




摘要: 在Kubernetes服務化、日誌處理實時化以及日誌集中式存儲趨勢下,Kubernetes日誌處理上也遇到的新挑戰,包括:容器動態採集、大流量性能瓶頸、日誌路由管理等問題。本文介紹了“Logtail + 日誌服務 + 生態”架構,介紹了:Logtail客戶端在Kubernetes日誌採集場景下的優勢;日誌服務作爲基礎設施一站式解決實時讀寫、HTAP兩大日誌強需求;日誌服務數據的開放性以及與雲產品、開源社區相結合,在實時計算、可視化、採集上爲用戶提供的豐富選擇。
Kubernetes日誌處理的趨勢與挑戰
Kubernetes的serveless化
Kubernetes容器技術促進了技術棧的去耦合,通過引入棧的分層使得開發者可以更加關注自身的應用程序和業務場景。從Kubernetes本身來看,這個技術解耦也在更進一步發展,容器化的一個發展的趨勢是:這些容器都將會在無服務器的基礎設施上運行。
談到基礎設施,首先可以聯想到雲,目前在AWS、阿里雲、Azure的雲上都提供了無服務器化的Kubernetes服務。在serverless Kubernetes上,我們將不再關心集羣與機器,只需要聲明容器的鏡像、CPU、內存、對外服務方式就可以啓動應用。
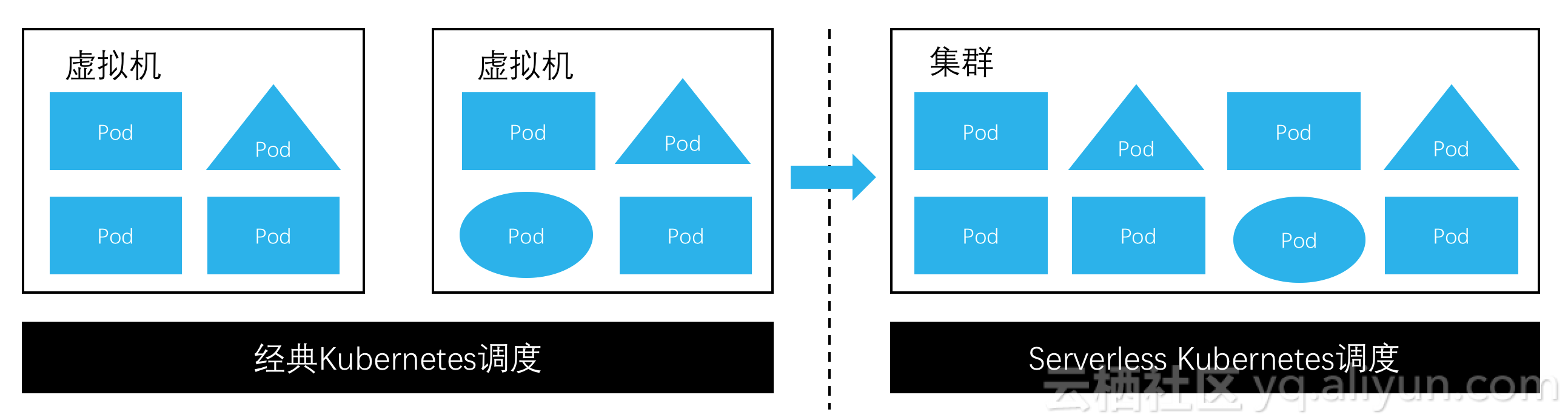
如上圖,左右兩邊分別是經典Kubernetes、serverless Kubernetes的形態。在從左向右發展的過程中,日誌採集也變得複雜:
在一個Kubernetes node上,可能會運行更大規模量級的pod,每個pod上都可能有日誌或監控指標採集需求,意味着單node上的日誌量會更大。
