




爲什麼需要sequenceId?
HBase數據在寫入的時候首先追加寫入HLog,再寫入Memstore,也就是說一份數據會以兩種不同的形式存在於兩個地方。那兩個地方的同一份數據需不需要一種機制將兩者關聯起來?有的朋友要問爲什麼需要關聯這兩者,那筆者這裏提出三個相關問題:
-
Memstore中的數據flush到HDFS文件中後HLog對應的數據是不是就可以被刪除了?不然HLog會無限增長!那問題來了,Memstore中被flush到HDFS的數據,如何映射到HLog中的相關日誌數據?
-
HBase中單個HLog都有固定大小,日誌文件最大個數也是固定設置的,默認最大HLog文件數量爲8。如果日誌數量超過這個數量,就必須刪除最老的HLog日誌。那問題來了,如何知道待刪除HLog日誌對應的所有數據都已經落盤了?(如果知道哪些數據沒有落盤,就可以強制對其執行flush,之後就可以將HLog刪除)
- RegionServer宕機之後Memstore中數據必然會丟失,大家都知道可以通過HLog進行恢復。那問題來了,HLog中哪些數據需要恢復?哪些不需要恢復?
這三個問題從本質上來講是一個問題,都需要一種介質來表示Memstore中數據Flush的那個點對應HLog哪個位置,這個介質就是本文要介紹的重點-sequenceId
HLog日誌核心結構
要理解sequenceId,需要簡單瞭解HBase中HLog文件的基本結構,如下圖所示,關注點主要有兩點:
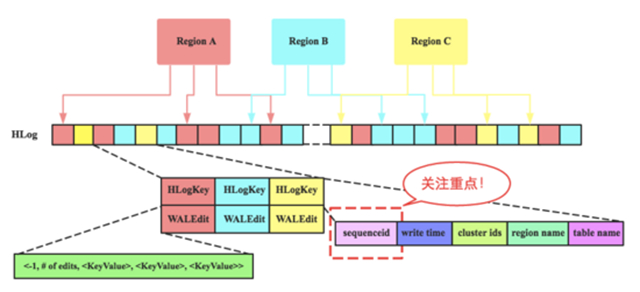
-
每個RegionServer擁有一個或多個HLog(默認只有1個,1.x版本可以開啓 MultiWAL 功能,允許多個HLog)。 每個HLog是多個Region共享的 ,如圖所示,Region A、Region B和Region C共享一個HLog文件。
- HLog中日誌單元WALEntry表示一次行級更新的最小追加單元(圖中紅色/×××小方框) ,它由兩部分組成:HLogKey和WALEdit,HLogKey中包含多個屬性信息,包含table name、region name、 sequenceid 等; WALEdit用來表示一個事務中的更新集合, 一次行級事務可以原子操作同一行中的多個列。上圖中WALEdit包含多個KeyValue。
什麼是sequenceid?
sequenceid是region級別一次行級事務的自增序號。這個定義是我琢磨出來的,需要關注的地方有三個:
-
sequenceid是自增序號。很好理解,就是隨着時間推移不斷自增,不會減小。
-
sequenceid是一次行級事務的自增序號。行級事務是什麼?簡單點說,就是更新一行中的多個列族、多個列,行級事務能夠保證這次更新的原子性、一致性、持久性以及設置的隔離性,HBase會爲一次行級事務分配一個自增序號。
- sequenceid是 region級別 的自增序號。每個region都維護屬於自己的sequenceid,不同region的sequenceid相互獨立。
在這樣的定義條件下,HLog就會如下圖所示:
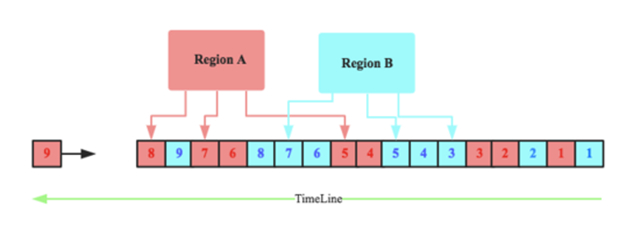
HLog中有兩個Region的日誌記錄,方框中的數字表示sequenceid,隨着時間的推移,每個region的sequenceid都獨立自增。
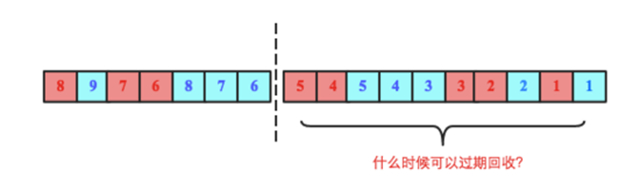
問題一:HLog在什麼時候可以過期回收?
