




首先介紹ringbuffer。我對Disruptor的最初印象就是ringbuffer。但是後來我意識到儘管ringbuffer是整個模式(Disruptor)的核心,但是Disruptor對ringbuffer的訪問控制策略纔是真正的關鍵點所在。
最近,我們開源了LMAX Disruptor, 它是我們的交易系統吞吐量快(LMAX是一個新型的交易平臺,號稱能夠單線程每秒處理數百萬的訂單)的關鍵原因。爲什麼我們要將其開源?我們意識到對高性 能編程領域的一些傳統觀點,有點不對勁。我們找到了一種更好、更快地在線程間共享數據的方法,如果不公開於業界共享的話,那未免太自私了。同時開源也讓我 們覺得看起來更酷。
從這個站點,你可以下載到一篇解釋什麼是Disruptor及它爲什麼如此高性能的文檔。這篇文檔的編寫過程,我並沒有參與太多,只是簡單地插入了一些標點符號和重組了一些我不懂的句子,但是非常高興的是,我仍然從中提升了自己的寫作水平。
我發現要把所有的事情一下子全部解釋清楚還是有點困難的,所有我準備一部分一部分地解釋它們,以適合我的NADD聽衆。
首先介紹ringbuffer。我對Disruptor的最初印象就是ringbuffer。但是後來我意識到儘管ringbuffer是整個模式(Disruptor)的核心,但是Disruptor對ringbuffer的訪問控制策略纔是真正的關鍵點所在。
ringbuffer到底是什麼?
嗯,正如名字所說的一樣,它是一個環(首尾相接的環),你可以把它用做在不同上下文(線程)間傳遞數據的buffer。
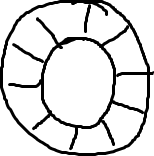
(好吧,這是我通過畫圖板手畫的,我試着畫草圖,希望我的強迫症不會讓我畫完美的圓和直線)
基本來說,ringbuffer擁有一個序號,這個序號指向數組中下一個可用的元素。(校對注:如下圖右邊的圖片表示序號,這個序號指向數組的索引4的位置。)
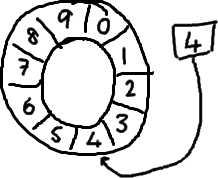
隨着你不停地填充這個buffer(可能也會有相應的讀取),這個序號會一直增長,直到繞過這個環。
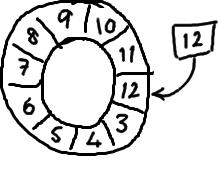
要找到數組中當前序號指向的元素,可以通過mod操作:
sequence mod array length = array index
以上面的ringbuffer爲例(java的mod語法):12 % 10 = 2。很簡單吧。
事實上,上圖中的ringbuffer只有10個槽完全是個意外。如果槽的個數是2的N次方更有利於基於二進制的計算機進行計算。
(校對注:2的N次方換成二進制就是1000,100,10,1這樣的數字, sequence & (array length-1) = array index,比如一共有8槽,3&(8-1)=3,HashMap就是用這個方式來定位數組元素的,這種方式比取模的速度更快。)
那又怎麼樣?
如果你看了維基百科裏面的關於環形buffer的 詞條,你就會發現,我們的實現方式,與其最大的區別在於:沒有尾指針。我們只維護了一個指向下一個可用位置的序號。這種實現是經過深思熟慮的—我們選擇用 環形buffer的最初原因就是想要提供可靠的消息傳遞。我們需要將已經被服務發送過的消息保存起來,這樣當另外一個服務通過nak (校對注:拒絕應答信號)告訴我們沒有成功收到消息時,我們能夠重新發送給他們。
聽起來,環形buffer非常適合這個場景。它維護了一個指向尾部的序號,當收到nak(校對注:拒絕應答信號)請求,可以重發從那一點到當前序號之間的所有消息:
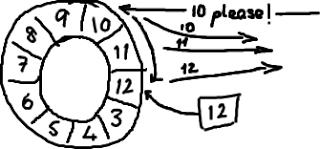
我們實現的ring buffer和大家常用的隊列之間的區別是,我們不刪除buffer中的數據,也就是說這些數據一直存放在buffer中,直到新的數據覆蓋他們。這就是 和維基百科版本相比,我們不需要尾指針的原因。ringbuffer本身並不控制是否需要重疊(決定是否重疊是生產者-消費者行爲模式的一部分–如果你等 不急我寫blog來說明它們,那麼可以自行檢出Disruptor項目)。
它爲什麼如此優秀?
之所以ringbuffer採用這種數據結構,是因爲它在可靠消息傳遞方面有很好的性能。這就夠了,不過它還有一些其他的優點。
首先,因爲它是數組,所以要比鏈表快,而且有一個容易預測的訪問模式。(譯者注:數組內元素的內存地址的連續性存儲的)。這是對CPU緩存友好的—也就是說,在硬件級別,數組中的元素是會被預加載的,因此在ringbuffer當中,cpu無需時不時去主存加載數組中的下一個元素。(校對注:因爲只要一個元素被加載到緩存行,其他相鄰的幾個元素也會被加載進同一個緩存行)
其次,你可以爲數組預先分配內存,使得數組對象一直存在(除非程序終止)。這就意味着不需要花大量的時間用於垃圾回收。此外,不像鏈表那樣,需要爲每一個添加到其上面的對象創造節點對象—對應的,當刪除節點時,需要執行相應的內存清理操作。
缺少的部分
我並沒有在本文中介紹如何避免ringbuffer產生重疊,以及如何對ringbuffer進行讀寫操作。你可能注意到了我將ringbuffer和鏈表那樣的數據結構進行比較,因爲我並認爲鏈表是實際問題的標準答案。
當你將Disruptor和基於 隊列之類的實現進行比較時,事情將變得很有趣。隊列通常注重維護隊列的頭尾元素,添加和刪除元素等。所有的這些我都沒有在ringbuffer裏提到,這 是因爲ringbuffer不負責這些事情,我們把這些操作都移到了數據結構(ringbuffer)的外部
原文鏈接:http://ifeve.com/ringbuffer/
譯文鏈接:http://ifeve.com/dissecting-disruptor-whats-so-special/
轉載來源:http://developer.51cto.com/art/201306/399341.htm