一個Kubernetes node上可能會運行更多種類的pod,日誌採集來源變得多樣化,各類日誌的管理、打標需求越來越迫切。
日誌實時性需求越來越強
首先要強調的是,並非所有日誌都需要實時處理,當前很多"T+1"時效的日誌交付依然非常重要,比如:做BI可能天級別延遲足夠,ctr預估可能1小時延遲的日誌也可以。
但是,在有些場景下,秒級或更高時效性的日誌是必備前提條件,下圖橫座標從左到右的對比展示了數據實時性對於決策的重要性。
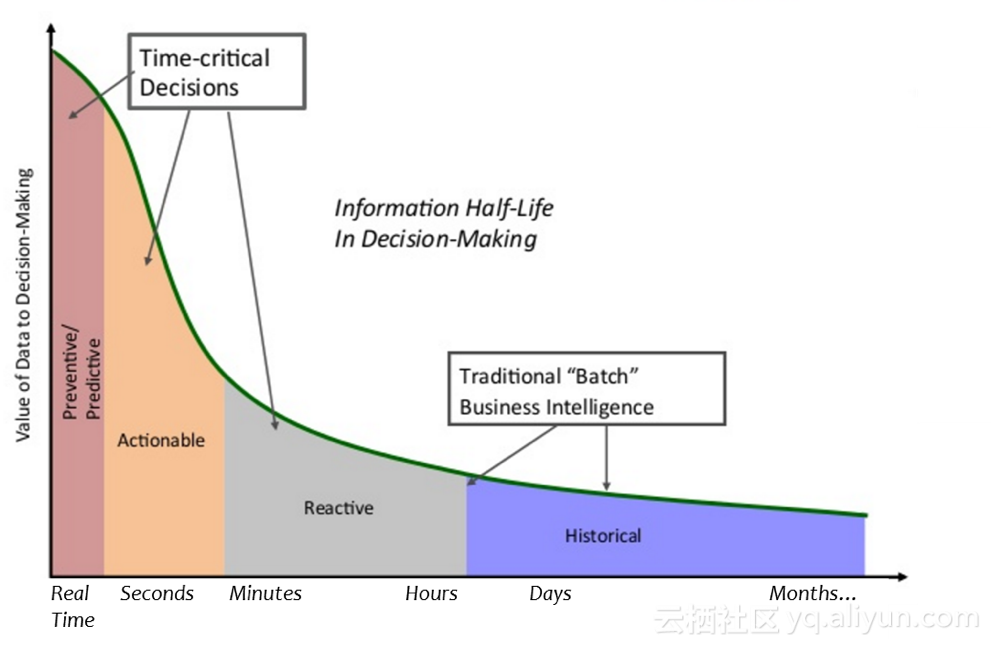
舉兩個場景來談一下實時日誌對於決策的重要性:
告警處理。搞devops同學都深有體會,線上問題越早發現、越早處理我們就可以更淡定,處理時間拖得久了故障就可能跟着升級。實時日誌幫助我們更快發現系統的異常指標,觸發應急處理流程。
AIOps。目前已經有一些算法基於日誌做異常點檢測、趨勢預測:根據日誌的pattern變化態勢發現正常和異常情況下各類型日誌出現的分佈;針對IT業務系統,給定參數因子、變量對諸如硬盤故障等問題進行建模,加以實時日誌來實現故障事件預警。
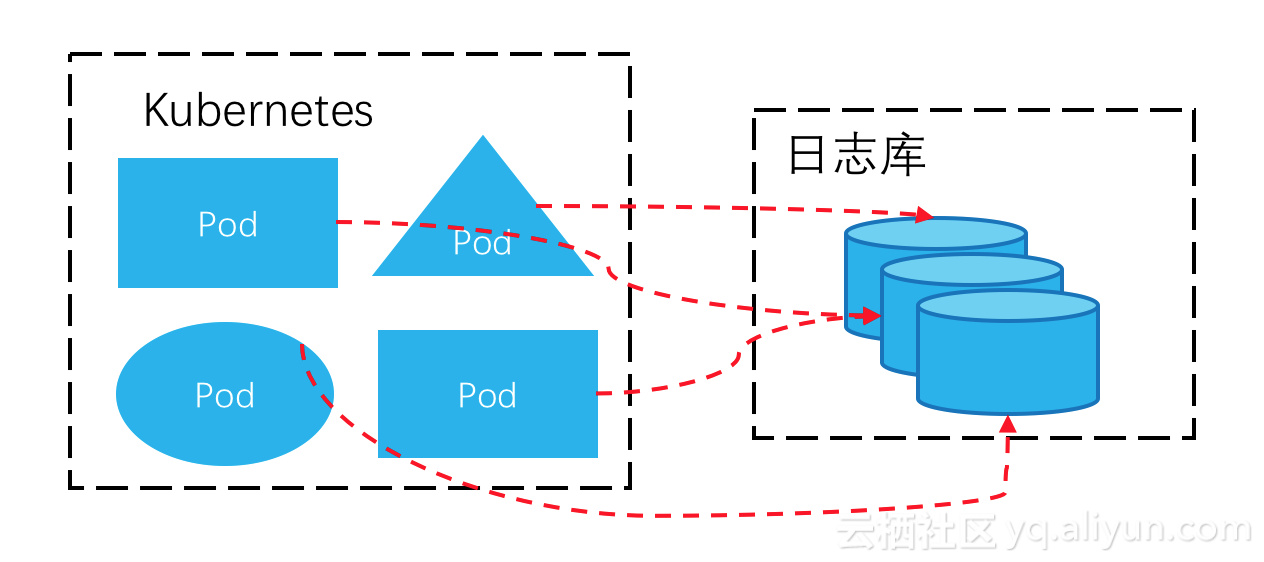
日誌的集中式存儲
日誌來源有很多,常見的有:文件,數據庫audit log,網絡數據包等等。並且,針對同一份數據,對於不同的使用者(例如:開發、運維、運營等)、不同的用途(例如:告警、數據清洗、實時檢索、批量計算等),存在使用多種方式重複消費日誌數據的情況。
在日誌數據的系統集成上,從數據源到存儲節點再到計算節點,可以定義爲一個pipeline。如下圖,從上到下的變化是:日誌處理正在從O(N^2) pipelines向O(N) pipelines演進。
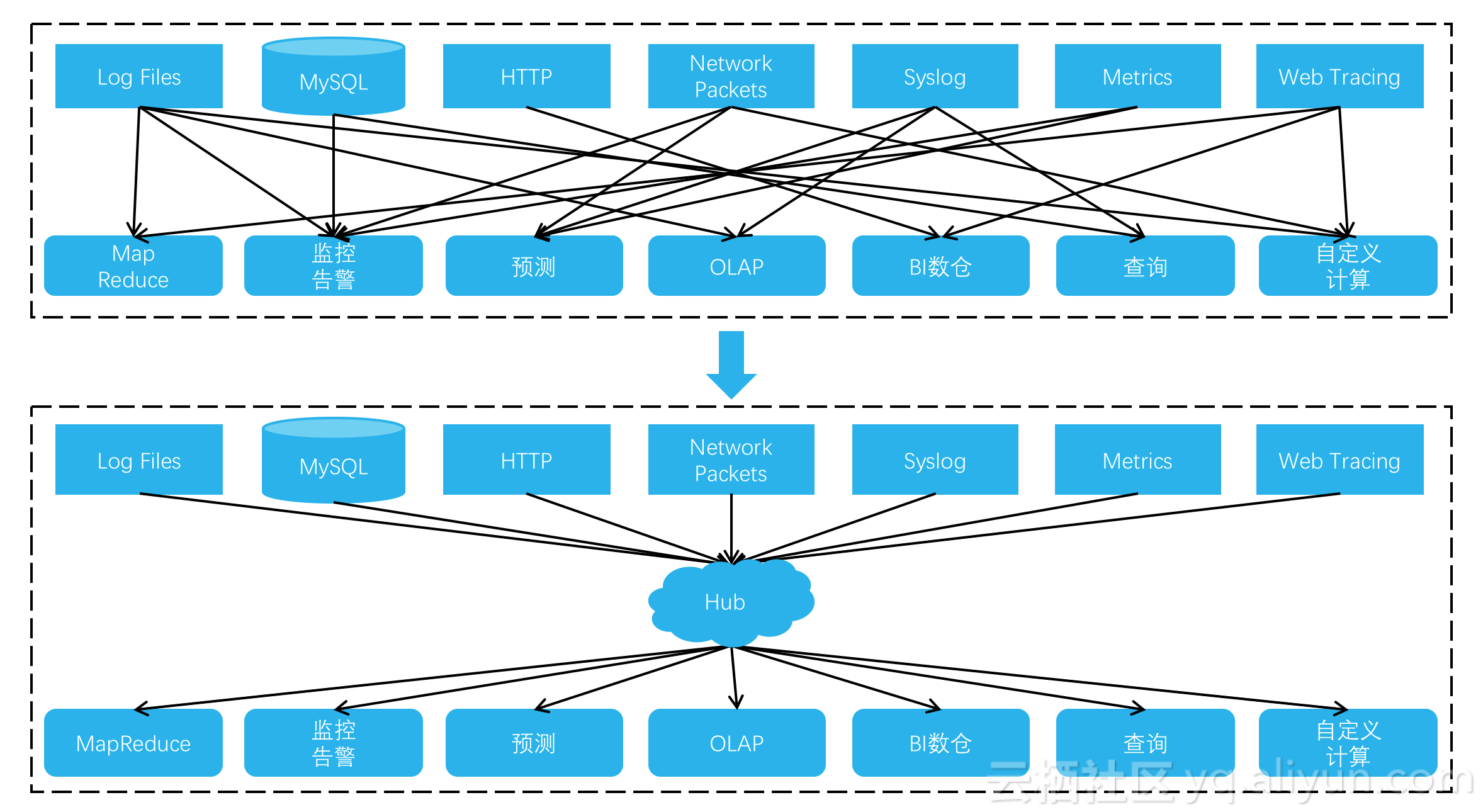
