail.tmall.com/item.htm?id=41464129793
評論在哪裏?
要抓取評論數據,首先得找到評論究竟在哪裏。打開上述網址,然後查看源代碼,發現裏面並沒有評論內容!那麼,評論數據究竟在哪裏呢?原來天貓使用了ajax加密,它會從另外的頁面中讀取評論數據。
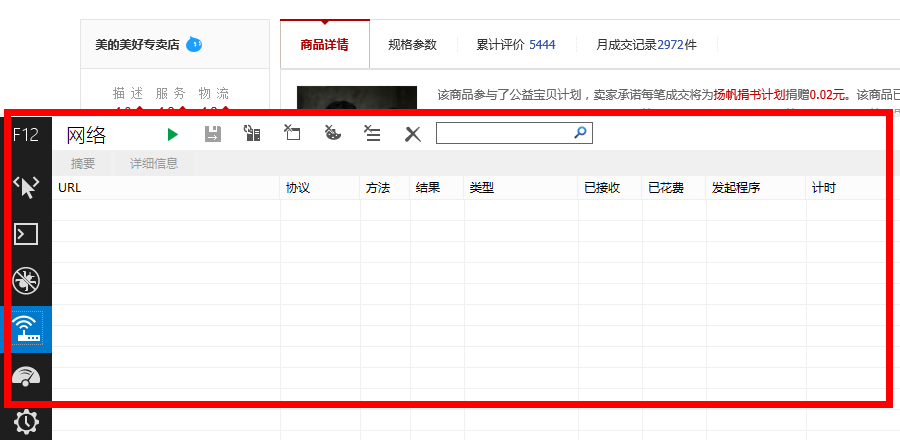
這時候IE 11就發揮作用了(當然你也可以使用其他的流量監控工具),使用前,先打開上述網址,待頁面打開後,清除一下IE 11的緩存、歷史文件等,然後按F12,會出現如下界面
![F12.png]()
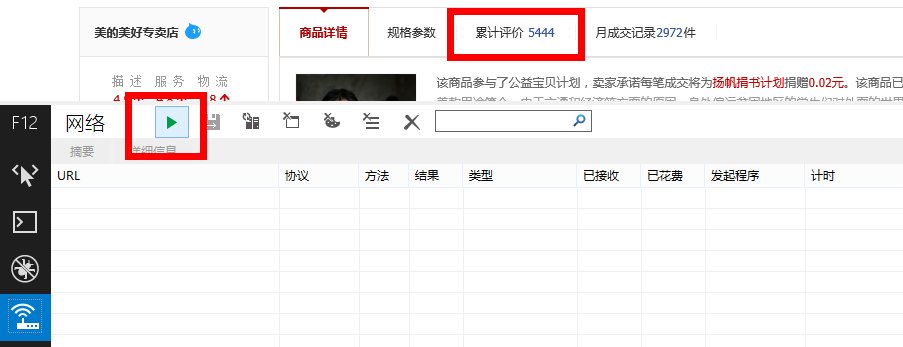
這時候點擊綠色的三角形按鈕,啓動網絡流量捕獲(或者直接按F5),然後點擊天貓頁面中的“累計評價”:
![捕獲.png]()
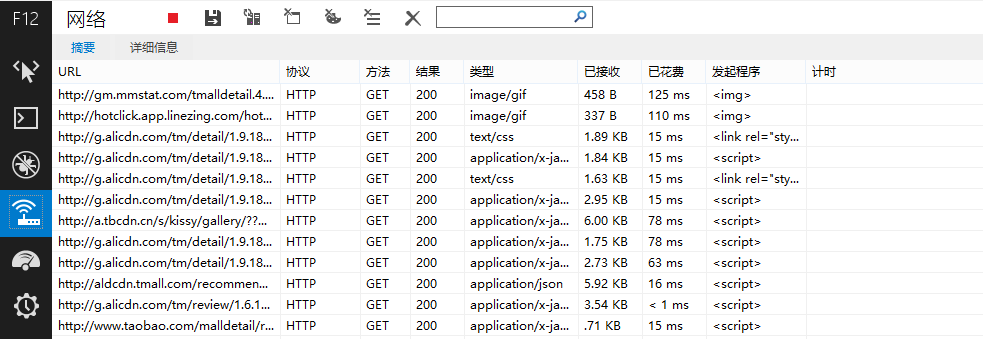
出現如下結果
![捕獲結果.png]()
在URL下面出現很多網址,而評論數據正隱藏在其中!我們主要留意類型爲“text/html”或者“application/json”的網址,經過測試發現,天貓的評論在下面這個網址之中
http://rate.tmall.com/list_detail_rate.htm?itemId=41464129793&spuId=296980116&sellerId=1652490016&order=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=166UW5TcyMNYQwiAiwVQX1EeUR5RH5Cd0xiNGI%3D%7CUm5Ockt1SHxBe0B0SXNOdCI%3D%7CU2xMHDJxPk82UjVOI1h2VngRd1snQSJEI107F2gFfgRlAmRKakQYeR9zFGoQPmg%2B%7CVGhXd1llXGJfa1ZsV2NeZFljVGlLdUt2TXFOc0tyT3pHe0Z6QHlXAQ%3D%3D%7CVWldfS0SMgo3FysUNBonHyMdNwI4HStHNkVrPWs%3D%7CVmhIGCIWNgsrFykQJAQ6DzQAIBwiGSICOAM2FioULxQ0DjEEUgQ%3