




一、前言
上一篇博文講解了Zookeeper的典型應用場景,在大數據時代,各種分佈式系統層出不窮,其中,有很多系統都直接或間接使用了Zookeeper,用來解決諸如配置管理、分佈式通知/協調、集羣管理和Master選舉等一系列分佈式問題。
二、 Hadoop
Hadoop的核心是HDFS(Hadoop Distributed File System)和MapReduce,分別提供了對海量數據的存儲和計算能力,後來,Hadoop又引入了全新MapReduce框架YARN(Yet Another Resource Negotiator)。在Hadoop中,Zookeeper主要用於實現HA(High Availability),這部分邏輯主要集中在Hadoop Common的HA模塊中,HDFS的NameNode與YARN的ResourceManager都是基於此HA模塊來實現自己的HA功能,YARN又使用了Zookeeper來存儲應用的運行狀態。
YARN
YARN是一種新的 Hadoop 資源管理器,它是一個通用資源管理系統,可爲上層應用提供統一的資源管理和調度,它的引入爲集羣在利用率、資源統一管理和數據共享等方面帶來了巨大好處。其可以支持MapReduce模型,同時也支持Tez、Spark、Storm、Impala、Open MPI等。
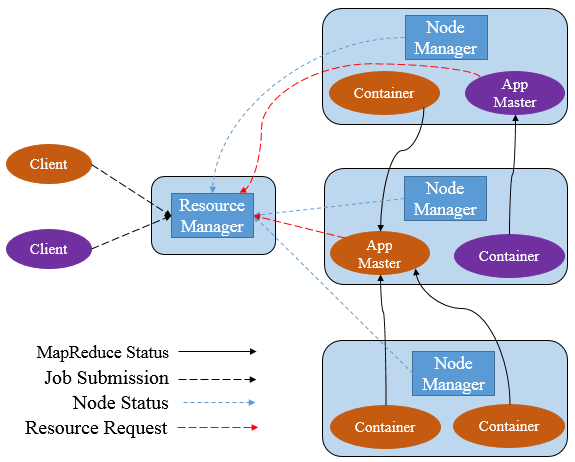
YARN主要由ResourceManager(RM)、NodeManager(NM)、ApplicationManager(AM)、Container四部分構成。其中,ResourceManager爲全局資源管理器,負責整個系統的資源管理和分配。由YARN體系架構可以看到ResourceManager的單點問題,ResourceManager的工作狀況直接決定了整個YARN架構是否可以正常運轉。
ResourceManager HA
爲了解決ResourceManager的單點問題,YARN設計了一套Active/Standby模式的ResourceManager HA架構。
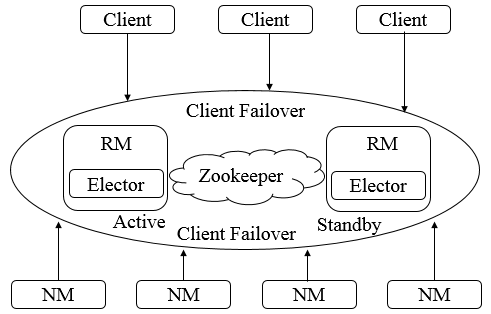
由上圖可知,在運行期間,會有多個ResourceManager並存,並且其中只有一個ResourceManager處於Active狀態,另外一些(允許一個或者多個)則處於Standby狀態,當Active節點無法正常工作時,其餘處於Standby狀態的節點則會通過競爭選舉產生新的Active節點。
主備切換
ResourceManager使用基於Zookeeper實現的ActiveStandbyElector組件來確定ResourceManager的狀態。具體步驟如下
1. 創建鎖節點。在Zookeeper上會有一個類似於/yarn-leader-election/pseudo-yarn-rm-cluster的鎖節點,所有的ResourceManager在啓動時,都會去競爭寫一個Lock子節點(/yarn-leader-election/pseudo-yarn-rm-cluster/ActiveStandbyElectorLock),子節點類型爲臨時節點,利用Zookeeper的特性,創建成功的那個ResourceManager切換爲Active狀態,其餘的爲Standby狀態。