在過去,各類日誌用特定的方式來存儲,採集到計算鏈路不具被通用和複用條件,pipeline非常複雜,數據存儲也可能重複冗餘。當前日誌數據集成上,通過依賴一箇中樞(Hub)來簡化日誌架構的複雜度、優化存儲利用率。這個基礎設施級別的Hub非常重要,需要支持實時pub/sub,能夠處理高併發的寫入、讀取請求,提供海量的存儲空間。
Kubernetes日誌採集方案的演進
前面一節總結了Kubernetes日誌處理上的趨勢,那麼家下來會盤點一下Kubernetes上幾種常見日誌採集的做法。
命令行工具
Kubernetes集羣上要看日誌,最基礎的做法就是登機器,運行kubectl logs就可以看到容器寫出的stdout/stderr。
基礎的方案沒法滿足更多需求:
只支持標準輸出
數據不能持久化
除了看做不了別的事
節點日誌文件落盤
在Kubernetes node維度去處理日誌,docker engine將容器的stdout/stderr重定向到logdriver,並且在logdriver上可以配置多種形式去持久化日誌,比如以json格式保存文件到本地存儲。
和kubectl命令行相比,更進一步是把日誌做到了本地化存儲。可以用grep/awk這些Linux工具去分析日誌文件內容。
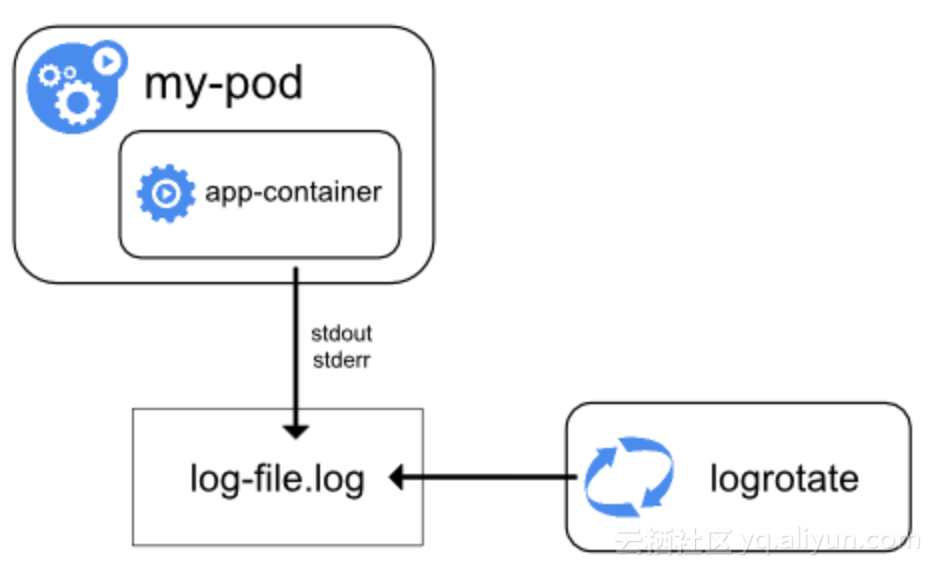
這個方案相當於回到了物理機時代,但仍然存在很多問題沒有解決:
基於docker engine和logdriver,除了默認的標準輸出,不支持應用程序的日誌
日誌文件rotate多次或者Kubernetes node被驅逐後數據會丟失
沒法跟開源社區、雲上的數據分析工具集成
