




談談B樹
1.前言:
動態查找樹主要有:二叉查找樹(Binary Search Tree),平衡二叉查找樹(Balanced Binary Search Tree),紅黑樹(Red-Black Tree ),B-tree/B+-tree/ B*-tree (B~Tree)。前三者是典型的二叉查找樹結構,其查找的時間複雜度O(log2N)與樹的深度相關,那麼降低樹的深度自然會提高查找效率。
但是咱們有面對這樣一個實際問題:就是大規模數據存儲中,實現索引查詢這樣一個實際背景下,樹節點存儲的元素數量是有限的(如果元素數量非常多的話,查找就退化成節點內部的線性查找了),這樣導致二叉查找樹結構由於樹的深度過大而造成磁盤I/O讀寫過於頻繁,進而導致查詢效率低下(爲什麼會出現這種情況,待會在外部存儲器-磁盤中有所解釋),那麼如何減少樹的深度(當然是不能減少查詢的數據量),一個基本的想法就是:採用多叉樹結構(由於樹節點元素數量是有限的,自然該節點的子樹數量也就是有限的)。
也 就是說,因爲磁盤的操作費時費資源,如果過於頻繁的多次查找勢必效率低下。那麼如何提高效率,即如何避免磁盤過於頻繁的多次查找呢?根據磁盤查找存取的次 數往往由樹的高度所決定,所以,只要我們通過某種較好的樹結構減少樹的結構儘量減少樹的高度,那麼是不是便能有效減少磁盤查找存取的次數呢?那這種有效的 樹結構是一種怎樣的樹呢?
這樣我們就提出了一個新的查找樹結構——多路查找樹。根據平衡二叉樹的啓發,自然就想到平衡多路查找樹結構,也就是這篇文章所要闡述的第一個主題B~tree,即B樹結構(後面,我們將看到,B樹的各種操作能使B樹保持較低的高度,從而達到有效避免磁盤過於頻繁的查找存取操作,從而有效提高查找效率)。
B-tree(B-tree樹即B樹,B即Balanced,平衡的意思)這棵神奇的樹是在Rudolf Bayer, Edward M. McCreight(1970)寫的一篇論文《Organization and Maintenance of Large Ordered Indices》中首次提出的(wikipedia中:http://en.wikipedia.org/wiki/B-tree,闡述了B-tree名字來源以及相關的開源地址)。
在開始介紹B~tree之前,先了解下相關的硬件知識,才能很好的瞭解爲什麼需要B~tree這種外存數據結構。
2.外存儲器—磁盤
計算機存儲設備一般分爲兩種:內存儲器(main memory)和外存儲器(external memory)。 內存存取速度快,但容量小,價格昂貴,而且不能長期保存數據(在不通電情況下數據會消失)。
外存儲器—磁盤是一種直接存取的存儲設備(DASD)。它是以存取時間變化不大爲特徵的。可以直接存取任何字符組,且容量大、速度較其它外存設備更快。
2.1磁盤的構造
磁盤是一個扁平的圓盤(與電唱機的唱片類似)。盤面上有許多稱爲磁道的圓圈,數據就記錄在這些磁道上。磁盤可以是單片的,也可以是由若干盤片組成的盤組,每一盤片上有兩個面。如下圖11.3中所示的6片盤組爲例,除去最頂端和最底端的外側面不存儲數據之外,一共有10個面可以用來保存信息。
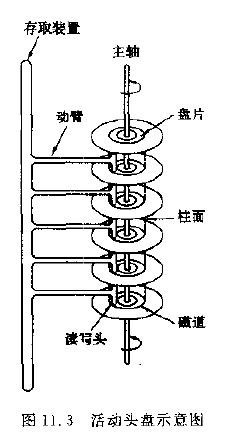
當磁盤驅動器執行讀/寫功能時。盤片裝在一個主軸上,並繞主軸高速旋轉,當磁道在讀/寫頭(又叫磁頭) 下通過時,就可以進行數據的讀 / 寫了。
一般磁盤分爲固定頭盤(磁頭固定)和活動頭盤。固定頭盤的每一個磁道上都有獨立的磁頭,它是固定不動的,專門負責這一磁道上數據的讀/寫。
