




一、用戶管理
1、創建表空間
create tablespace school #指定表空間名稱
datafile '/orc/app/oracle/oradata/school01.dbf' #指定數據文件路徑
size 200M #指定表空間大小
autoextend on #設置表空間自動擴展2、創建用戶
create user c##tom #創建用戶"Tom"
identified by abc123 #設置用戶密碼"abc123"
default tablespace school #指定默認表空間"school"
temporary tablespace temp #指定默認臨時表空間"temp"
quota unlimited on school #針對"school"表空間不做磁盤配額限制
password expire; #設置用戶每次登錄,強行修改密碼更改用戶密碼alter user c##tom identified by 123123; #將用戶"tom"密碼更改爲"123123"
刪除用戶drop user c##tom cascade;
3、用戶授權
grant connect,resource to c##tom; #connect爲連接權限;resource爲管理數據庫權限
revoke connect,resource from c##tom; #撤銷用戶授權(sysdba用戶下)以tom身份登錄
方法一:sqlplus #輸入用戶名與口令!
方法二:SQL> conn
注意:tom與school表空間綁定,所以寫入數據都將保存在school文件中!
4、提交事務(默認開啓事務)
commit; #注意,oracle默認是手動提交事務,對數據編輯完之後,必須使用commit進行提交
rollback; #注意,事務回滾使用此命令
set autocommit on; #設置自動提交二、索引
1、說明
1) 索引是數據庫對象之一,用於加快數據的檢索,類似於書籍的索引。在數據庫中索引可以減少數據庫程序查詢結果時需要讀取的數據量,類似於在書籍中我們利用索引可以不用翻閱整本書即可找到想要的信息。
2) 索引是建立在表上的可選對象;索引的關鍵在於通過一組排序後的索引鍵來取代默認的全表掃描檢索方式,從而提高檢索效率
3) 索引在邏輯上和物理上都與相關的表和數據無關,當創建或者刪除一個索引時,不會影響基本的表;
4) 索引一旦建立,在表上進行DML操作時(例如在執行插入、修改或者刪除相關操作時),oracle會自動管理索引,索引刪除,不會對錶產生影響
5) 索引對用戶是透明的,無論表上是否有索引,sql語句的用法不變
6)oracle創建主鍵時會自動在該列上創建索引
2、索引原理
1) 若沒有索引,搜索某個記錄時(例如查找name='wish')需要搜索所有的記錄,因爲不能保證只有一個wish,必須全部搜索一遍
2) 若在name上建立索引,oracle會對全表進行一次搜索,將每條記錄的name值哪找升序排列,然後構建索引條目(name和rowid),存儲到索引段中,查詢name爲wish時即可直接查找對應地方
3) 創建了索引並不一定就會使用,oracle自動統計表的信息後,決定是否使用索引,表中數據很少時使用全表掃描速度已經很快,沒有必要使用索引
3、索引簡歷原則
1)如果有兩個或者以上的索引,其中有一個唯一性索引,而其他是非唯一,這種情況下oracle將使用唯一性索引而完全忽略非唯一性索引
2)至少要包含組合索引的第一列(即如果索引建立在多個列上,只有它的第一個列被where子句引用時,優化器纔會使用該索引)
3)小表不要簡歷索引
4)對於基數大的列適合建立B樹索引,對於基數小的列適合簡歷位圖索引
5)列中有很多空值,但經常查詢該列上非空記錄時應該建立索引
6)經常進行連接查詢的列應該創建索引
7)使用create index時要將最常查詢的列放在最前面
8)LONG(可變長字符串數據,最長2G)和LONG RAW(可變長二進制數據,最長2G)列不能創建索引
9)限制表中索引的數量(創建索引耗費時間,並且隨數據量的增大而增大;索引會佔用物理空間;當對錶中的數據進行增加、刪除和修改的時候,索引也要動態的維護,降低了數據的維護速度)
4、索引使用(創建、修改、刪除、查看)
創建索引Create index index_name on table_name(column)
修改索引
1)重命名索引alter index index_sno rename to bitmap_index;
2)合併索引(表使用一段時間後在索引中會產生碎片,此時索引效率會降低,可以選擇重建索引或者合併索引,合併索引方式更好些,無需額外存儲空間,代價較低)alter index index_sno coalesce;
3)重建索引
方式一:刪除與原來的索引,重新建立索引
方式二:alter index index_sno rebuild;
刪除索引drop index index_sno;
查看索引select index_name,index-type, tablespace_name, uniqueness from all_indexes where table_name ='tablename'; #查看索引