基於這個方案的一個進化版本是在node上部署日誌採集客戶端,將日誌上傳到中心化日誌存儲的設施上去。目前這也是推薦的模式,會在下一節再做介紹。
sidecar模式日誌客戶端採集
一種伴生模式,在一個pod內,除了業務容器外,還有一個日誌客戶端容器。這個日誌客戶端容器負責採集pod內容器的標準輸出、文件、metric數據上報服務端。
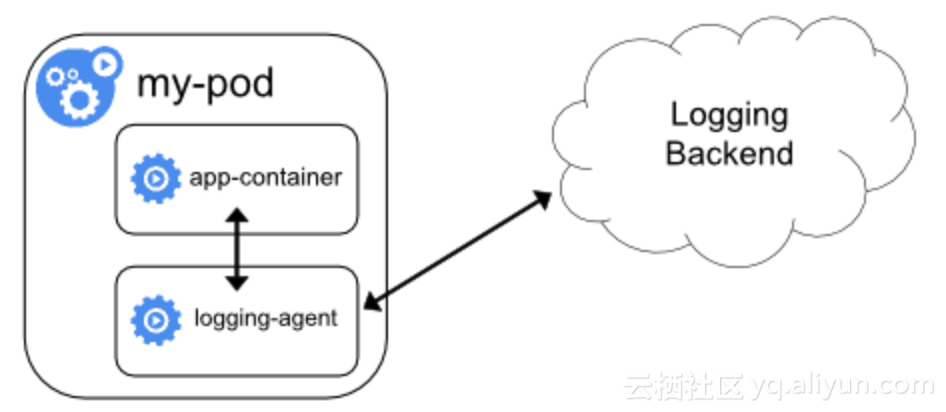
這個方案解決了日誌持久化存儲等基本的功能需求,但兩個地方有待提升:
一個節點上如果運行了N個pod,就意味着會同時運行着N個日誌客戶端,造成CPU、內存、端口等資源的浪費。
Kubernetes下需要爲每個pod單獨進行採集配置(採集日誌目錄,採集規則,存儲目標等),不易維護。
日誌直寫
直寫方案一般是通過修改應用程序本身來實現,在程序內部組織幾條日誌,然後調用類似HTTP API將數據發送到日誌存儲後端。
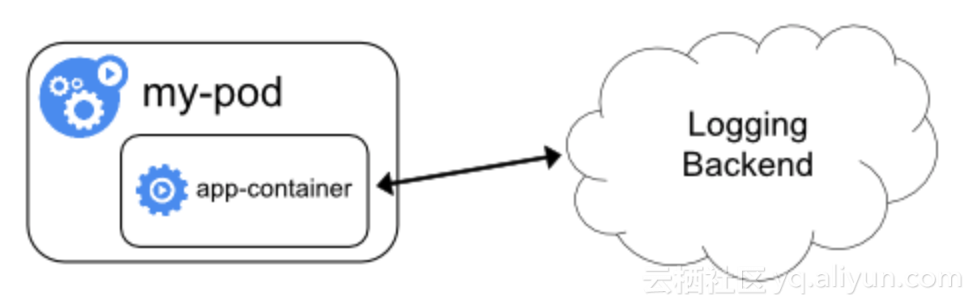
帶來的好處是:日誌格式可以按需DIY,日誌源和目標的路由可以任意配置。
也可以看到使用上的限制:
侵入代碼會對業務改造有直接的依賴,推動業務改造一般比較漫長。
應用程序在發數據到遠端遇到異常(比如網絡抖動,接收服務端內部錯誤)時,需要在有限內存中緩存數據做重試,最終還是有概率造成數據丟失。
Kubernetes日誌處理架構
來自社區的架構
目前見到比較多的架構中,採集工作通過每個Kubernetes node上安裝一個日誌客戶端完成:
Kubernetes官方推薦的是treasure data公司開源的fluentd,它的性能現、插件豐富度比較均衡。
社區有也不少在使用elastic公司開源的beats系列,性能不錯,插件支持略少一些。針對一種數據需要部署特定的客戶端程序,比如文本文件通過filebeats來採集。