下圖中虛線右側部分爲超過單個HLog大小閾值後切分形成的一個HLog文件,問題是這個文件什麼時候可以被系統回收刪除。理論上來說只需要這個文件上所有Region對應的最大sequenceid已經落盤就可以刪除,比如下圖中如果RegionA對應的最大sequenceid(5)已經落盤,同時RegionB對應的最大sequenceid(5)也落盤,那該HLog就可以被刪除。那怎麼實現的呢?
RegionServer會爲每個Region維護了一個變量oldestUnflushedSequenceId(實際上是爲每個Store,爲了方便講解,此處暫且認爲是Region,不影響原理),表示這個Region最早的還未落盤的seqid ,即這個seqid之前的所有數據都已經落盤。接下來看看這個值在flush的時候是怎麼維護的,以及如何用這個值實現HLog的過期回收判斷。
下圖是flush過程中oldestUnflushedSequenceId變量變化的示意圖,初始時爲null,假設在某一時刻階段二RegionA(紅色方框)要執行flush,中間HLog中sequenceId爲1~4對應的數據將會落盤,在執行flush之前,HBase會append一個空的Entry到HLog,僅爲獲取下一個sequenceId(5),並將這個sequenceId賦給OldestUnflushedSequenceId-RegionA。如圖中第三階段OldestUnflushedSequenceId-RegionA指向sequenceId爲5的Entry。
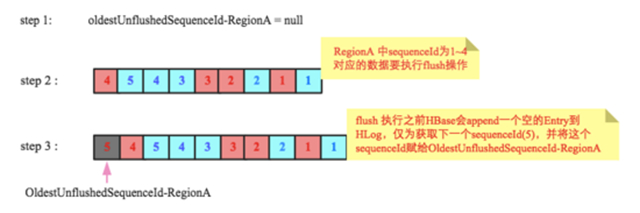
可見,每次flush之後這個變量就會往前移動一段距離。這個變量至關重要,是解決文初提到的三個問題的關鍵。基於上述對這個變量的理解,來看看下面兩種場景下右側HLog是否可以刪除:
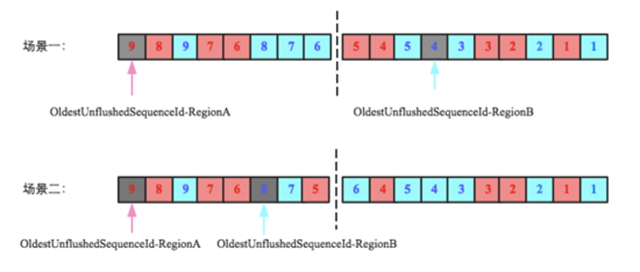
很顯然,場景一中右側HLog還有未落盤的數據(sequenceid=5還未落盤),因此不能刪除;而場景二中右側HLog的所有數據都已經落盤,所以這個HLog理論上就已經可以被刪除回收。
問題二:HLog數量超過閾值(maxlogs)之後刪除最早HLog,應該強制刷新哪些Region?