D%7CV25OHjAePgA0DCwQKRYsDDgHPAdRBw%3D%3D%7CWGFBET8RMQ04ACAcJR0iAjYDNwtdCw%3D%3D%7CWWBAED5%2BKmIZcBZ6MUwxSmREfUl2VmpSbVR0SHVLcU4YTg%3D%3D%7CWmFBET9aIgwsECoKNxcrFysSL3kv%7CW2BAED5bIw0tESQEOBgkGCEfI3Uj%7CXGVFFTsVNQw2AiIeJxMoCDQIMwg9az0%3D%7CXWZGFjhdJQsrECgINhYqFiwRL3kv%7CXmdHFzkXNws3DS0RLxciAj4BPAY%2BaD4%3D%7CX2ZGFjgWNgo1ASEdIxsjAz8ANQE1YzU%3D%7CQHtbCyVAOBY2Aj4eIwM%2FAToONGI0%7CQXhYCCYIKBMqFzcLMwY%2FHyMdKRItey0%3D%7CQntbCyULKxQgGDgEPQg8HCAZIxoveS8%3D%7CQ3paCiQKKhYoFDQIMggwEC8SJh8idCI%3D%7CRH1dDSMNLRIrFTUJMw82FikWKxUueC4%3D%7CRX5eDiAOLhItEzMOLhIuFy4VKH4o%7CRn5eDiAOLn5GeEdnW2VeYjQUKQknCSkQKRIrFyN1Iw%3D%3D%7CR35Dfl5jQ3xcYFllRXtDeVlgQHxBYVV1QGBfZUV6QWFZeUZ%2FX2FBfl5hXX1AYEF9XXxDY0J8XGBbe0IU&isg=B2E8ACFC7C2F2CB185668041148A7DAA&_ksTS=1430908138129_1993&callback=jsonp1994
是不是感覺長到暈了?不要緊,只需要稍加分析,就發現可以精簡爲以下部分
http://rate.tmall.com/list_detail_rate.htm?itemId=41464129793&sellerId=1652490016¤tPage=1
我們發現天貓還是很慷慨的,評論頁面的地址是很有規律的(像京東就完全沒規律了,隨機生成。),其中itemId是商品id,sellerid是賣家id,currentPage是頁面號。
怎麼爬取?