也有些架構在使用logstash,ETL支持非常豐富,但是JRuby實現導致性能很差。
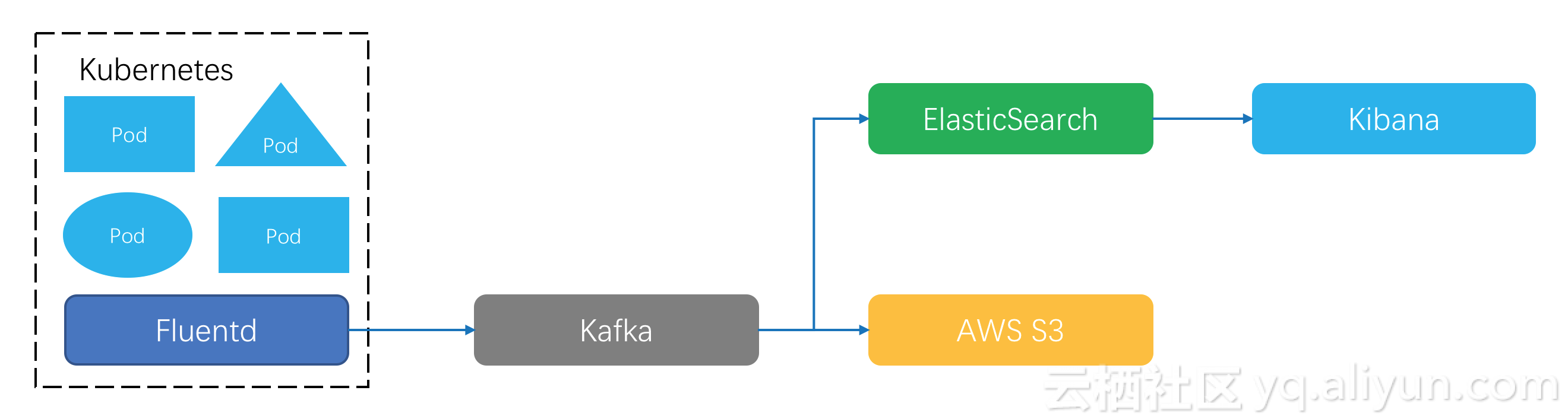
日誌客戶端把數據格式化好之後用指定協議上傳到存儲端,常見的選擇有Kafka。Kafka支持實時訂閱、重複消費,後期可以再根據業務需要把數據同步到其它系統去,比如:業務日誌到Elastic Search做關鍵詞查詢,結合Kibana做日誌可視化分析;金融場景日誌要長期留存,可以選擇投遞Kafka數據到AWS S3這樣的高性價比存儲上。
這個架構看起來簡潔有效,但在Kubernetes下距離完美還有些細節問題要解決:
首先,這是一個標準的節點級採集方案,Kubernetes下fluentd等客戶端的程序部署、採集配置管理是個難題,在日誌採集路由、數據打標、客戶端配置等問題沒有針對性優化。
其次,在日誌的消費上,雖然Kafka的軟件生態足夠豐富,但是仍然需要專業人員來維護,要做業務規劃、考慮機器水位、處理硬件損壞。如果要查詢分析日誌,還需要有對Elastic Search系統有足夠了解。我們知道在PB級數據場景下,分佈式系統的性能、運維問題開始凸顯,而駕馭這些開源系統需要很強的專業能力。
日誌服務的Kubernetes日誌架構實踐
我們提出基於阿里雲日誌服務的Kubernetes日誌處理架構,用以補充社區的方案,來嘗試解決Kubernetes場景下日誌處理的一些細節體驗問題。這個架構可以總結爲:“Logtail + 日誌服務 + 生態”。
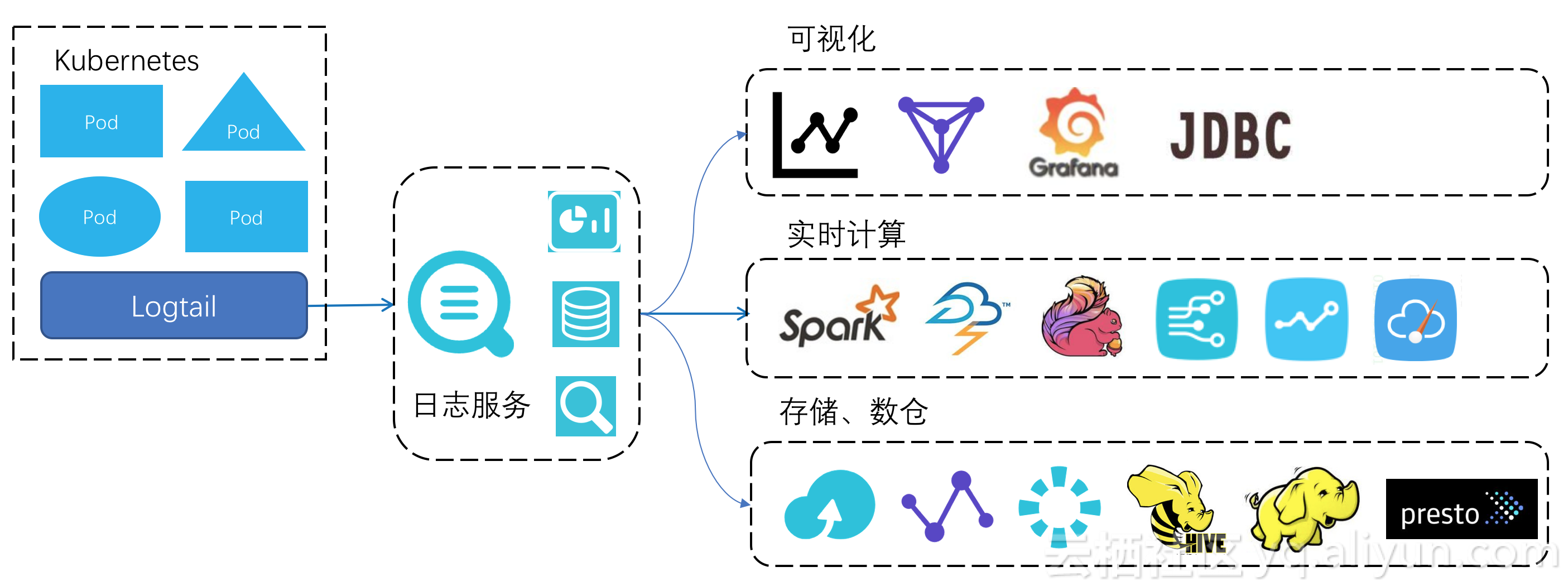