2. 註冊Watcher監聽。所有Standby狀態的ResourceManager都會向/yarn-leader-election/pseudo-yarn-rm-cluster/ActiveStandbyElectorLock節點註冊一個節點變更監聽,利用臨時節點的特性,能夠快速感知到Active狀態的ResourceManager的運行情況。
3. 主備切換。當Active的ResourceManager無法正常工作時,其創建的Lock節點也會被刪除,此時,其餘各個Standby的ResourceManager都會收到通知,然後重複步驟1。
隔離(Fencing)
在分佈式環境中,經常會出現諸如單機假死(機器由於網絡閃斷或是其自身由於負載過高,常見的有GC佔用時間過長或CPU負載過高,而無法正常地對外進行及時響應)情況。假設RM集羣由RM1和RM2兩臺機器構成,某一時刻,RM1發生了假死,此時,Zookeeper認爲RM1掛了,然後進行主備切換,RM2會成爲Active狀態,但是在隨後,RM1恢復了正常,其依然認爲自己還處於Active狀態,這就是分佈式腦裂現象,即存在多個處於Active狀態的RM工作,可以使用隔離來解決此類問題。
YARN引入了Fencing機制,藉助Zookeeper的數據節點的ACL權限控制機制來實現不同RM之間的隔離。在上述主備切換時,多個RM之間通過競爭創建鎖節點來實現主備狀態的確定,此時,只需要在創建節點時攜帶Zookeeper的ACL信息,目的是爲了獨佔該節點,以防止其他RM對該節點進行更新。
還是上述案例,若RM1出現假死,Zookeeper會移除其創建的節點,此時RM2會創建相應的鎖節點並切換至Active狀態,RM1恢復之後,會試圖去更新Zookeeper相關數據,但是此時其沒有權限更新Zookeeper的相關節點數據,因爲節點不是由其創建的,於是就自動切換至Standby狀態,這樣就避免了腦裂現象的出現。
ResourceManager狀態存儲
在ResourceManager中,RMStateStore可以存儲一些RM的內部狀態信息,包括Application以及Attempts信息、Delegation Token及Version Information等,值得注意的是,RMStateStore的絕大多數狀態信息都是不需要持久化存儲的(如資源使用情況),因爲其很容易從上下文信息中重構,,在存儲方案設計中,提供了三種可能的實現。
1. 基於內存實現,一般用於日常開發測試。
2. 基於文件系統實現,如HDFS。
3. 基於Zookeeper實現。
由於存儲的信息不是特別大,Hadoop官方建議基於Zookeeper來實現狀態信息的存儲,在Zookeeper中,ResourceManager的狀態信息都被存儲在/rmstore這個根節點下,其數據結構如下。
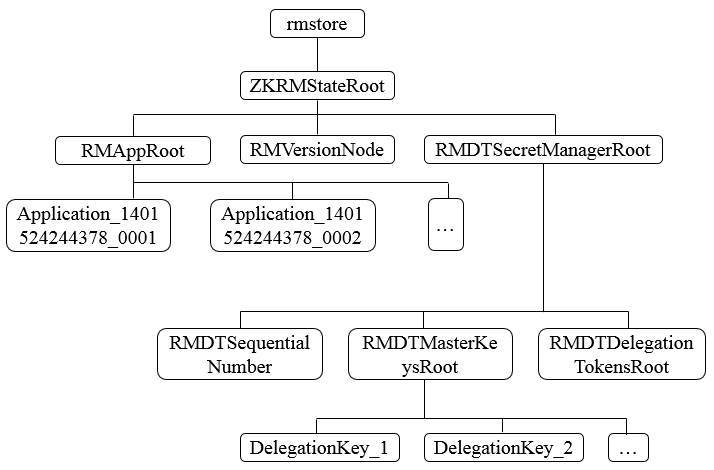
在RMAppRoot節點下存儲的是與各個Application相關的信息,RMDTSecretManagerRoot存儲的是與安全相關的Token信息。每個Active狀態的ResourceManager在初始化節點都會從Zookeeper上讀取到這些信息,並根據這些狀態信息繼續後續的處理。
三、HBase
HBase(Hadoop Database)是一個基於Hadoop的文件系統設計的面向海量數據的高可靠、高性能、面向列、可伸縮的分佈式存儲系統,其針對數據寫入具有強一致性,索引列也實現了強一致性,其採用了Zookeeper服務來完成對整個系統的分佈式協調工作,其架構如下
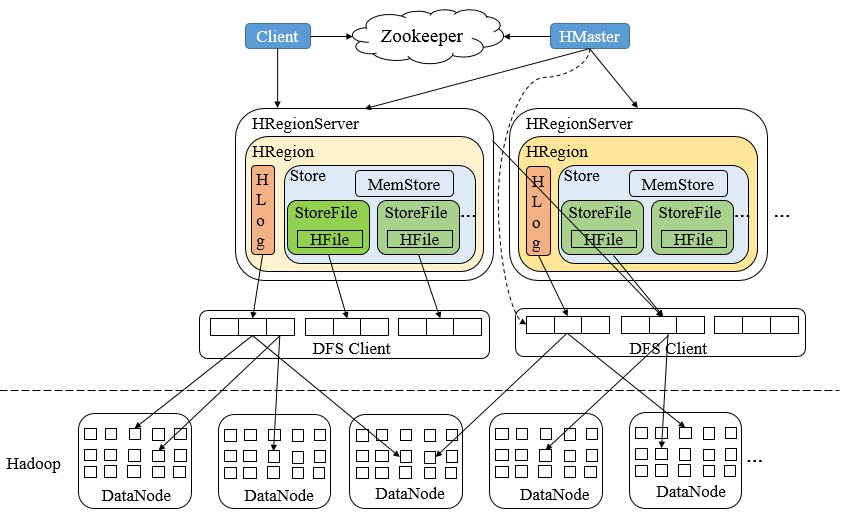