假設當前系統設置了HLog的最大數量爲32,即hbase.regionserver.maxlogs=32,上圖中最左側HLog是第33個,此時系統會獲取到最老的日誌(最右側HLog),並檢查所有的Entry對應的數據是否都已經落盤,如圖所示RegionC還有部分數據沒有落地,爲了安全刪除這個HLog就必須強制對該Region執行flush操作,將所有數據落盤。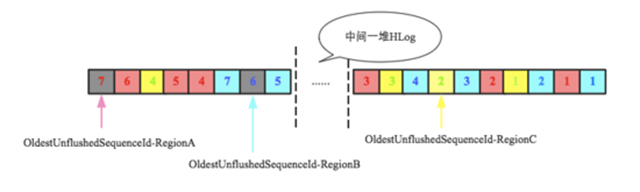
問題三:RegionServer宕機恢復replay日誌時哪些WALEntry需要被回放,哪些會被skip?
理論上來說只需要回放Memstore中沒有落地的數據對應的WALEntry,已經落地數據對應的WALEntry可以skip。可問題是RegionServer已經宕機了, 對應信息肯定沒有了,如何是好?想辦法持久化唄,上文分析oldestUnflushedSequenceId變量是flush時產生的一個變量,這個變量 完全 可以以flush的時候以元數據的形式寫到HFile中 (代碼見下圖):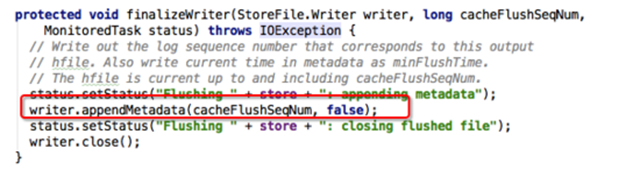
這樣Region在宕機遷移重新打開之後加載HFile元數據就可以恢復出這個核心變量oldestUnflushedSequenceId(本次flush所生成的所有HFlie中都存儲同一個sequenceId),這個sequenceId在恢復出來之後就可以用來在回放WALEntry的時候過濾哪些Entry需要被回放,哪些會被skip。
這裏提一個問題:有沒有可能一次flush所生成的所有HFile中存儲的sequenceId出現不一致,比如:region中所有store(store1、store2)都執行flush,其中store1執行flush成功,此時oldestUnflushedSequenceId變量成功追加到對應的HFile中;但在store2執行flush之前RegionServer發生宕機異常,store2對應的oldestUnflushedSequenceId變量還是上個文件對應的sequenceId,這種情況下回放數據會不會有影響?如果有,爲什麼?如果沒有,是什麼機制保證的?
到目前爲止,上面所有分析都基於一個事實:hbase中flush操作是region級別操作,即每次執行flush都需要整個region中的所有store全都執行flush。接下來作爲延伸閱讀內容,對Per-CF Flush比較感興趣的可以繼續閱讀,Per-CF Flush允許系統對某個或某些列組單獨執行flush。實現原理與上文所分析內容基本相似。不同的是上文中 oldestUnflushedSequenceId是與region一一對應的,Per-CF Flush中這個參數需要細化到store,與store一一對應。
延伸閱讀:Per-CF Flush
region級別flush確實存在不少問題,在多個列族的情況下其中一個store大小超過了閾值(128M),不論其他store多大多小都會強制落盤,有些很小的列族(幾兆)落盤後形成很多特別小的文件,對hbase的讀並不是一件好事。
per-cf flush允許單個store執行flush,該feature在1.0.0以上版本已經存在,在1.2.0版本設置爲默認策略。 實現這個功能有兩個必要的工作,其一是提出一種新的flush策略能夠在多個列族中選擇一個或者多個單獨進行進行flush,目前新策略稱爲FlushLargerStoresPolicy,即選擇當前最大的一個store進行flush。其二是必須將oldestUnflushedSequenceId的粒度從region細化到store,即從map改爲map>,上文所述三個問題的判斷邏輯也需要修改爲store級別判斷邏輯。這裏使用store級別判斷邏輯簡單對問題一和問題三進行復盤。
Per-CF Flush策略下,HLog在什麼時候可以過期回收?