活動頭盤 (如上圖)的磁頭是可移動的。每一個盤面上只有一個磁頭(磁頭是雙向的,因此正反盤面都能讀寫)。它可以從該面的一個磁道移動到另一個磁道。所有磁頭都裝在同一個動臂上,因此不同盤面上的所有磁頭都是同時移動的(行動整齊劃一)。當盤片繞主軸旋轉的時候,磁頭與旋轉的盤片形成一個圓柱體。各個盤面上半徑相同的磁道組成了一個圓柱面,我們稱爲柱面 。因此,柱面的個數也就是盤面上的磁道數。
2.2磁盤的讀/寫原理和效率
磁盤上數據必須用一個三維地址唯一標示:柱面號、盤面號、塊號(磁道上的盤塊)。
讀/寫磁盤上某一指定數據需要下面3個步驟:
(1) 首先移動臂根據柱面號使磁頭移動到所需要的柱面上,這一過程被稱爲定位或查找 。
(2) 如上圖11.3中所示的6盤組示意圖中,所有磁頭都定位到了10個盤面的10條磁道上(磁頭都是雙向的)。這時根據盤面號來確定指定盤面上的磁道。
(3) 盤面確定以後,盤片開始旋轉,將指定塊號的磁道段移動至磁頭下。
經過上面三個步驟,指定數據的存儲位置就被找到。這時就可以開始讀/寫操作了。
訪問某一具體信息,由3部分時間組成:
● 查找時間(seek time) Ts: 完成上述步驟(1)所需要的時間。這部分時間代價最高,最大可達到0.1s左右。
● 等待時間(latency time) Tl: 完成上述步驟(3)所需要的時間。由於盤片繞主軸旋轉速度很快,一般爲7200轉/分(電腦硬盤的性能指標之一, 家用的普通硬盤的轉速一般有5400rpm(筆記本)、7200rpm幾種)。因此一般旋轉一圈大約0.0083s。
● 傳輸時間(transmission time) Tt: 數據通過系統總線傳送到內存的時間,一般傳輸一個字節(byte)大概0.02us=2*10^(-8)s
磁盤讀取數據是以盤塊(block)爲基本單位的。位於同一盤塊中的所有數據都能被一次性全部讀取出來。而磁盤IO代價主要花費在查找時間Ts上。因此我們應該儘量將相關信息存放在同一盤塊,同一磁道中。或者至少放在同一柱面或相鄰柱面上,以求在讀/寫信息時儘量減少磁頭來回移動的次數,避免過多的查找時間Ts。
所以,在大規模數據存儲方面,大量數據存儲在外存磁盤中,而在外存磁盤中讀取/寫入塊(block)中某數據時,首先需要定位到磁盤中的某塊,如何有效地查找磁盤中的數據,需要一種合理高效的外存數據結構,就是下面所要重點闡述的B-tree結構,以及相關的變種結構:B+-tree結構和B*-tree結構。
3.B- 樹
3.1什麼是B-樹
具體講解之前,有一點,再次強調下:B-樹,即爲B樹。因爲B樹的原英文名稱爲B-tree,而國內很多人喜歡把B-tree譯作B-樹,其實,這是個非常不好的直譯,很容易讓人產生誤解。如人們可能會以爲B-樹是一種樹,而B樹又是一種一種樹。而事實上是,B-tree就是指的B樹。特此說明。
我 們知道,B 樹是爲了磁盤或其它存儲設備而設計的一種多叉(下面你會看到,相對於二叉,B樹每個內結點有多個分支,即多叉)平衡查找樹。與本blog之前介紹的紅黑樹 很相似,但在降低磁盤I/0操作方面要更好一些。許多數據庫系統都一般使用B樹或者B樹的各種變形結構,如下文即將要介紹的B+樹,B*樹來存儲信息。
B 樹與紅黑樹最大的不同在於,B樹的結點可以有許多子女,從幾個到幾千個。那爲什麼又說B樹與紅黑樹很相似呢?因爲與紅黑樹一樣,一棵含n個結點的B樹的高 度也爲O(lgn),但可能比一棵紅黑樹的高度小許多,應爲它的分支因子比較大。所以,B樹可以在O(logn)時間內,實現各種如插入 (insert),刪除(delete)等動態集合操作。
如 下圖所示,即是一棵B樹,一棵關鍵字爲英語中輔音字母的B樹,現在要從樹種查找字母R(包含n[x]個關鍵字的內結點x,x有n[x]+1]個子女(也就 是說,一個內結點x若含有n[x]個關鍵字,那麼x將含有n[x]+1個子女)。所有的葉結點都處於相同的深度,帶陰影的結點爲查找字母R時要檢查的結 點):