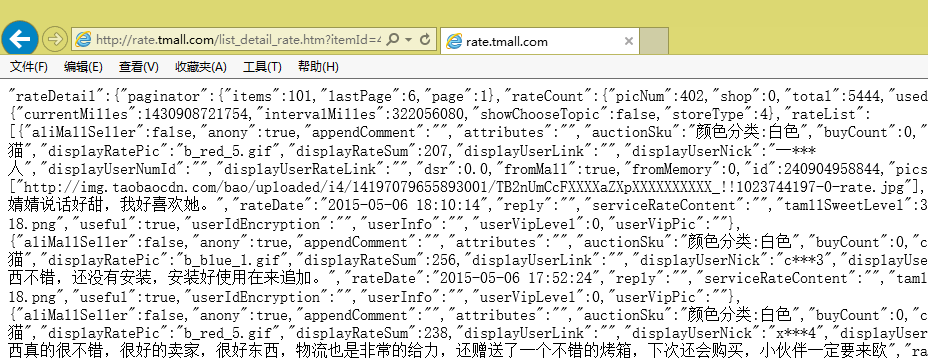
費了一番周折,終於找到評論在哪裏了,接下來是爬取,怎麼爬取呢?首先分析一下頁面規律。
![頁面格式.png]()
我們發現頁面數據是很規範的,事實上,它是一種被稱爲JSON的輕量級數據交換格式(大家可以搜索JSON),但它又不是通常的JSON,事實上,頁面中的方括號[]裏邊的內容,纔是一個正確的JSON規範文本。
下面開始我們的爬取,我使用Python中的requests庫進行抓取,在Python中依次輸入:
1
2
3
|
import requests as rq
url='http://rate.tmall.com/list_detail_rate.htm?itemId=41464129793&sellerId=1652490016¤tPage=1'
myweb = rq.get(url)
|
現在該頁面的內容已經保存在myweb變量中了,我們可以用myweb.text查看文本內容。
接下來就是隻保留方括號裏邊的部分,這需要用到正則表達式了,涉及到的模塊有re。
1
2
|
import re
myjson = re.findall('\"rateList\":(\[.*?\])\,\"tags\"',myweb.text)[0]
|
呃,這句代碼什麼意思?懂Python的讀者大概都能讀懂它,不懂的話,請先閱讀一下相關的正則表達式的教程。上面的意思是,在文本中查找下面標籤
"rateList":[...],"tags"
找到後保留方括號及方括號裏邊的內容。爲什麼不直接以方括號爲標籤呢,而要多加幾個字符?這是爲了防止用戶評論中出現方括號而導致抓取出錯。
現在抓取到了myjson,這是一個標準的JSON文本了,怎麼讀取JSON?也簡單,直接用Pandas吧。這是Python中強大的數據分析工具,用它可以直接讀取JSON。當然,如果僅僅是爲了讀取JSON,完全沒必要用它,但是我們還要考慮把同一個商品的每個評論頁的數據都合併成一個表,並進行預處理等,這時候Pandas就非常方便了。
1
2
|
import pandas as pd
mytable = pd.read_json(myjson)
|
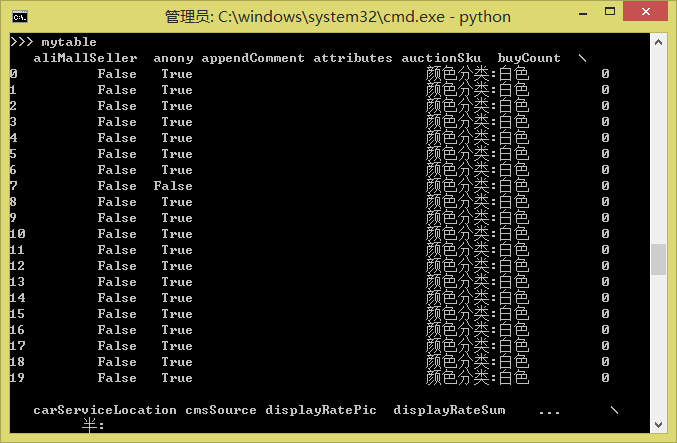
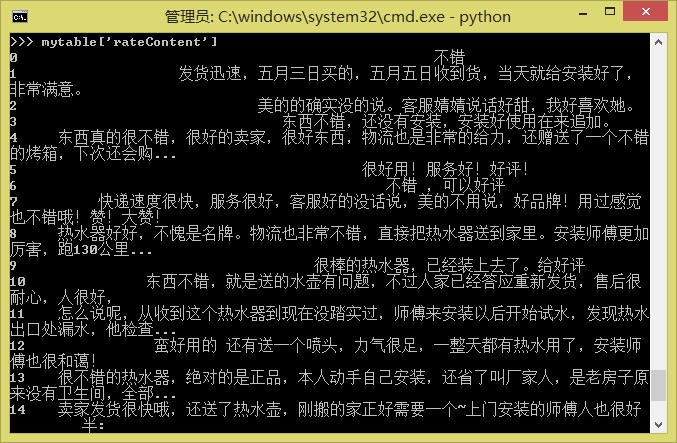
現在mytable就是一個規範的Pandas的DataFrame了:
![mytable1.png]()
![mytable2.png]()
如果有兩個表mytable1和mytable2需要合併,則只要
1
|
pd.concat([mytable1, mytable2], ignore_index=True)
