




對於innodb索引,採用是的B+tree的數據結構,及索引和數據都存儲在一個文件中*.db;而不像MYISAM索引和數據是分開存儲的.
舉例說明,下面是students表,id是主鍵,name上有輔助索引,有6行數據記錄。
一級索引(聚簇索引)
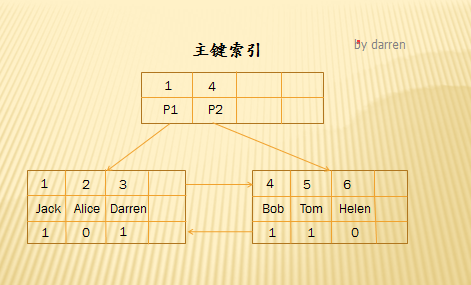
上圖是InnoDB主鍵索引的B+tree,葉節點包含了完整的數據記錄,像這種索引叫做聚集索引。因爲InnoDB的數據文件本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有),如果沒有顯式指定,則MySQL會優先自動選擇一個可以唯一標識數據記錄的列作爲主鍵,比如唯一索引列,如果不存在這種列,則MySQL自動爲InnoDB表生成一個隱含字段作爲主鍵,長度爲6個字節,類型爲longint。
二級索引(非聚簇索引)
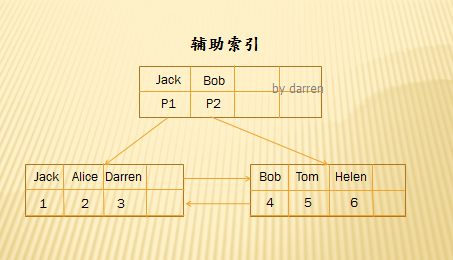
對於secondary index,非葉子結點保存的是索引值,比如上面的name字段。葉子結點保存的不再是數據記錄了,而是主鍵值。
innodb索引總結
輔助索引需要搜索兩遍索引:
第一:檢索輔助索引獲得主鍵值
第二:用主鍵值到主鍵索引中檢索獲得記錄
爲什麼Innodb表需要主鍵?
1)innodb表數據文件都是基於主鍵索引組織的,沒有主鍵,mysql會想辦法給我搞定,所以主鍵必須要有;2)基於主鍵查詢效率高;
3)其他類型索引都要引用主鍵索引;
爲什麼不建議Innodb表主鍵設置過長?
因爲輔助索引都保存引用主鍵索引,過長的主鍵索引使輔助索引變得過大;
innodb對B-TREE的改進
在上面的例子中:將下面數字插入到一棵5階B-Tree中:[3,14,7,1,8,5,11,17,13,6,23,12,20,26,4,16,18,24,25,19]
插入這些無序數據一共經歷了6次分裂,對於磁盤索引文件而言,每次分裂都是很昂貴的操作;
如果將以上數據排好序,再次插入是不是效果會好,我試驗了下,雖然每次都是插入到最右結點,涉及遷移數據量會少,但是分裂的次數依然挺多,需要7次分裂。
每次分裂都是按照50%進行,這樣存在明顯的缺點就是導致索引頁面的空間利用率在50%左右;而且對於遞增插入效率也不好,平均每兩次插入,最右結點就得進行一次分裂。那Innodb是如何進行改進的呢?
Innodb其實只是針對遞增/遞減情況進行了改進優化,不再採用50%的分裂策略,而是使用下面的分裂策略:
對於遞增/遞減索引插入操作:1、插入新元素,判斷葉子結點空間是否足夠,如果足夠,直接插入2、如果葉子結點空間滿了,判斷父結點空間是否足夠,如果足夠,將該新元素插入到父結點中;如果父結點空間滿了,則進行分裂。比如下面一棵5階B+Tree:
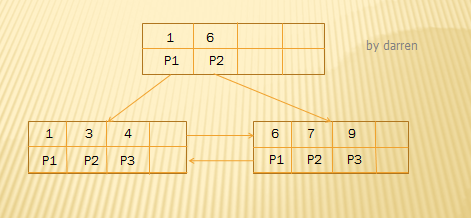
現在連續插入10,11,14,15,17,採用優化後分裂策略的分步圖例如下:
【第一步】:插入10
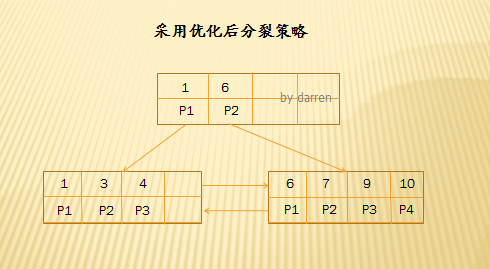
由於最右結點還有空間,直接插入即可。
【第二步】:插入11
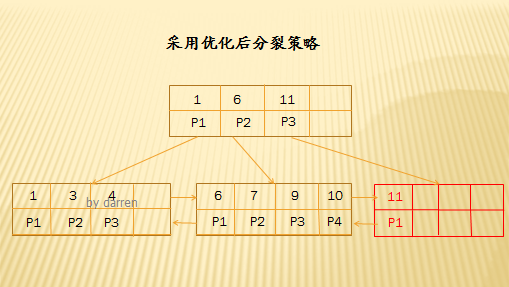
插入11時,由於最右結點空間已滿,如果使用50%分裂策略,則需要分裂操作了,但是使用優化後的分裂策略,當該結點空間已滿,還要判斷該結點的父結點是否滿了,如果父結點還有空間,那麼插入到父結點中,所以11插入到父結點中了,同時形成一個子結點。
【第二步】:插入14,15,17
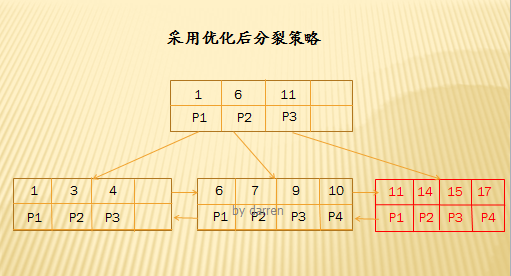
優化後的分裂策略僅僅針對遞增/遞減情況,顯著的減少了分裂次數並且大大提高了索引頁面空間的利用率。
如果是隨機插入,可能會引起更高代價的分裂概率。所以InnoDB存儲引擎會爲每個索引頁維護一個上次插入的位置變量,以及上次插入是遞增/遞減的標識。InnoDB能夠根據這些信息判斷新插入數據是否滿足遞增/遞減條件,若滿足,則採用改進後的分裂策略;若不滿足,則進行50%的分裂策略。
爲什麼建議InnoDB表主鍵是單調遞增?
如果InnoDB表主鍵是單調遞增的,可以使用改進後的B+tree分裂策略,顯著減少B-Tree分裂次數和數據遷移,從而提高數據插入效率。不僅如此,它還大大提高索引頁空間利用率。
參考文章:
http://database.51cto.com/art/201107/275030_1.html
http://www.2cto.com/database/201411/351106.html
https://www.cnblogs.com/mysql-dba/p/6689597.html