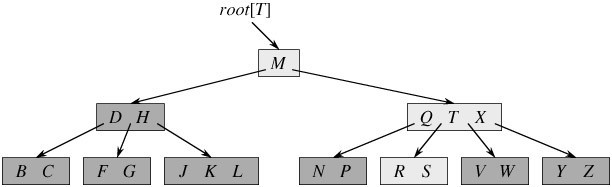
相信,從上圖你能輕易的看到,一個內結點x若含有n[x]個關鍵字,那麼x將含有n[x]+1個子女。如含有2個關鍵字D H的內結點有3個子女,而含有3個關鍵字Q T X的內結點有4個子女。
B樹的定義,從下文中,你將看到,或者是用階,或者是用度,如下段文字所述:
Unfortunately, the literature on B-trees is not uniform in its use of terms relating to B-Trees. (Folk & Zoellick 1992, p. 362) Bayer & McCreight (1972), Comer (1979), and others define the order of B-tree as the minimum number of keys in a non-root node. Folk & Zoellick (1992) points out that terminology is ambiguous because the maximum number of keys is not clear. An order 3 B-tree might hold a maximum of 6 keys or a maximum of 7 keys. (Knuth 1998,TAOCP p. 483) avoids the problem by defining the order to be maximum number of children (which is one more than the maximum number of keys).
from: http://en.wikipedia.org/wiki/Btree#Technical_description。
用階定義的B樹
B 樹又叫平衡多路查找樹。一棵m階的B 樹 (注:切勿簡單的認爲一棵m階的B樹是m叉樹,雖然存在四叉樹,八叉樹,KD樹,及vp/R樹/R*樹/R+樹/X樹/M樹/線段樹/希爾伯特R樹/優先R樹等空間劃分樹,但與B樹完全不等同)的特性如下:
-
樹中每個結點最多含有m個孩子(m>=2);
-
除根結點和葉子結點外,其它每個結點至少有[ceil(m / 2)]個孩子(其中ceil(x)是一個取上限的函數);
-
若根結點不是葉子結點,則至少有2個孩子(特殊情況:沒有孩子的根結點,即根結點爲葉子結點,整棵樹只有一個根節點);
-
所有葉子結點都出現在同一層,葉子結點不包含任何關鍵字信息(可以看做是外部接點或查詢失敗的接點,實際上這些結點不存在,指向這些結點的指針都爲null);(讀者反饋@冷嶽:這裏有錯,葉子節點只是沒有孩子和指向孩子的指針,這些節點也存在,也有元素。@JULY:其實,關鍵是把什麼當做葉子結點,因爲如紅黑樹中,每一個NULL指針即當做葉子結點,只是沒畫出來而已)。
-
每個非終端結點中包含有n個關鍵字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其中:
a) Ki (i=1...n)爲關鍵字,且關鍵字按順序升序排序K(i-1)< Ki。
b) Pi爲指向子樹根的接點,且指針P(i-1)指向子樹種所有結點的關鍵字均小於Ki,但都大於K(i-1)。
c) 關鍵字的個數n必須滿足: [ceil(m / 2)-1]<= n <= m-1。如下圖所示:

用度定義的B樹
針對上面的5點,再闡述下:B樹中每一個結點能包含的關鍵字(如之前上面的D H和Q T X)數有一個上界和下界。這個下界可以用一個稱作B樹的最小度數(算法導論中文版上譯作度數,最小度數即內節點中節點最小孩子數目)m(m>=2)表示。
