




1. 集羣結構
在我們探究ES的分佈式架構之前,我們使用一個簡單的導圖描述一下我們在設計分佈式系統時會考慮的問題,如圖1所示。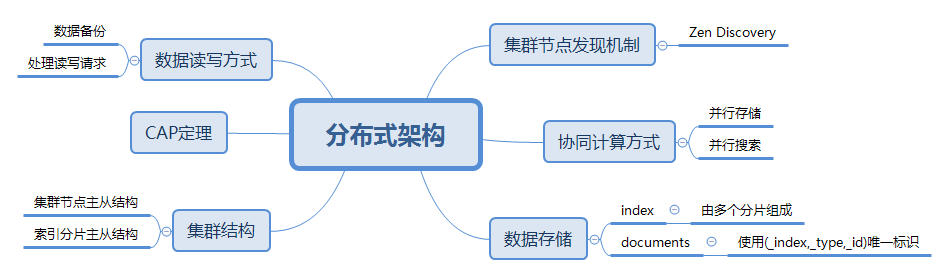
帶着圖1中的問題我們來探究一下ES集羣,ES集羣是一個典型的主從結構,從某種意義上來說,符合現今大多數主流分佈式存儲、分佈式計算系統的審美要求。下面我們逐步來了解集羣中的這些東東。
先用來自文獻2的一張集羣結構圖開始我們的探究。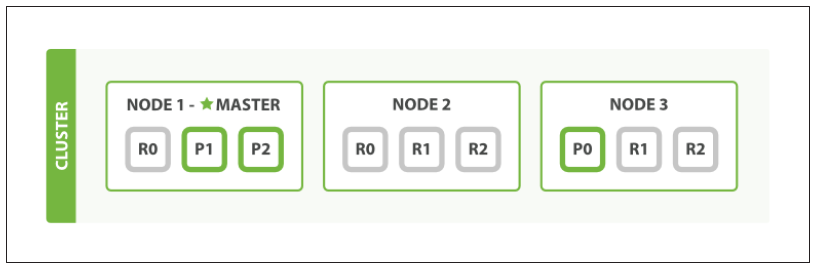
1.1 集羣節點
在ES集羣中,一個ES實例就是一個節點(node),圖2中顯示的是三個節點的一個集羣。集羣中有一個主節點(master)。
主節點負責整個集羣範圍的輕量級操作,如創建或刪除索引、跟蹤哪些節點是集羣的一部分以及決定將哪些分片分配給哪些節點。對於集羣健康而言,擁有一個穩定的主節點非常重要。
可以在集羣的任何一個節點上使用如下命令獲取集羣中的節點信息:
curl -iXGET 'localhost:9200/_cat/nodes?v'返回結果的示例如下:
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.127.100 40 94 0 0.01 0.07 0.06 mdi * node-es100 默認情況下,集羣中的每個節點都可以處理HTTP和傳輸流量。傳輸層專門用於節點和外部客戶端之間的通信HTTP層僅由外部REST客戶端使用。所有節點都知道集羣中的所有其他節點,並可以將客戶機請求轉發到適當的節點。
根據節點的用途可分爲以下幾類:
- Master-eligible node: 可成爲主節點的候選節點,任何主節點的候選節點(默認情況下是所有節點)都可以通過主選擇過程被選爲主節點。
- Data node:數據節點保存包含已索引的文檔的分片。數據節點處理與數據相關的操作,如CRUD、搜索和聚合。這些操作是I/O、內存和cpu密集型的。監視這些資源並在它們過載時添加更多的數據節點以擴展容量。擁有專用數據節點的主要好處是控制面和數據面的分離。
- Ingest node:Ingest節點可以執行由一個或多個Ingest處理器組成的預處理管道。根據ingest處理器執行的操作類型和所需的資源,設置專門執行特定任務的ingest節點是有意義的。
- Tribe node:使用tribe.*配置的tribe節點,是一種特殊類型的用於協調的節點,它可以連接到多個集羣,並跨所有連接的集羣執行搜索和其他操作。
默認情況下,每個節點都是是候選主節點和數據節點,並且它可以通過Ingest管道對文檔進行預處理。但是隨着集羣的增長,可考慮將符合主控條件的專用節點與專用數據節點分離。
如果去掉處理主控、數據保存和文檔預處理的能力,那麼節點就只剩下一個協調功能,只能路由請求、處理請求。從本質上講,只有協調節點才能充當智能負載平衡器。
不同類型的節點可用一組屬性來確定,如下表所示:
| 節點類型 | 屬性定義 |
|---|---|
| Master-eligible node | node.master: true,node.data: false,node.ingest: false,cluster.remote.connect: false |
| Data node | node.master: false,node.data: true,node.ingest: false,cluster.remote.connect: false |
| Ingest node | node.master: false,node.data: false,node.ingest: true,cluster.remote.connect: false |
| Coordinating only node | node.master: false,node.data: false,node.ingest: false,cluster.remote.connect: false |
1.2. 發現機制
ES集羣中的發現模塊負責發現集羣中的節點,以及選擇主節點。
Elasticsearch是一個基於點對點的網絡系統,節點之間可以直接通信。所有的主要api(index, delete, search)都不與主節點通信。主節點的職責是維護全局集羣狀態,並在節點動態改變時重新分配分片。集羣狀態的變更會被通知到集羣中的其他節點。
ES集羣支持Azure Classic Discovery、EC2 Discovery、Google Compute Engine Discovery三種外部發現機制,通過對應的插件來實施。
ES內置的發現機制爲Zen Discovery機制,提供了多播和單播兩種發現方式。