例子:
create index index_sno on student('name');
select * from all_indexes where table_name='student';5、索引的分類
A、B數索引(默認索引,保存排序過的索引列和對應的rowid值)
說明:
1)oracle中最常用的索引;B樹索引就是一顆二叉樹;葉子節點(雙向鏈表)包含索引列和指向表中每個匹配行的ROWID值
2)所有葉子節點具有相同的深度,因而不管查詢條件怎樣,查詢速度基本相同
3)能夠適應精確查詢、模糊查詢和比較查詢
分類:
UNIQUE,NON-UNIQUE(默認),REVERSE KEY(數據列中的數據是反向存儲的)
創建例子
create index index_info on info(score) ;
create unique index uni_index_info on info(id); #唯一索引
create index rev_index_info on info(createtime) reverse; #反向索引使用場景
列基數(列不重複值的個數)大時適合使用B數索引
B、位圖索引
說明:
創建位圖索引時,oracle會掃描整張表,併爲索引列的每個取值建立一個位圖(位圖中,對錶中每一行使用一位(bit,0或者1)來標識該行是否包含該位圖的索引列的取值,如果爲1,表示對應的rowid所在的記錄包含該位圖索引列值),最後通過位圖索引中的映射函數完成位到行的ROWID的轉換
創建例子:create bitmap index bt_index_info on info(address);
使用場景:
對於基數小的列適合簡歷位圖索引(例如性別等)
C、單列索引和複合索引(基於多個列創建)
注意:
即如果索引建立在多個列上,只有它的第一個列被where子句引用時,優化器纔會使用該索引,即至少要包含組合索引的第一列
D、函數索引
說明:
1)當經常要訪問一些函數或者表達式時,可以將其存儲在索引中,這樣下次訪問時,該值已經計算出來了,可以加快查詢速度
2)函數索引既可以使用B數索引,也可以使用位圖索引;當函數結果不確定時採用B樹索引,結果是固定的某幾個值時使用位圖索引
3)函數索引中可以水泥用len、trim、substr、upper(每行返回獨立結果),不能使用如sum、max、min、avg等
創建列子:
create index up_index_info on info(upper(name)); #大寫函數索引
select * from student where upper(name) ='WISH'; #驗證查看三、視圖
1、視圖的定義
視圖(view),也稱虛表,不佔用物理空間,這個也是相對概念,因爲視圖本身的定義語句還是要存儲在數據字典裏的。視圖只有邏輯定義。每次使用的時候,只是重新執行SQL。
視圖是從一個或多個實際表中獲得的,這些表的數據存放在數據庫中。那些用於產生視圖的表叫做該視圖的基表。一個視圖也可以從另一個視圖中產生。
視圖的定義存在數據庫中,與此定義相關的數據並沒有再存一份於數據庫中。通過視圖看到的數據存放在基表中。
視圖看上去非常象數據庫的物理表,對它的操作同任何其它的表一樣。當通過視圖修改數據時,實際上是在改變基表中的數據;相反地,基表數據的改變也會自動反映在由基表產生的視圖中。由於邏輯上的原因,有些Oracle視圖可以修改對應的基表,有些則不能(僅僅能查詢)。
還有一種視圖:物化視圖(MATERIALIZED VIEW ),也稱實體化視圖,快照 (8i 以前的說法) ,它是含有數據的,佔用存儲空間。
查詢視圖沒有什麼限制, 插入/更新/刪除視圖的操作會受到一定的限制; 所有針對視圖的操作都會影響到視圖的基表; 爲了防止用戶通過視圖間接修改基表的數據, 可以將視圖創建爲只讀視圖(帶上with read only選項)
2、視圖的作用
1)提供各種數據表現形式, 可以使用各種不同的方式將基表的數據展現在用戶面前, 以便符合用戶的使用習慣(主要手段: 使用別名);
2)隱藏數據的邏輯複雜性並簡化查詢語句, 多表查詢語句一般是比較複雜的, 而且用戶需要了解表之間的關係, 否則容易寫錯; 如果基於這樣的查詢語句創建一個視圖, 用戶就可以直接對這個視圖進行"簡單查詢"而獲得結果. 這樣就隱藏了數據的複雜性並簡化了查詢語句.這也是oracle提供各種"數據字典視圖"的原因之一,all_constraints就是一個含有2個子查詢並連接了9個表的視圖(在catalog.sql中定義);
3)執行某些必須使用視圖的查詢. 某些查詢必須藉助視圖的幫助才能完成. 比如, 有些查詢需要連接一個分組統計後的表和另一表, 這時就可以先基於分組統計的結果創建一個視圖, 然後在查詢中連接這個視圖和另一個表就可以了;
4)提供某些安全性保證. 視圖提供了一種可以控制的方式, 即可以讓不同的用戶看見不同的列, 而不允許訪問那些敏感的列, 這樣就可以保證敏感數據不被用戶看見;
5)簡化用戶權限的管理. 可以將視圖的權限授予用戶, 而不必將基表中某些列的權限授予用戶, 這樣就簡化了用戶權限的定義。