首先,Logtail是日誌服務的數據採集客戶端,針對Kubernetes場景下的一些痛點做了針對性設計。也是按照Kubernetes官方建議的方式,在每個node上只部署一個Logtail客戶端,負責這個node上所有的pod日誌採集。
其次,針對關鍵詞搜索和SQL統計這兩個基本的日誌需求:日誌服務提供了基礎的LogHub功能,支持數據的實時寫入、訂閱;在LogHub存儲的基礎上,可以選擇開啓數據的索引分析功能,開啓索引後可以支持日誌關鍵詞查詢以及SQL語法分析。
最後,日誌服務的數據是開放的。索引數據可以通過JDBC協議與第三方系統對接,SQL查詢結果與諸如阿里雲DataV、開源社區的Grafana系統很方便地集成;日誌服務的高吞吐的實時讀寫能力支撐了與流計算系統的對接,spark streaming、blink、jstorm等流計算系統上都有connector支持;用戶還可以通過全託管的投遞功能把數據寫入到阿里雲的對象存儲OSS,投遞支持行存(csv、json)、列存(parquet)格式,這些數據可以用作長期低成本備份,或者是通過“OSS存儲+E-MapReduce計算”架構來實現數據倉庫。
日誌服務的優勢
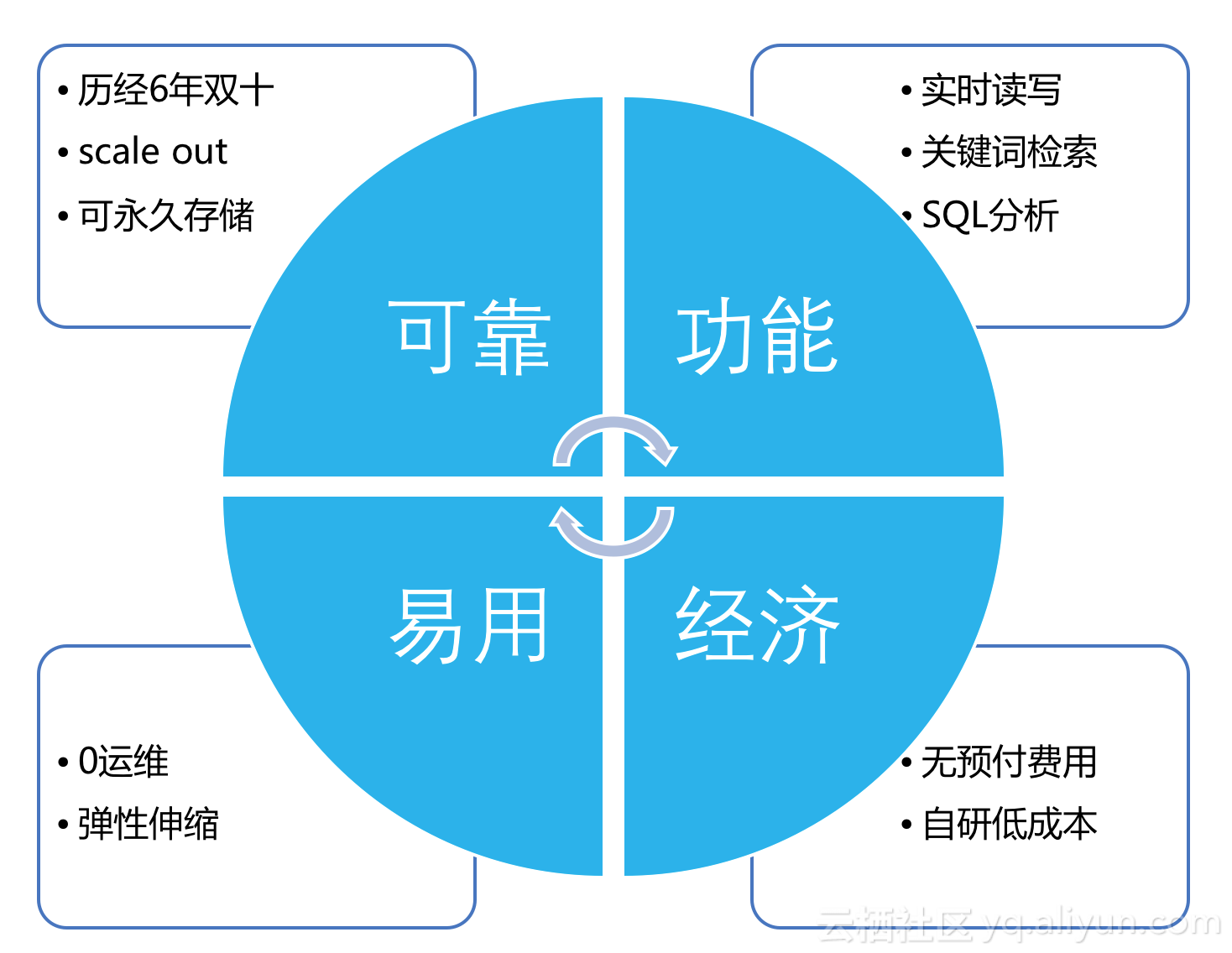
從四個點上來描述日誌服務的特點:
在可靠性和穩定性上,它支撐了阿里集團和螞蟻金服多次雙十一和雙十二的大促。
在功能上一站式覆蓋了Kafka + ElasticSearch大部分場景。
作爲雲上的基礎設施可以方便地實現彈性伸縮,對於用戶來說,大促時不需要操心買機器擴容、每天壞上數十個盤需要維修等問題。
日誌服務也同樣具備雲的0預付成本、按需付費的特點,並且目前每月有500MB的免費額度。