Ping是一個ES節點使用發現機制發現其它節點的進程,一個集羣中的節點應該配置相同的集羣名稱。使用ping進程,多播發現的方式通過向其他節點發送一個或多個多播請求來實現,單播方式下,需要提供一個主機列表(稱爲Seed nodes)作爲路由列表。
一個elasticsearch.yml文件中配置集羣的示例如下:
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: zkes_cluster
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-es100
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.zen.ping.unicast.hosts: ["192.168.127.100", "192.168.127.101"]單播發現依賴transport模塊實現。注意port默認應該是9300,不是9200,因爲使用的是tranposrt。
1.3. 選舉機制
主節點通過同一集羣中的候選主節點集合選舉產生,每個候選主節點讀取自己獲得的候選主節點列表,並選舉該列表按節點ID排序後的第一個節點作爲主節點。
ES中需要定義參與選舉的候選主節點的最小數目(quorum)。ES認爲quorum應符合下面的要求:
quorum = (number of master-eligible nodes / 2) + 1 例如:集羣中有10個節點,都是候選主節點,則quorum應設置爲6,以保證在選舉主節點時至少有6個候選主節點參與。這樣設置的目的是防止集羣中出現腦裂現象,即集羣中出現兩個或以上的主節點。
集羣中的節點時可以動態變化,因此可在集羣中通過discovery.zen.minimum_master_nodes參數即時更新quorum,示例如下:
PUT /_cluster/settings
{
"persistent" : {
"discovery.zen.minimum_master_nodes" : 2
}
}當主節點停止或遇到問題時,集羣節點將再次發出ping,並選擇一個新的主節點。
2. 數據模型
2.1. Index與document
應用程序中的對象很少僅僅是鍵和值的簡單列表。通常,它們是複雜的數據結構,可能包含日期、地理位置、其他對象或值數組。
ES可以存儲整個對象(或稱爲文檔(document),以下統稱爲文檔,使用JSON進行對象的序列化,一類文檔的集合被稱爲索引(index))。它不僅僅是存儲,還會索引(index)每個文檔的內容使之可以被搜索。在ES中,你可以對文檔(而非成行成列的數據)進行索引、搜索、排序、過濾。
ES中,一個集羣可以包含多個索引,一個索引可以包含多個文檔。如果與RDBMS做比較,則ES中的集羣就相當於一個關係數據庫,而一個索引就相當於一張關係表(6.0版本後已經忽略了type的概念),而一個文檔就相當於表中的一條記錄。
一個文檔不只有數據。它還包含了元數據(metadata)—關於文檔的信息,一個查詢處理的對象的示例如下,它包含了所屬的索引,類型,以及文檔ID:
{
"_index" : "blogs",
"_type" : "articles",
"_id" : "001",
"_score" : 1.0,
"_source" : {
"author" : "zhangkai",
"article_title" : "車夢想家1",
"create_date" : "20190104",
"star" : 6
}
}2.2. 分片(shard)
一個索引中包含多個文檔,在存儲策略上,ES將索引分爲多個分片(shard), 每個分片存儲不同的文檔。
一個索引的分片數目可以在創建索引時設置,在設置完畢後就不可更改了,因爲索引的分片數據涉及到文檔在分配到哪個分片上。
ES定義文檔到分片的分配公式爲:
shard = hash(routing) % number_of_primary_shards 這裏的routing 值是一個任意字符串,它默認是 _id 但也可以自定義。這個 routing 字符串通過哈希函數生成一個數字,然後除以主切片的數量得到一個餘數(remainder),餘數的範圍永遠是 0 到 number_of_primary_shards - 1 ,這個數字就是特定文檔所在的分片。
分片也有主從之分,還記得圖2的集羣架構嗎?這個集羣中某個索引有3個分片,每個主分片有兩個複製分片用於數據複製。
一個主分片帶幾個複製分片可通過在創建索引時設置,設置的命令格式示例如下:
{
"settings":{
"number_of_shards":3,
"number_of_replicas":2
}
}3. 數據讀寫
3.1. 讀寫過程