HBase架構中,Zookeeper是串聯起HBase集羣與Client的關鍵所在,Zookeeper在HBase中的系統容錯、RootRegion管理、Region狀態管理、分佈式SplitLog任務管理、Replication管理都扮演重要角色。
系統容錯
在HBase啓動時,每個RegionServer服務器都會到Zookeeper的/hbase/rs節點下創建一個信息節點,例如/hbase/rs/[Hostname],同時,HMaster會對這個節點進行監聽,當某個RegionServer掛掉時,Zookeeper會因爲在一段時間內無法接收其心跳信息(Session失效),而刪除掉該RegionServer服務器對應的節點,與此同時,HMaster則會接收到Zookeeper的NodeDelete通知,從而感知到某個節點斷開,並立即開始容錯工作,HMaster會將該RegionServer所處理的數據分片(Region)重新路由到其他節點上,並記錄到Meta信息中供客戶端查詢。
RootRegion管理
一:分佈式開發難度
“部分失敗”-->信息在網絡的兩個節點之間傳送出現故障,發送者無法知道接受者是否收到了這個信息。
Zookeeper可以解決上述問題,zookeeper不是讓分佈式系統避免“部分失敗”問題,而是讓分佈式系統在碰到“部分失敗”問題的時候,可以正確的處理解決此類問題,讓分佈式系統能夠正常運行。
二:zookeeper在分佈式系統中的實際運用場景
1:一組服務器向客戶端提供某種服務。舉個例子:幾臺服務器組成集羣,向前端集羣提供服務。在程序中會存在這一組服務器的列表名單,列表是高可用的,由存儲這份列表的服務器共同管理,如果某臺服務器壞掉了,其他的服務器可以替代壞掉的服務器,並且可以把壞掉的服務器從列表中刪除,故障服務器退出整個集羣。(zookeeper提供這種服務:統一命名服務,類似於javaEE的JNDI服務)。
2:分佈式鎖服務。當分佈式系統對數據進行增、刪、改、查的時候,保證數據的一致性。舉個例子:在分佈式系統將操作數據分散在集羣的不同節點上,會存在數據操作不一致的問題。zookeeper提供了一個鎖服務解決分佈式數據運算問題,保證數據的一致性。
3:配置管理。把一個應用部署到分佈式服務器上,就需要保證這些服務器上的配置文件是一樣的。如果配置文件發生變化,一個一個的去更改服務器的配置不僅危險,而且很麻煩。這個時候可以將zookeeper當成一個高可用的配置存儲器,將集羣的配置文件拷貝到zookeeper文件系統的某個節點上,讓zookeeper監視所有服務器的配置文件的狀態,一旦發現配置文件有變化,每臺服務器都會收到zookeeper的通知,讓每臺服務器同步zookeeper裏的配置文件,zookeeper服務器也會保證同步操作原子性,確保每臺服務器都能被正確更新配置文件。
4:爲分佈式系統提供故障修復的功能。集羣管理(節點故障管理)zookeeper可以讓集羣選出一個健康的節點作爲master(master可以動態選擇,當master出現故障的時候,zookeeper會立即選出一個新的master對集羣進行管理),master節點會知道當前集羣的運營狀態,一旦發現某個節點出現故障,master會把這個情況反映給其他服務器。從而分配新的服務器去替換掉出現故障的服務器。zookeeper也可以自動修復出現故障的服務器或者是將定位故障服務器的錯誤信息,將信息返回給集羣管理員修復。
以上是我初次瞭解zookeeper在分佈式系統應用時總結的一些內容,如果有錯誤的地方,歡迎大家指正。