回顧第一節中提到的Kubernetes日誌處理的趨勢與挑戰,這裏總結了日誌服務的三個優勢:
作爲日誌基礎設施,解決了各種日誌數據集中化存儲問題。
服務化的產品帶給用戶更多的易用性,與Kubernetes在serverless的目標上也是契合的。
功能上同時滿足實時讀寫、HTAP需求,簡化了日誌處理的流程與架構。
日誌服務結合社區力量進行Kubernetes日誌分析
Kubernetes源自社區,使用開源軟件進行Kubernetes日誌的處理也是一些場景下的正確選擇。
日誌服務保證數據的開放性,與開源社區在採集、計算、可視化等方面進行對接,幫助用戶享受到社區技術成果。

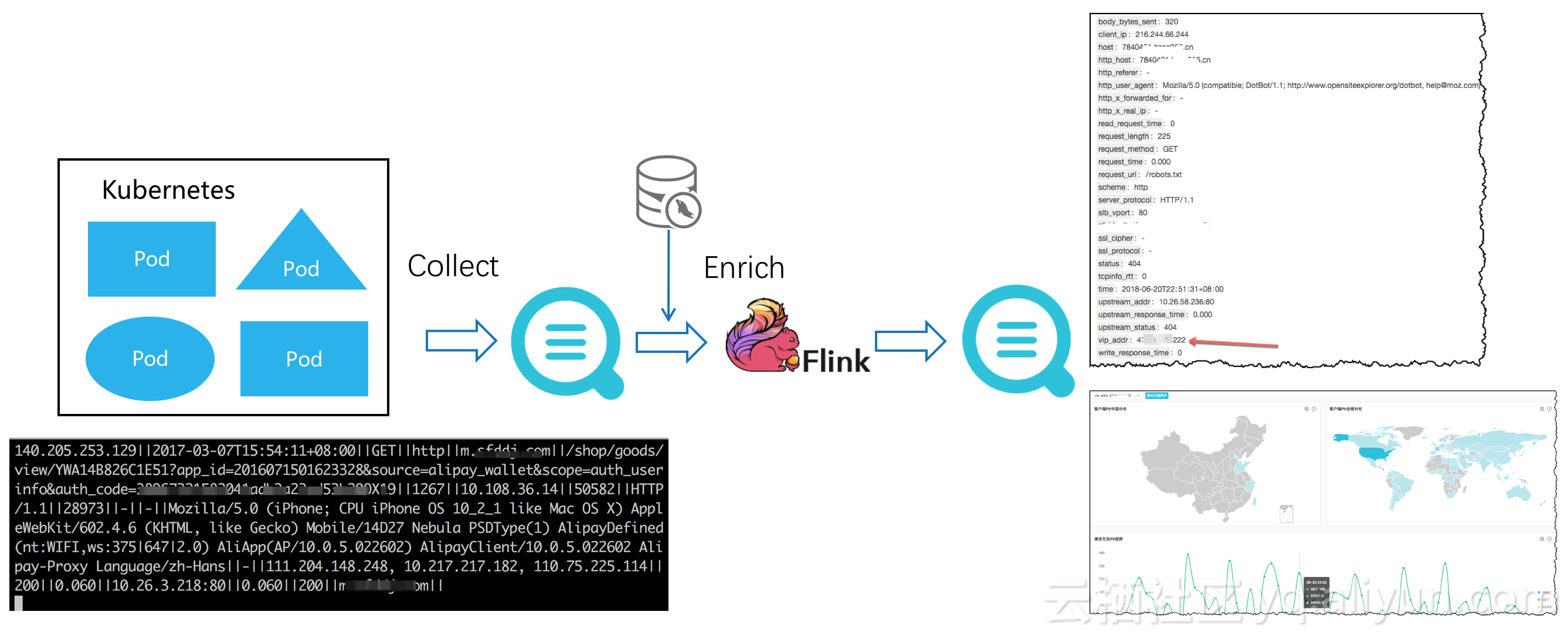
如下圖,舉一個簡單的例子:使用流計算引擎flink實時消費日誌服務的日誌庫數據,源日誌庫的shard併發與flink task實現動態負載均衡,在完成與MySQL的meta完成數據join加工後,再通過connector流式寫入另一個日誌服務日誌庫做可視化查詢。
Logtail在Kubernetes日誌採集場景下的設計
在本文第二節我們回顧了Kubernetes日誌採集方案演進過程中遇到的問題,第三節介紹了基於阿里雲日誌服務的功能、生態。在這一節會重點對Logtail採集端的設計和優化工作做一些介紹,細數Logtail如何解決Kubernetes日誌採集上的痛點。
Kubernetes採集的難點
採集目標多樣化
容器stdout/stderr
容器應用日誌
宿主機日誌
開放協議:Syslog、HTTP等
採集可靠性
性能上需要滿足單node上大流量日誌場景,同時兼顧採集的實時性
解決容器日誌易失性問題
在各種情況下儘量保證採集數據的完整性
動態伸縮帶來的挑戰