|
等等。更多的操作請參考Pandas的教程。
最後,要把評論保存爲txt或者Excel(由於存在中文編碼問題,保存爲txt可能出錯,因此不妨保存爲Excel,Pandas也能夠讀取Excel文件)
1
2
|
mytable.to_csv('mytable.txt')
mytable.to_excel('mytable.xls')
|
一點點結論
讓我們看看一共用了幾行代碼?
1
2
3
4
5
6
7
8
9
|
import requests as rq
import re
import pandas as pd
url='http://rate.tmall.com/list_detail_rate.htm?itemId=41464129793&sellerId=1652490016¤tPage=1'
myweb = rq.get(url)
myjson = re.findall('\"rateList\":(\[.*?\])\,\"tags\"',myweb.text)[0]
mytable = pd.read_json(myjson)
mytable.to_csv('mytable.txt')
mytable.to_excel('mytable.xls')
|
九行!十行不到,我們就完成了一個簡單的爬蟲程序,並且能夠爬取到天貓上的數據了!是不是躍躍欲試了?
當然,這只是一個簡單的示例文件。要想實用,還要加入一些功能,比如找出評論共有多少頁,逐頁讀取評論。另外,批量獲取商品id也是要實現的。這些要靠大家自由發揮了,都不是困難的問題,本文只希望起到拋磚引玉的作用,爲需要爬取數據的讀者提供一個最簡單的指引。
其中最困難的問題,應該是大量採集之後,有可能被天貓本身的系統發現,然後要你輸入驗證碼才能繼續訪問的情況,這就複雜得多了,解決的方案有使用代理、使用更大的採集時間間隔或者直接OCR系統識別驗證碼等等,筆者也沒有很好的解決辦法。
轉載請包括本文地址:http://spaces.ac.cn/archives/3298/如果您覺得本文還不錯,歡迎點擊下面的按鈕對博主進行打賞。打賞並非要從中獲得收益,而是希望知道有多少人曾在科學空間駐足。當然,如果你無視它,也不會影響你的閱讀。再次表示歡迎和感謝!





May 23rd, 2015
1好厲害啊!好久沒來了,網站又更新了這麼多的內容,佩服佩服,嘻嘻
October 26th, 2015
2看了你的文章,試着找到了天貓的評價頁面,但是希望能多一點知識出來
請問大概是哪方面的知識呢?
就是一開始找評論的方法,化簡加查找,受益良多,對於初學來說。現在嘗試找360手機助手PC端的評論,可惜隱藏太深。
360手機助手PC端的評論?是在哪個頁面嗎?