3、普通視圖
1)創建普通視圖
grant create view to c##tom; #Sysdba身份登錄爲用戶創建視圖授權
SQL> create view view_info as select * from info;2)查看視圖SQL> select * from view_info;
3)刪除視圖SQL> drop view view_info;
4、物化視圖
1)切換dba身份SQL> conn / as sysdba
2)授權
SQL> grant create materialized view to c##tom; #授予創建物化視圖權限
SQL> grant query rewrite to c##tom; #授予查詢、重寫權限
SQL> grant create any table to c##tom; #授予創建任何表權限
SQL> grant select any table to c##tom; #授予查詢任何表權限3)創建物化視圖日誌SQL> conn #連接tom用戶
SQL> create materialized view log on info;4)創建物化視圖SQL> create materialized view mtrlview_pro
2 build immediate #創建物化視圖是否立即生成數據,immediate代表true
3 refresh fast #設置與基表進行同步更新,如果不添加此參數,相當於快照功能
4 on commit #開啓提交功能
5 enable query rewrite #開啓查詢、重寫功能
6 as select * from info;5)刪除視圖SQL> drop materialized view mtrlview_pro;
四、導入導出數據
drop index up_index_info; #刪除前面創建的索引,否則無法更改列字段的屬性
alter table info modify name varchar2(11); #更改name字段的位寬
begin
2 for i in 2..100
3 loop
4 insert into info values(i,'zhangsan'||i,88,to_date('2018-10-10','yyyy-mm-dd'),'nanjing');
5 end loop;
6 commit;
7 end;
8 /select count(*) from info; //最終查看數據量
1、數據導入:
ho ls /home/oracle #oracle軟件可以兼容Linux 使用ho命令跟上liunx命令查看家目錄文件
用指定用戶導入數據
imp c##tom/abc123 full=y file=/home/oracle/test.dmp
select * from tab; #查看相關表信息2、導出數據
exp c##tom/abc123 file=/home/oracle/test.dmp #指定用戶進行導出數據
ls /home/oracle/ //查看驗證五、序列
1、序列定義
序列(SEQUENCE)是序列號生成器,可以爲表中的行自動生成序列號,產生一組等間隔的數值(類型爲數字)。不佔用磁盤空間,佔用內存。
其主要用途是生成表的主鍵值,可以在插入語句中引用,也可以通過查詢檢查當前值,或使序列增至下一個值。
序列是oracle用來生產一組等間隔的數值。序列是遞增,而且連續的。oracle主鍵沒有自增類型,所以一般使用序列產生的值作爲某張表的主鍵,實現主鍵自增。序列的編號不是在插入記錄的時候自動生成的,必須調用序列的方法來生成(一般調用nextval方法)。我們也可以編寫表的insert觸發器來進自動生成。
2、創建序列
SQL> create sequence toy_seq
2 start with 1 #指定初始值
3 increment by 1 #指定增量
4 maxvalue 2000 #指定最大值
5 nocycle #指定工作模式爲非循環
6 cache 30; #指定緩存區30個數值,空閒等待3、添加數據
Delete from info; #清空表
SQL> insert into info values (toy_seq.nextval,'Sony',999999,to_date('2018-10-09','yyyy-mm-dd'),'ok'); #插入值多次執行該語句,發現ID對應的序列號在自增
Select * from info; #查看驗證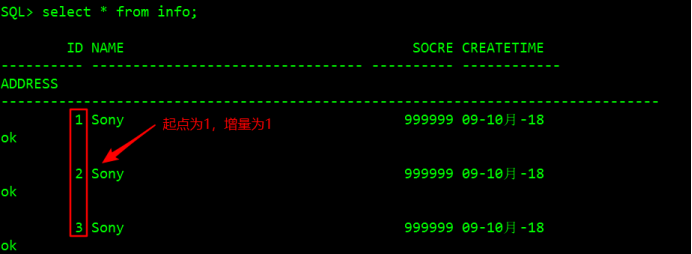
4、查看序列SQL> select toy_seq.currval from dual; #查看當前序列的值
SQL> select sequence_name,increment_by,cache_size from user_sequences; #查看序列的相關信息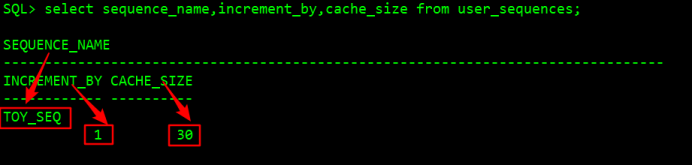
