




字符串編碼在Python裏邊是經常會遇到的問題,特別是寫文件以及網絡傳輸的過程中,當調用某些函數的時候經常會遇到一些字符串編碼提示錯誤,所以有必要弄清楚這些編碼到底在搞什麼鬼。

我們都知道計算機只能處理數字,文本轉換爲數字才能處理。計算機中8個bit作爲一個字節,所以一個字節能表示最大的數字就是255。計算機是美國人發明的,而英文中涉及的編碼並不多,一個字節可以表示所有字符了,所以ASCII(American national Standard Code for Information Interchange,美國國家標準信息交換碼)編碼就成爲美國人的標準編碼。但是我們都知道中文的字符肯定不止255個漢字,使用ASCII編碼來處理中文顯然是不夠的,所以中國製定了GB2312編碼,用兩個字節表示一個漢字,碰到及其特殊的情況,還會用三個字節來表示一個漢字。GB2312還把ASCII包含進去了。同理,日文,韓文等上百個國家爲了解決這個問題發展了一套自己的編碼,於是乎標準越來越多,如果出現多種語言混合顯示就一定會出現亂碼。那麼針對這種編碼“亂象”,Unicode便應運而生了,其將所有語言統一到一套編碼規則裏。

Unicode有許多種編碼,比如說可以通過16個bit或者32個bit來把所有語言統一到一套編碼裏。舉個栗子,字母A用ASCII編碼的十進制爲65,二進制爲0100 0001;漢字“中”已經超出了ASCII編碼的範圍,用unicode編碼是20013,二進制是01001110 00101101;A用unicode編碼只需要前面補0,二進制是00000000 0100 0001。可以看出,unicode不僅解決了ASCII碼本身的編碼問題,還解決了超出ASCII編碼範圍之外的其他國家字符編碼的統一問題。
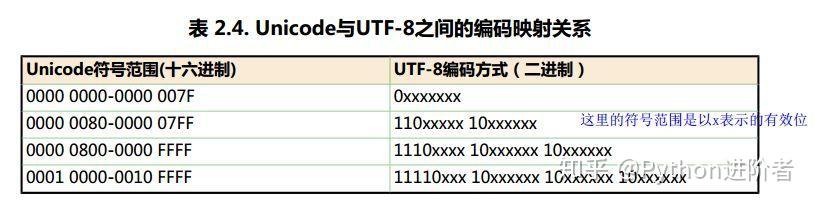
雖然unicode編碼能做到將不同國家的字符進行統一,使得亂碼問題得以解決,但是如果內容全是英文unicode編碼比ASCII編碼需要多一倍的存儲空間,同時如果傳輸需要多一倍的傳輸。當傳輸文件比較小的時候,內存資源和網絡帶寬尚能承受,當文件傳輸達到上TB的時候,如果 “硬”傳,則需要消耗的資源就不可小覷了。爲了解決這個問題,一種可變長的編碼“utf-8”就應運而生了,把英文變長1個字節,漢字3個字節,特別生僻的變成4-6個字節,如果傳輸大量的英文,utf8的作用就很明顯了。

不過正是因爲utf-8編碼的可變長,一會兒一個字符串是佔用一個字節,一會兒一個字符串佔用兩個字節,還有的佔用三個及以上的字節,導致在內存中或者程序中變得不好琢磨。unicode編碼雖然佔用內存空間,但是在編程過程中或者在內存處理的時候會比utf-8編碼更爲簡單,因爲它始終保持一樣的長度,一樣的長度對於內存和代碼來說,它的處理就會變得更加簡單。所以utf-8編碼在做網絡傳輸和文件保存的時候,將unicode編碼轉換成utf-8編碼,才能更好的發揮其作用;當從文件中讀取數據到內存中的時候,將utf-8編碼轉換爲unicode編碼,亦爲良策。
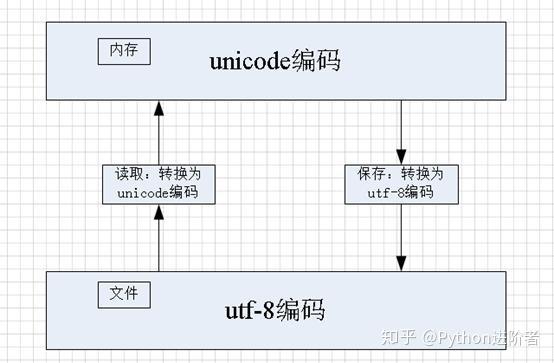
如上圖所示,當需要在內存中讀取文件的時候,此時將utf-8編碼的內存轉換爲unicode編碼,在內存中進行統一處理;當需要保存文件的時候,出於空間和傳輸效率的考慮,此時將unicode編碼轉換爲utf-8編碼。在Python中進行讀取和保存文件的時候,必須要顯示的指定文件編碼,其餘的事情就交給Python的相關庫去處理就可以了。
小夥伴們,瞭解了這些基礎知識之後,接下來對Python中的字符串編碼問題的理解就輕鬆的多了。