zhushou.360.cn,我後面發現應該先用手機抓包,抓是抓出來了,但是我需要的漢字內容變成“\u5ba4\u53cb\u67d0\u7c73\u624b\u673a\u4e”這種,這應該是需要轉碼吧,卡在這裏了
http://intf.baike.360.cn/index.php?name=大話西遊(手遊年輕派)+Android_com.netease.dhxy.qihoo&c=message&a=getmessage&start=0&count=10
以上就是地址了,好像不能精簡了~可以調整的參數是start=
“\u5ba4\u53cb\u67d0\u7c73\u624b\u673a”這種是UTF-8編碼,已經是正確的格式了,在python中,用print輸出就可以看到中文。如
print('\u5ba4\u53cb\u67d0\u7c73\u624b\u673a')
輸出“室友某米手機”。
恩,今天上午就清楚這種了,首先你在電腦上抓的是百科的,不能實際對應正確日期,而且內容也是百科上的,實際地址是手機抓包出來的,可以化簡爲http://comment.mobilem.360.cn/comment/getComments?baike=77208&start=(*)&count=10,參數是START,用ID號表示軟件應用,至於\··之類的,的確,是unicode編碼的,我上午想或許這個是一種密碼,一百度還是找出來了,現在已經解決了,發現之前思路都是正確的,雖然結果如此的簡單,但是過程還是比較難搞得,特別是沒有人指點的情況下。
謝謝你有幫我看
今天遇到新的問題,http://detail.1688.com/offer/1180547851.html?spm=0.0.0.0.QqQKj4這個網站的用戶是匿名的,請問一下如何採集到用戶的數據,用之前的方法可以採集到評論,但是買家的信息無法得到,二者之間貌似毫無關聯
你要採集買家信息?指的是哪些信息?具體分析某個買家的購買行爲?
買家信息一般不公開的,但是通過概率論或許可以做一點工作。
具體來說是買家信息,也就是通過匿名如“韓**”等名稱找到買家ID號,然後再進行採集,抓包出來的結果如"countBuyerOrder":1,"mix":false,"buyerName":"韓***","unit":"件","price":["35"],"裏面的buyerName就是匿名了,無法得知這個匿名後面的含義,也就是買家信息,的確不公開的,概率論倒是不清楚是否可以採集,我網上找的最有分析性的文章爲這個http://bbs.csdn.net/topics/390169622,所以只能粗略瞭解
你的目的是?如果是爲了採集到id,然後做進一步的用途,那我就無能爲力了;但是如果你只是想分析某個用戶的購買行爲,那麼基於概率論的思想,還是可以做一點事情的。
恩,只是單純研究罷了,如果要繼續研究下去,那需要的知識就比較複雜了,打算換個新的網址去研究。
yiyiyi你研究的真不錯,最近也是需要採集點數據,瀏覽到你的回覆,不知你現在還對採集有研究不,請教點
比較少了,有興趣還可以探討
現在淘寶封了不少,要想採集到ID和用戶,不知如何下手。迷惑中
March 27th, 2016
3爲什麼我出現了這樣的問題:Traceback (most recent call last):
File "C:\Users\lenovo\Desktop\example.py", line 6, in
myjson = re.findall('\"rateList\":(
IndexError: list index out of range
請問下這問題你解決了麼?
我也是這個問題,不知哪裏的問題
April 22nd, 2016
4太感謝你了,我正愁怎麼抓取商品評價呢,謝謝你的文章。
May 24th, 2016
5我覺得對於開發者來說,能腳本化編寫爬蟲是一件挺開心的事情( ̄▽ ̄)"。所以我們團隊開發了一個專門讓開發者用簡單的幾行 javascript 就能在雲上編寫和運行復雜爬蟲的系統,叫神箭手雲爬蟲開發平臺: http://www.shenjianshou.cn 。歡迎同行們來試用拍磚,盡情給俺們提意見。有想法的可以加羣討論: 342953471
好像是很吸引人的項目。其實python的requests做爬蟲已經足夠人性化了,但是驗證碼識別、代理等還需要自己解決。看介紹你們能解決這兩個問題?
July 5th, 2016
6myjson = re.findall('\"rateList\":(
IndexError: list index out of range
請問這個提示超出範圍該怎麼改?謝謝
"searchinfo":"","tags":""},
把tags 改成 searchinfo
July 18th, 2016
7博主好厲害,贊贊贊
我也分享個
淘寶商品信息及評價採集爬蟲(按商品搜索關鍵字)
http://www.shenjianshou.cn/index.php?r=market/configDetail&pid=119