5、更改序列SQL> alter sequence toy_seq maxvalue 5000 cycle;
6、刪除序列SQL> drop sequence toy_seq;
六、同義詞
1、定義
從字面上理解就是別名的意思,和視圖功能類似。就是一種映射關係。主要分爲私有(用戶獨有)和公有(系統用戶共有)
2、私有同義詞管理
1)創建私有同義詞
SQL> grant create synonym to c##tom #dba爲用戶創建同義詞授權
SQL> show user; #查看當前用戶
SQL> create synonym pr_info for info; #爲表設置了一個別名"pr_info"2)調用私有同義詞SQL> select * from pr_info; #注意,此時定義的爲私有同義詞,只是對當前用戶有效,切換另一個用戶無法識別
3、公有同義詞管理
1)授予用戶權限
SQL> conn / as sysdba #管理員登錄
SQL> grant create public synonym to c##tom; #爲用戶創建公有同義詞授權2)創建公有同義詞SQL> conn c##tom/abc123 #連接普通用戶
SQL> create public synonym public_sy_info for info;3)查看公有同義詞SQL> conn / as sysdba #管理員登錄
SQL> select * from public_sy_info; #切換dba之後可以查看,dba中並沒有info表,說明共有同義詞生效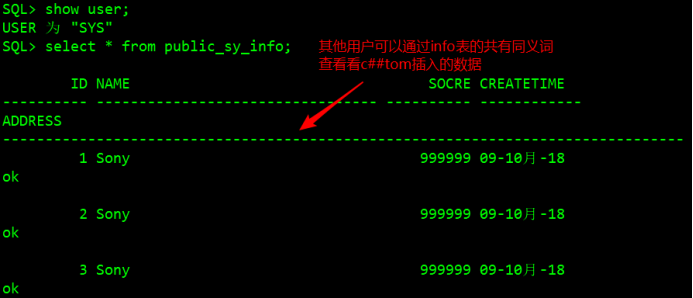
七、分區表
1、定義
以某張表的某個字段爲依據,將數據分散存儲在不同表空間中
2、建立若干表空間
SQL> show user; #當前用戶爲系統管理員
SQL> create tablespace tmp01 #注意建立4個表空間,依次爲tmp01、tmp02、tmp03、tmp04
2 datafile '/orc/app/oracle/oradata/tmp01.dbf'
3 size 100M;
SQL> edit #編輯之前的操作將便空間名和dbf文件名修改
SQL> / #指定edit操作重複操作創建好四個表空間
SQL> select tablespace_name from dba_tablespaces; //查看錶空間是否創建成功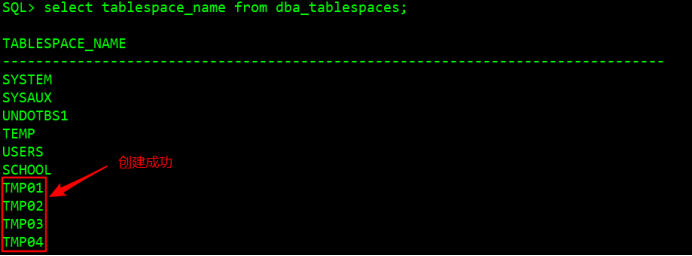
3、創建數據表
SQL> create table sales #創建表
2 (
3 sales_id number(4),
4 product_id varchar2(5),
5 sales_date date
6 )
7 partition by range (sales_date) #指定按時間字段進行分區
8 (
9 partition p1 values less than (to_date('2018-04-03','yyyy-mm-dd')) tablespace tmp01, #p1指定名稱;less than小於指定的時間;tablespace指定表空間
10 partition p2 values less than (to_date('2018-05-03','yyyy-mm-dd')) tablespace tmp02,
11 partition p3 values less than (to_date('2018-06-03','yyyy-mm-dd')) tablespace tmp03,
12 partition p4 values less than (maxvalue) tablespace tmp04
13 );4、插入測試數據
insert into sales values (1,'ttt1',to_date('2018-03-23','yyyy-mm-dd')); #應該存放在P1
insert into sales values (1,'ttt1',to_date('2018-04-23','yyyy-mm-dd')); #應該存放在P2
insert into sales values (1,'ttt1',to_date('2018-05-23','yyyy-mm-dd')); #應該存放在P3
insert into sales values (1,'ttt1',to_date('2018-06-23','yyyy-mm-dd')); #應該存放在P45、查詢分區驗證SQL> select * from sales partition(P1); #按照時間分散存儲,已經存儲到P1中



八、控制文件
1、定義
控制文件中記錄了oracle數據庫的物理結構,也就是記錄了數據庫數據文件和日誌文件的位置,控制文件中還記錄了多種SCN,用這些SCN來確定數據文件和日誌文件是否是正確的。如果不正確那麼數據庫就需要恢復。
2、查看控制文件
3、備份控制文件
alter database backup controlfile to '/home/oracle/controlfile.bk';