Stateful Computations over Data Streams(在數據流的有狀態計算)
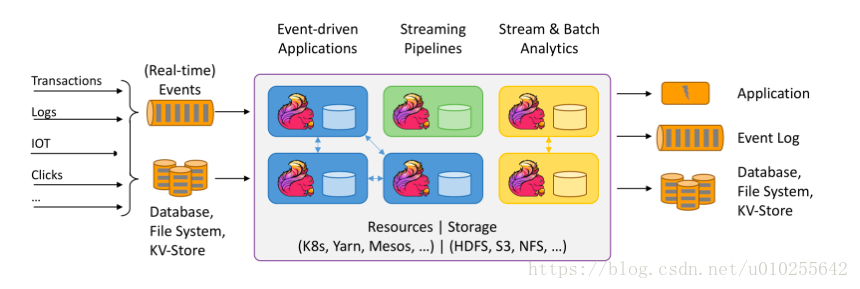
Apache Flink是一個用於分佈式流和批處理數據的開源平臺。Flink的核心是一個流數據流引擎,它爲數據流上的分佈式計算提供數據分佈、通信和容錯能力。Flink在流引擎之上構建批處理,覆蓋本地迭代支持、託管內存和程序優化。
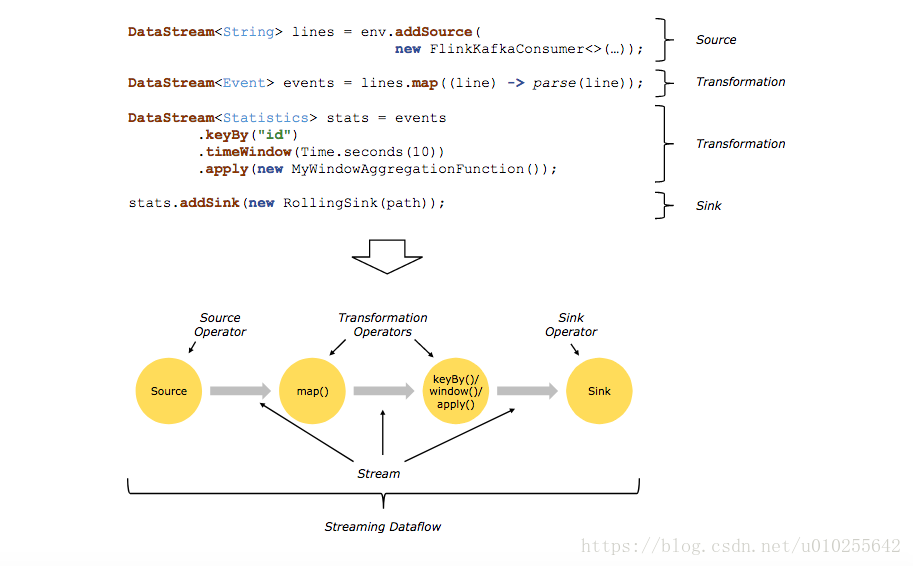
通常在程序中的轉換和數據流中的操作符之間存在一對一的對應關係。然而,有時一個轉換可能包含多個轉換操作符。
在串流連接器和批處理連接器文檔中記錄了源和匯(Sources and sinks)。在DataStream運算符和數據集轉換中記錄了轉換。
Flink提供了不同級別的抽象來開發流/批處理應用程序。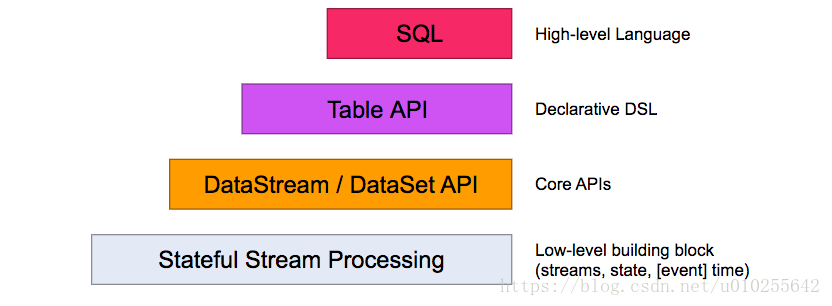
最低層次的抽象僅僅提供有狀態流( stateful streaming)。它通過Process函數嵌入到DataStream API中。它允許用戶自由地處理來自一個或多個流的事件,並使用一致的容錯狀態。此外,用戶可以註冊事件時間和處理時間回調,允許程序實現複雜的計算。
在實踐中,大多數應用程序不需要上面描述的低級抽象,而是對核心API(Core APIs )進行編程,比如DataStream API(有界/×××流)和DataSet API(有界數據集)。這些fluent api提供了用於數據處理的通用構建塊,比如各種形式的用戶指定的轉換、連接、聚合、窗口、狀態等。在這些api中處理的數據類型表示爲各自編程語言中的類。
低級流程函數與DataStream API集成,使得只對某些操作進行低級抽象成爲可能。DataSet API爲有界數據集提供了額外的原語,比如循環/迭代。
表API是一個以表爲中心的聲明性DSL,它可以動態地改變表(當表示流時)。表API遵循(擴展)關係模型:表有一個附加模式(類似於關係數據庫表)和API提供了類似的操作,如select, project, join, group-by, aggregate等。表API程序以聲明的方式定義邏輯操作應該做什麼而不是指定操作的代碼看起來如何。雖然表API可以通過各種用戶定義函數進行擴展,但它的表達性不如核心API,但使用起來更簡潔(編寫的代碼更少)。此外,表API程序還通過一個優化器在執行之前應用優化規則。
可以無縫地在表和DataStream/DataSet之間進行轉換,允許程序混合表API和DataStream和DataSet API。
Flink提供的最高級別抽象是SQL。這種抽象在語義和表示方面都類似於表API,但將程序表示爲SQL查詢表達式。SQL抽象與表API密切交互,SQL查詢可以在表API中定義的表上執行。
Flink程序的基本構建模塊是流和轉換(streams and transformations)。(請注意,Flink的DataSet API中使用的數據集也是內部流。)從概念上講,流是數據記錄的(可能是無限的)流,而轉換是將一個或多個流作爲輸入併產生一個或多個輸出流的操作。
執行時,Flink程序被映射到流數據流streaming dataflows,,由流和轉換操作符組成。每個數據流以一個或多個源開始,以一個或多個接收器結束。數據流類似於任意有向無環圖(DAGs)。雖然通過迭代構造允許特殊形式的循環,但爲了簡單起見將在大多數情況下忽略這一點。