region級別的判斷邏輯主要依賴於map,詳見上文。store級別的數據結構改爲了map>,其實很容易經過簡單的轉化又變回region級別,map找到最小的oldestUnflushedSequenceId稱爲minSeqNum,這樣region級別的數據結構就變出來了 – map,其他邏輯都不用變。
Per-CF Flush策略下,RegionServer宕機恢復replay日誌時哪些數據需要被回放,哪些會被skip?
這個問題稍微複雜一點,第一個關注的問題是回放粒度的問題。需要回過頭來看看HLog中Entry的組成,如圖可以知道一個Entry由WALKey和WAKEdit兩部分構成,WALKey包含一些基本信息,本文重點關注sequenceId這個變量; WALEdit包含插入\更新的KeyValue集合,這裏需要重點注意, 這些KeyValue可能包含一行中多個列族(列),因此可以說WALEdit會包含多個store更新的KeyValue 。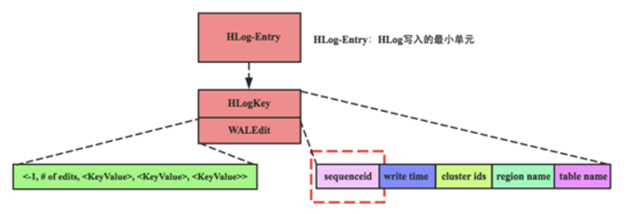
在All-CF Flush策略下,我們以HLog-Entry爲粒度進行數據回放沒有任何問題,但是在Per-CF Flush策略下就不再行得通。因爲一個HLog-Entry中多個CF的KeyValue是混在一起的,可能部分KV已經落盤,其他部分還沒有。因此需要將回放粒度減小到KeyValue級別,一個一個KeyValue分別進行檢查回放。
回放粒度問題摸清了,再來關注哪些KeyValue需要被回放,哪些會被skip。上文說過,每次flush的時候對應的oldestUnflushedSequenceId會被持久化到HFile的元數據中。在All-CF Flush策略下,一次flush操作中整個region所有store所持久化的oldestUnflushedSequenceId都相同,因此回放的時候HLog-Entry的sequenceId只需要與這一個oldestUnflushedSequenceId比較就可以,大的話就需要回放,小的話就skip。但在Per-CF的場景下又不再行得通,一個region中不同store都有自己獨立的oldestUnflushedSequenceId,因此回放的時候需要根據KeyValue找到對應store,在與該store中的oldestUnflushedSequenceId比較,大的話需要回放,小的話skip。
總結起來就是:skip hlog cells per store when replaying,注意這裏蘊含兩個點: hlog cells 以及 per store。
全文總結
本文從hbase中非常重要的一個變量(sequenceId)入手,將其所涉及到的WAL模塊、Flush模塊分別進行了說明。文中只講了一個大概,很多細節知識並沒有深究,有興趣的同學可以根據文中所講內容深入源碼,相信會比較容易。接下來筆者將會繼續根據sequenceId這個話題分析HBase中MVCC機制,敬請期待!
爲了幫助大家讓學習變得輕鬆、高效,給大家免費分享一大批資料,幫助大家在成爲大數據工程師,乃至架構師的路上披荊斬棘。在這裏給大家推薦一個大數據學習交流圈:658558542 歡迎大家進×××流討論,學習交流,共同進步。
當真正開始學習的時候難免不知道從哪入手,導致效率低下影響繼續學習的信心。
但最重要的是不知道哪些技術需要重點掌握,學習時頻繁踩坑,最終浪費大量時間,所以有有效資源還是很有必要的。
最後祝福所有遇到瓶疾且不知道怎麼辦的大數據程序員們,祝福大家在往後的工作與面試中一切順利