集羣中每個節點都有能力處理任意請求。每個節點都知道任意文檔所在的節點,所以也可以將請求轉發到需要的節點。這類接受請求並協調的節點稱爲協調節點(coordinating node)。如搜索請求分兩個階段執行,由接收客戶機請求的節點協調: 在分散階段,協調節點將請求轉發給保存數據的數據節點。每個數據節點在本地執行請求,並將其結果返回給協調節點。在收集階段,協調節點將每個數據節點的結果縮減爲單個全局結果集。
因此在發送請求時,最好對集羣中的所有節點進行輪詢,以分散負載。
對於寫數據操作,必須在主分片上成功完成才能複製到相關的複製分片上。
仍使用文獻2中的圖來介紹這一過程: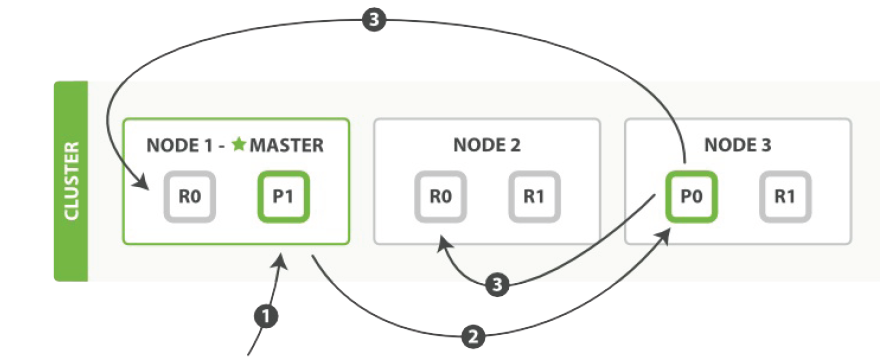
上圖中的寫過程描述如下:
1. 客戶端向node1發送寫操作請求(如CUD一個文檔)。
2. Node1根據文檔的路由標識(如_id)確定該文檔應寫到P0分片上,於是向node3發送請求。
3. node3上的P0處理請求,寫完畢後,將寫入數據複製到node1和node2上的RO,完成數據複製。
ES的寫操作可分爲同步(默認方式)與異步兩種方式:在同步方式下,客戶端要等到數據在所有分片上覆制完成後才能收到請求迴應;在異步方式下,客戶端只要在主分片上完成寫操作後就能夠得到請求迴應。
對於讀數據操作,可從主分片和任一複製分片讀取。
仍使用文獻2中的圖來介紹這一過程:
上圖中的寫過程描述如下:
1. 客戶端向node1發送讀操作請求(如R一個文檔)。
2. Node1根據文檔的路由標識(如_id)確定該文檔存放在分片0上,這時node1,node2,node3上都有分片0,node1通過自己的負載均衡算法(一般使用循環輪轉算法)確定本次由node2處理請求,並將讀操作請求發送到node2。
3. Node2上的R0處理讀請求完畢後,將結果返回給node1,node1再返回給客戶端。
3.2. 如何將數據寫到同一個分片
ES在某些應用場景下要求不同文檔保存在同一分片中(如映射爲父子關係的文檔),而爲了搜索效率將語義強相關的文檔放到同一分片中也很有必要。
還記得前面我們講過一個文檔保存到哪個分片是由它的routing值提供的,那麼在寫入文檔時ES允許設置routing值(讀數據時也可設置,這樣ES只在指定的分片上檢索,可以提高效率),寫入不同文檔時設置爲相同的routing值就可保證這些文檔保存在同一分片上。
如下面的命令:
curl -iXPOST 'localhost:9200/bank/account/1000?routing=Dillard&pretty' -H 'Content-Type: application/json' -d'
{"firstname":"Dillard"}
'這裏的routing爲字符串形式,可以取個好記的名字。
3.3. 數據訪問中的臨界區問題
數據訪問中我們常常會遇到數據臨界區問題。如一個電商應用中,對於銷售量變量,一次交易首先會從數據庫中讀出當前銷售量,然後將當前銷售量加上交易中的交易數目,然後寫到數據庫中銷售量變量中。如果多個客戶端同時交易,交易時不鎖定包含銷售量變量的臨界區,就發發生衝突,導致銷售量沒有正確統計。
ES中對於臨界區問題的處理本身並沒有提供所謂的鎖定機制(悲觀併發控制,Pessimistic concurrency control),需要由調用的客戶端自行解決,解決方法的依據就是使用文檔的版本號(_version)。
ES中每個文檔都有一個 _version,這個_version在文檔被改變時加1,創始創建時也爲1。
查看如下修改後的操作結果:
{
"_index" : "bank",
"_type" : "account",
"_id" : "_doc",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 198,
"_primary_term" : 3
}爲避免出現臨界區問題,在修改一個文檔時,首先查詢出該文檔的_version,然後再修改請求中攜帶該_version,如下示例所示:
curl -iXPOST 'localhost:9200/bank/account/1000? version=1' -H 'Content-Type: application/json' -d'
{"firstname":"Dillard"} ES如果發現當前該文檔的_version已經大於1(其它客戶端已經修改了該文檔),則會迴應該修改請求失敗。客戶端可再次讀取當前文檔的_version實施修改。
這種處理方式被稱爲樂觀併發控制(Optimistic concurrency control)。
4. 參考文獻
- https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
- Clinton Gormley &Zachary Tong, Elasticsearch: The Definitive Guide,2015