-
每個非根的內結點至多有m個子女,每個非根的結點必須至少含有m-1個關鍵字,如果樹是非空的,則根結點至少包含一個關鍵字;
-
每個結點可包含至多2m-1個關鍵字。所以一個內結點至多可有2m個子女。如果一個結點恰好有2m-1個關鍵字,我們就說這個結點是滿的(而稍後介紹的B*樹作爲B樹的一種常用變形,B*樹中要求每個內結點至少爲2/3滿,而不是像這裏的B樹所要求的至少半滿);
-
當關鍵字數m=2(t=2的意思是,mmin=2,m可以>=2)時的B樹是最簡單的(有很多人會因此誤認爲B樹就是二叉查找樹,但二叉查找樹就是二叉查找樹,B樹就是B樹,B樹是一棵含有m(m>=2)個關鍵字的平衡多路查找樹),此時,每個內結點可能因此而含有2個、3個或4個子女,亦即一棵2-3-4樹,然而在實際中,通常採用大得多的t值。
B樹中的每個結點根據實際情況可以包含大量的關鍵字信息和分支(當然是不能超過磁盤塊的大小,根據磁盤驅動(disk drives)的不同,一般塊的大小在1k~4k左右);這樣樹的深度降低了,這就意味着查找一個元素只要很少結點從外存磁盤中讀入內存,很快訪問到要查 找的數據。如果你看完上面關於B樹定義的介紹,思維感覺不夠清晰,請繼續參閱下文第6小節、B樹的插入、刪除操作 部分。
3.2B樹的類型和節點定義
B樹的類型和節點定義如下圖所示:

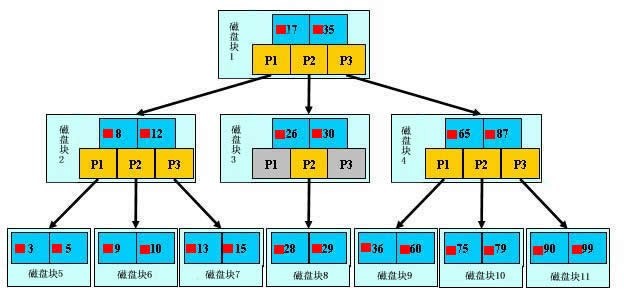
3.3文件查找的具體過程(涉及磁盤IO操作)
爲了簡單,這裏用少量數據構造一棵3叉樹的形式,實際應用中的B樹結點中關鍵字很多的。上面的圖中比如根結點,其中17表示一個磁盤文件的文件名;小紅方塊表示這個17文件內容在硬盤中的存儲位置;p1表示指向17左子樹的指針。
其結構可以簡單定義爲:
typedef struct {
/*文件數*/
int file_num;
/*文件名(key)*/
char * file_name[max_file_num];
/*指向子節點的指針*/
BTNode * BTptr[max_file_num+1];
/*文件在硬盤中的存儲位置*/
FILE_HARD_ADDR offset[max_file_num];
}BTNode;
假如每個盤塊可以正好存放一個B樹的結點(正好存放2個文件名)。那麼一個BTNODE結點就代表一個盤塊,而子樹指針就是存放另外一個盤塊的地址。
下面,咱們來模擬下查找文件29的過程:
-
根據根結點指針找到文件目錄的根磁盤塊1,將其中的信息導入內存。【磁盤IO操作 1次】
-
此時內存中有兩個文件名17、35和三個存儲其他磁盤頁面地址的數據。根據算法我們發現:17<29<35,因此我們找到指針p2。
-
根據p2指針,我們定位到磁盤塊3,並將其中的信息導入內存。【磁盤IO操作 2次】
-
此時內存中有兩個文件名26,30和三個存儲其他磁盤頁面地址的數據。根據算法我們發現:26<29<30,因此我們找到指針p2。
-
根據p2指針,我們定位到磁盤塊8,並將其中的信息導入內存。【磁盤IO操作 3次】
-
此時內存中有兩個文件名28,29。根據算法我們查找到文件名29,並定位了該文件內存的磁盤地址。
分析上面的過程,發現需要3次磁盤IO操作和3次內存查找操作。關於內存中的文件名查找,由於是一個有序表結構,可以利用折半查找提高效率。至於IO操作是影響整個B樹查找效率的決定因素。
當然,如果我們使用平衡二叉樹的磁盤存儲結構來進行查找,磁盤4次,最多5次,而且文件越多,B樹比平衡二叉樹所用的磁盤IO操作次數將越少,效率也越高。
3.4B樹的高度
根據上面的例子我們可以看出,對於輔存做IO讀的次數取決於B樹的高度。而B樹的高度由什麼決定的呢?
