




介 紹
Etcd是一個開源的分佈式鍵值存儲,它由CoreOS團隊開發,現在由Cloud Native Computing Foundation負責管理。這個詞的發音是“et-cee-dee”,表示在多臺機器上分發Unix系統的“/etc”目錄,其中包含了大量的全局配置文件。它是許多分佈式系統的主幹,爲跨服務器集羣存儲數據提供可靠的方式。它適用於各種操作系統,包括Linux、BSD和OS X。
Etcd具有下面這些屬性:
完全複製:集羣中的每個節點都可以使用完整的存檔
高可用性:Etcd可用於避免硬件的單點故障或網絡問題
一致性:每次讀取都會返回跨多主機的最新寫入
簡單:包括一個定義良好、面向用戶的API(gRPC)
安全:實現了帶有可選的客戶端證書身份驗證的自動化TLS
快速:每秒10000次寫入的基準速度
可靠:使用Raft算法實現了存儲的合理分佈
Etcd的工作原理
在理解Etcd的工作機制之前,我們先定義三個關鍵概念:leaders、elections以及terms。在一個基於Raft的系統中,集羣使用election爲給定的term選擇leader。
Leader處理所有需要集羣一致協商的客戶端請求。不需要一致協商的請求(如讀取)可以由任何集羣成員處理。Leader負責接受新的更改,將信息複製到follower節點,並在follower驗證接受後提交更改。每個集羣在任何給定的時間內只能有一個leader。
如果leader掛了或者不再響應了,那麼其他節點將在預定的時間超時之後開啓一個新的term來創建新election。每個節點維護一個隨機的election計時器,該計時器表示節點在調用新的election以及選擇自己作爲候選之前需要等待的時間。
如果節點在超時發生之前沒有收到leader的消息,則該節點將通過啓動新的term、將自己標記爲候選,並要求其他節點投票來開始新的election。每個節點投票給請求其投票的第一個候選。如果候選從集羣中的大多數節點處獲得了選票,那麼它就成爲了新的leader。但是,如果存在多個候選且獲得了相同數量的選票,那麼現有的election term將在沒有leader的情況下結束,而新的term將以新的隨機選舉計時器開始。
如上所述,任何更改都必須連接到leader節點。Etcd沒有立即接受和提交更改,而是使用Raft算法確保大多數節點都同意更改。Leader將提議的新值發送到集羣中的每個節點。然後,節點發送一條消息確認收到了新值。如果大多數節點確認接收,那麼leader提交新值,並向每個節點發送將該值提交到日誌的消息。這意味着每次更改都需要得到集羣節點的仲裁才能提交。
Kubernetes中的Etcd
自從2014年成爲Kubernetes的一部分以來,Etcd社區呈現指數級的增長。CoreOS、谷歌、Redhat、IBM、思科、華爲等等均是Etcd的貢獻成員。其中AWS、谷歌雲平臺和Azure等大型雲提供商成功在生產環境中使用了Etcd。
Etcd在Kubernetes中的工作是爲分佈式系統安全存儲關鍵數據。它最著名的是Kubernetes的主數據存儲,用於存儲配置數據、狀態和元數據。由於Kubernetes通常運行在幾臺機器的集羣上,因此它是一個分佈式系統,需要Etcd這樣的分佈式數據存儲。
Etcd使得跨集羣存儲數據和監控更改變得更加容易,它允許來自Kubernetes集羣的任何節點讀取和寫入數據。Kubernetes使用Etcd的watch功能來監控系統實際(actual)狀態或期望(desired)狀態的變化。如果這兩個狀態不同,Kubernetes會做出一些改變來調和這兩個狀態。kubectl命令的每次讀取都從Etcd存儲的數據中檢索,所做的任何更改(kubectl apply)都會在Etcd中創建或更新條目,每次崩潰都會觸發etcd中值的修改。
部署以及硬件建議
出於測試或開發目的,Etcd可以在筆記本電腦或輕量雲上運行。然而,在生產環境中運行Etcd集羣時,我們應該考慮Etcd官方文檔提供的指導。它爲良好穩定的生產部署提供了一個良好的起點。需要留意的是:
Etcd會將數據寫入磁盤,因此強烈推薦使用SSD
始終使用奇數個集羣數量,因爲需要通過仲裁來更新集羣的狀態
出於性能考慮,集羣通常不超過7個節點
讓我們回顧一下在Kubernetes中部署Etcd集羣所需的步驟。之後,我們將演示一些基本的CLI命令以及API調用。我們將結合Kubernetes的概念(如StatefulSets和PersistentVolume)進行部署。
預先準備
在繼續demo之前,我們需要準備:
一個谷歌雲平臺的賬號:免費的tier應該足夠了。你也可以選擇大多數其他雲提供商,只需進行少量修改即可。
一個運行Rancher的服務器
啓動Rancher實例
在你控制的服務器上啓動Rancher實例。這裏有一個非常簡單直觀的入門指南:https://rancher.com/quick-start/
使用Rancher部署GKE集羣
參照本指南使用Rancher在GCP賬戶中設置和配置Kubernetes集羣:
https://rancher.com/docs/rancher/v2.x/en/cluster-provisioning/hosted-kubernetes-clusters/gke/
在運行Rancher實例的同一服務器上安裝Google Cloud SDK以及kubelet命令。按照上面提供的鏈接安裝SDK,並通過Rancher UI安裝kubelet。
使用gcloud init和gcloud auth login,確保gcloud命令能夠訪問你的GCP賬戶。
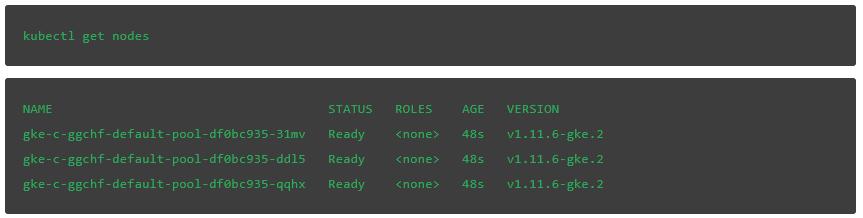
集羣部署後,輸入下面的命令檢查基本的kubectl功能:
在部署Etcd集羣(通過kubectl或在Rancher的UI中導入YAML文件)之前,我們需要配置一些項。在GCE中,默認的持久化磁盤是pd-standard。我們將爲Etcd部署配置pd-ssd。這不是強制性的,不過根據Etcd的建議,SSD是非常好的選擇。查看此鏈接可以瞭解其他雲提供商的存儲類:
https://kubernetes.io/docs/concepts/storage/storage-classes/
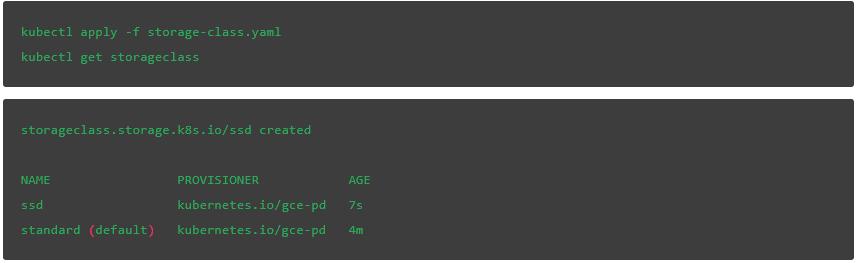
讓我們檢查一下GCE提供的可用存儲類。正如預期的那樣,我們看到了一個默認的結果,叫做standard:

應用下面這個YAML文件,更新zone的值來匹配你的首選項,這樣我們就可以使用SSD存儲了:

我們再一次檢查,可以看到,除了默認standard類之外,ssd也可以使用了:
現在我們可以繼續部署Etcd集羣了。我們將創建一個帶有3個副本的StatefulSet,每個副本都有一個ssd storageClass的專用卷。我們還需要部署兩個服務,一個用於內部集羣通信,一個用於通過API從外部訪問集羣。
在搭建集羣時,我們需要將一些參數傳遞給Etcd二進制文件再到數據存儲中。Listen-client-urls和listen-peer-urls選項指定Etcd服務器用於接受傳入連接的本地地址。指定0.0.0.0作爲IP地址意味着Etcd將監聽所有可用接口上的連接。Advertise-client-urls和initial-advertise-peer-urls參數指定了在Etcd客戶端或者其他Etcd成員聯繫etcd服務器時應該使用的地址。
下面的YAML文件定義了我們的兩個服務以及Etcd StatefulSe圖:
# etcd-sts.yaml---
apiVersion: v1
kind: Service
metadata:
name: etcd-client
spec:
type: LoadBalancer
ports:
- name: etcd-client
port: 2379
protocol: TCP
targetPort: 2379
selector:
app: etcd
---
apiVersion: v1
kind: Service
metadata:
name: etcd
spec:
clusterIP: None
ports:
- port: 2379
name: client
- port: 2380
name: peer
selector:
app: etcd
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: etcd
labels:
app: etcd
spec:
serviceName: etcd
replicas: 3
template:
metadata:
name: etcd
labels:
app: etcd
spec:
containers:
- name: etcd
image: quay.io/coreos/etcd:latest
ports:
- containerPort: 2379
name: client
- containerPort: 2380
name: peer
volumeMounts:
- name: data
mountPath: /var/run/etcd
command:
- /bin/sh
- -c
- | PEERS="etcd-0=http://etcd-0.etcd:2380,etcd-1=http://etcd-1.etcd:2380,etcd-2=http://etcd-2.etcd:2380"
exec etcd --name ${HOSTNAME} \
--listen-peer-urls http://0.0.0.0:2380 \
--listen-client-urls http://0.0.0.0:2379 \
--advertise-client-urls http://${HOSTNAME}.etcd:2379 \
--initial-advertise-peer-urls http://${HOSTNAME}:2380 \
--initial-cluster-token etcd-cluster-1 \
--initial-cluster ${PEERS} \
--initial-cluster-state new \
--data-dir /var/run/etcd/default.etcd
volumeClaimTemplates:
- metadata:
name: data
spec:
storageClassName: ssd
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
輸入下列命令應用YAML:

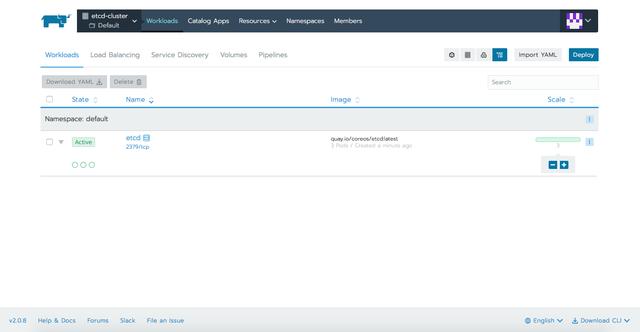
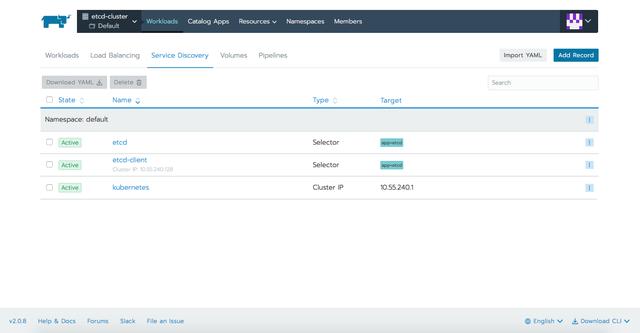
在應用YAML文件後,我們可以在Rancher提供的不同選項卡中定義資源:
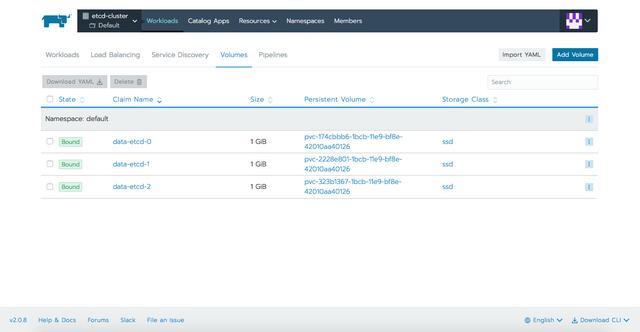
與Etcd交互
與Etcd交互的方式主要有兩種:使用etcdctl命令或者直接通過RESTful API。我們將簡要介紹這兩種方法,不過你還可以通過訪問這裏和這裏的完整文檔找到更加深入的信息和示例。
Etcdctl是一個和Etcd服務器交互的命令行接口。它可以用於執行各種操作,如設置、更新或者刪除鍵、驗證集羣健康情況、添加或刪除Etcd節點以及生成數據庫快照。默認情況下,etcdctl使用v2 API與Etcd服務器通信來獲得向後兼容性。如果希望etcdctl使用v3 API和Etcd通信,則必須通過ETCDCTL_API環境變量將版本設置爲3。
對於API,發送到Etcd服務器的每一個請求都是一個gRPC遠程過程調用。這個gRPC網關提供一個RESTful代理,能夠將HTTP/JSON請求轉換爲gRPC消息。
讓我們來找到API調用所需的外部IP:
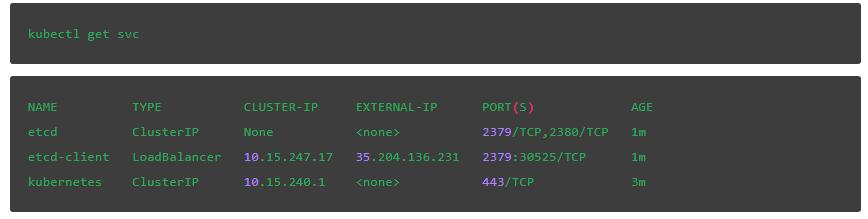
我們應該還能找到3個pods的名稱,這樣我們就可以使用etcdctl命令:

我們檢查Etcd版本。爲此我們可以使用API或CLI(v2和v3).根據你選擇的方法, 輸出的結果將略有不同。
使用此命令可直接與API聯繫:

檢查API版本爲v2的etcdctl客戶端,輸入:

檢查API版本爲v3的etcdctl客戶端,則輸入:

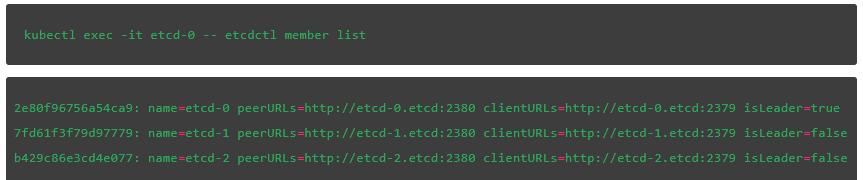
接下來,列出集羣成員,就像我們上面做的那樣:

{"members":[{"id":"2e80f96756a54ca9","name":"etcd-0","peerURLs":["http://etcd-0.etcd:2380"],"clientURLs":["http://etcd-0.etcd:2379"]},{"id":"7fd61f3f79d97779","name":"etcd-1","peerURLs":["http://etcd-1.etcd:2380"],"clientURLs":["http://etcd-1.etcd:2379"]},{"id":"b429c86e3cd4e077","name":"etcd-2","peerURLs":["http://etcd-2.etcd:2380"],"clientURLs":["http://etcd-2.etcd:2379"]}]}
V2版本的etcdctl:
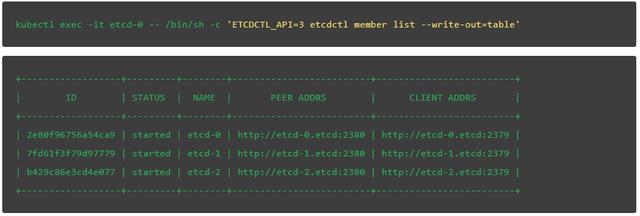
V3版本的etcdctl:
在Etcd中設置和檢索值
下面我們將介紹的最後一個示例是在Etcd集羣中全部3個pods上創建一個鍵並檢查其值。然後我們會殺掉leader,在我們的場景中是etcd-0,然後來看看新的leader是如何選出來的。最後,在集羣恢復之後,我們將在所有成員上驗證之前創建的鍵的值。我們會看到,沒有數據丟失的情況發生,集羣只是換了一個leader而已。
我們可以通過輸入下面的命令來驗證集羣最初是健康的:
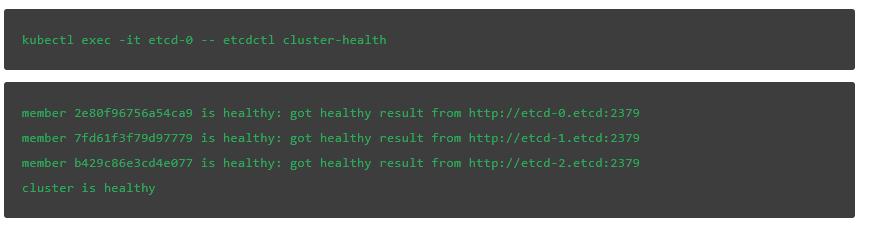
接下來,驗證當前leader。最後一個字段表明etcd-0是我們集羣中的leader:
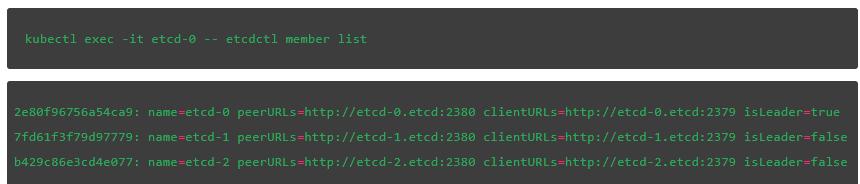
使用該API,我們將創建一個名爲message的鍵並給它分配一個值,請記住在下面的命令中把IP地址替換爲你在集羣中通過下面命令獲取到的地址:

無論查詢哪個成員,鍵都具有相同的值。這幫助我們驗證值是否已經複製到其他節點並提交到日誌。
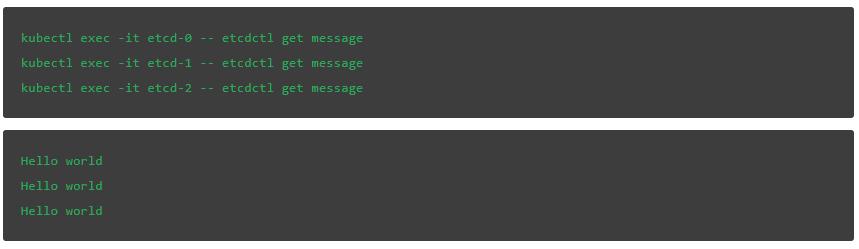
演示高可用性和恢復
接下來,我們可以殺掉Etcd集羣leader。這樣我們可以看到新的leader是如何選出的,以及集羣如何從degraded狀態中恢復過來。刪除與上面發現的Etcd leader相關的pod:

下面我們檢查一下集羣的健康情況:

failed to check the health of member 2e80f96756a54ca9 on http://etcd-0.etcd:2379: Get http://etcd-0.etcd:2379/health: dial tcp: lookup etcd-0.etcd on 10.15.240.10:53: no such host
member 2e80f96756a54ca9 is unreachable: [http://etcd-0.etcd:2379] are all unreachable
member 7fd61f3f79d97779 is healthy: got healthy result from http://etcd-1.etcd:2379
member b429c86e3cd4e077 is healthy: got healthy result from http://etcd-2.etcd:2379cluster is degraded
command terminated with exit code 5
上面的信息表明,由於失去了leader節點,集羣出於degrade狀態。
一旦Kubernetes通過啓動新實例來響應刪除的pod,Etcd集羣應該就恢復過來了:
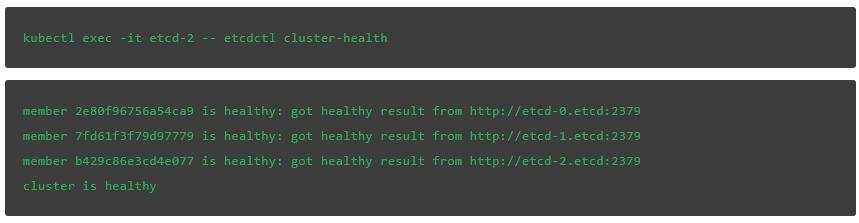
輸入下面指令,我們可以看到新的leader已經選出來了:
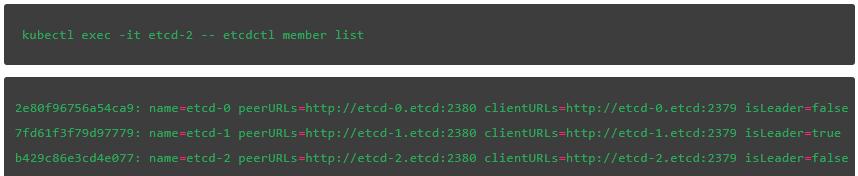
在我們的例子中,etcd-1節點被選爲leader
如果我們再一次檢查message鍵的值,會發現沒有出現數據的損失:
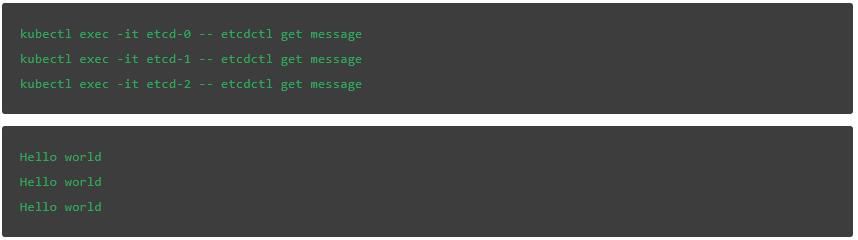
結 論
Etcd是一種非常強大、高可用以及可靠的分佈式鍵值存儲,專門爲特定用例設計。常見的例子包括存儲數據哭連接細節、緩存設置、特性標記等等。它被設計成順序一致的,因此在整個集羣中每個事件都是以相同的順序存儲。
我們瞭解瞭如何在Rancher的幫助下用Kubernetes建立並運行etcd集羣。之後,我們能夠使用一些基本的Etcd命令進行操作。爲了更好的瞭解這個項目,鍵是如何組織的,如何爲鍵設置TTLs,或者如何備份所有數據,參考官方的Etcd repo會是個不錯的選擇:
https://github.com/etcd-io/etcd/tree/master/Documentation