若 B樹某一非葉子節點包含N個關鍵字,則此非葉子節點含有N+1個孩子結點,而所有的葉子結點都在第I層。因爲根至少有兩個孩子,因此第2層至少有兩個結 點。除根和葉子外,其它結點至少有┌m/2┐個孩子,因此在第3層至少有2*┌m/2┐個結點,在第4層至少有2*(┌m/2┐^2)個結點,在第I層至 少有2*(┌m/2┐^(l-2) )個結點,於是有: N+1 ≥ 2*┌m/2┐I-2 考慮第L層的結點個數爲N+1,那麼2*(┌m/2┐^(l-2))≤N+1,也就是L層的最少結點數剛好達到N+1個 即: I≤ log┌m/2┐((N+1)/2 )+2 所以,當B樹包含N個關鍵關鍵字時,B樹的最大高度爲l-1(因爲計算B樹高度時,葉結點所在層不計算在內) 即:log┌m/2┐((N+1)/2 )+1。 這個B樹的高度公式從側面顯示了B樹的查找效率是相當高的。
4.B+-tree
B+-tree:是應文件系統所需而產生的一種B-tree的變形樹。
一棵m階的B+樹和m階的B樹的異同點在於:
1.有n棵子樹的結點中含有n-1 個關鍵字; (與B 樹n棵子樹有n-1個關鍵字 保持一致,參照:http://en.wikipedia.org/wiki/B%2B_tree#Overview)
2.所有的葉子結點中包含了全部關鍵字的信息,及指向含有這些關鍵字記錄的指針,且葉子結點本身依關鍵字的大小自小而大的順序鏈接。 (而B 樹的葉子節點並沒有包括全部需要查找的信息)
3.所有的非終端結點可以看成是索引部分,結點中僅含有其子樹根結點中最大(或最小)關鍵字。 (而B 樹的非終節點也包含需要查找的有效信息)
a) 爲什麼說B+-tree比B 樹更適合實際應用中操作系統的文件索引和數據庫索引?
1) B+-tree的磁盤讀寫代價更低
B+-tree的內部結點並沒有指向關鍵字具體信息的指針。因此其內部結點相對B 樹更小。如果把所有同一內部結點的關鍵字存放在同一盤塊中,那麼盤塊所能容納的關鍵字數量也越多。一次性讀入內存中的需要查找的關鍵字也就越多。相對來說IO讀寫次數也就降低了。
舉個例子,假設磁盤中的一個盤塊容納16bytes,而一個關鍵字2bytes,一個關鍵字具體信息指針2bytes。一棵9階B-tree(一個結點最多8個關鍵字)的內部結點需要2個盤快。而B+ 樹內部結點只需要1個盤快。當需要把內部結點讀入內存中的時候,B 樹就比B+ 樹多一次盤塊查找時間(在磁盤中就是盤片旋轉的時間)。
2) B+-tree的查詢效率更加穩定
由於非終結點並不是最終指向文件內容的結點,而只是葉子結點中關鍵字的索引。所以任何關鍵字的查找必須走一條從根結點到葉子結點的路。所有關鍵字查詢的路徑長度相同,導致每一個數據的查詢效率相當。
讀者點評
本 文評論下第149樓,fanyy1991針對上文所說的兩點,道:個人覺得這兩個原因都不是主要原因。數據庫索引採用B+樹的主要原因是 B樹在提高了磁盤IO性能的同時並沒有解決元素遍歷的效率低下的問題。正是爲了解決這個問題,B+樹應運而生。B+樹只要遍歷葉子節點就可以實現整棵樹的 遍歷。而且在數據庫中基於範圍的查詢是非常頻繁的,而B樹不支持這樣的操作(或者說效率太低)。
b) B+-tree的應用: VSAM(虛擬存儲存取法)文件(來源論文 the ubiquitous Btree 作者:D COMER - 1979 )
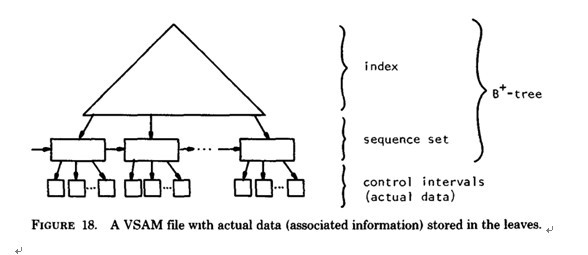
5.B*-tree
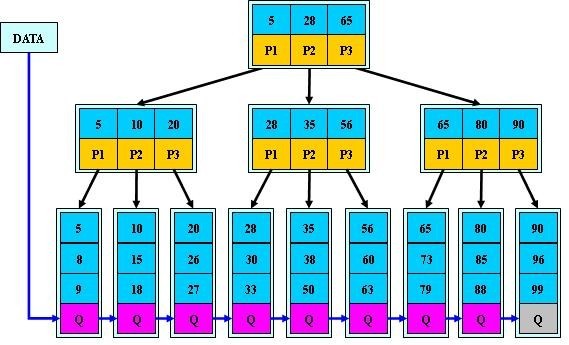
B*-tree是B+-tree的變體,在B+樹的基礎上(所有的葉子結點中包含了全部關鍵字的信息,及指向含有這些關鍵字記錄的指針),B*樹中非根和非葉子結點再增加指向兄弟的指針;B*樹定義了非葉子結點關鍵字個數至少爲(2/3)*M,即塊的最低使用率爲2/3(代替B+樹的1/2)。給出了一個簡單實例,如下圖所示:
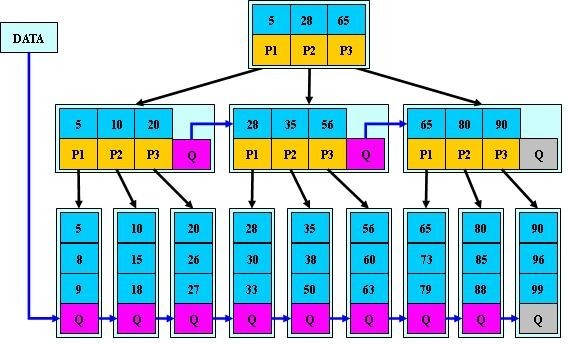
B+樹的分裂:當一個結點滿時,分配一個新的結點,並將原結點中1/2的數據複製到新結點,最後在父結點中增加新結點的指針;B+樹的分裂隻影響原結點和父結點,而不會影響兄弟結點,所以它不需要指向兄弟的指針。
B*樹的分裂:當一個結點滿時,如果它的下一個兄弟結點未滿,那麼將一部分數據移到兄弟結點中,再在原結點插入關鍵字,最後修改父結點中兄弟結點的關鍵字(因爲兄弟結點的關鍵字範圍改變了);如果兄弟也滿了,則在原結點與兄弟結點之間增加新結點,並各複製1/3的數據到新結點,最後在父結點增加新結點的指針。
所以,B*樹分配新結點的概率比B+樹要低,空間使用率更高;
原文鏈接:http://blog.csdn.net/v_JULY_v/article/details/6530142
備註:上面作者介紹的關於數據庫中的B樹 個人感覺還是可以的,通俗易通搭配着圖形的介紹,呵呵你也試試吧(建議有點數據結構的基礎知識再看本文)