容器擴、縮容對自動發現的要求
降低Kubernetes部署的複雜度
採集配置易用性
採集配置怎麼部署、管理
不同用途的pod日誌需要分門別類存儲,數據路由怎麼去管理
Logtail高可靠採集
Logtail支持至少at-least-once採集的語義保證,通過文件和內存兩種級別的checkpoint機制來保證在容器重啓場景下的斷點續傳。
日誌採集過程中可能遇到各種各樣的來自系統或用戶配置的錯誤,例如日誌格式化解析出錯時我們需要及時調整解析規則。Logtail提供了採集監控功能,可以將異常和統計信息上報日誌庫並支持查詢、告警。
優化計算性能解決單節點大規模日誌採集問題,Logtail在不做日誌字段格式化的情況(singleline模式)下做到單cpu核100MB/s左右的處理性能。針對網絡發送的慢IO操作,客戶端將多條日誌batch commit到服務端做持久化,兼顧了採集的實時性與高吞吐能力。
在阿里集團內部,Logtail目前有百萬級規模的客戶端部署,穩定性是不錯的。
豐富的數據源支持
應對Kubernetes環境下複雜多樣的採集需求,Logtail在採集源頭上可以支持:stdout/stderr,容器、宿主機日誌文件,syslog、lumberjack等開放協議數據採集。
將一條日誌按照語義切分爲多個字段就可以得到多個key-value對,由此將一條日誌映射到table模型上,這個工作使得在接下來的日誌分析過程中事半功倍。Logtail支持以下一些日誌格式化方式:
多行解析。比如Java stack trace日誌是由多個自然行組成的,通過行首正則表達式的設置來實現日誌按邏輯行切分。
自描述解析。支持csv、json等格式,自動提取出日誌字段。
通過正則、自定義插件方式滿足更多特定需求。
對於一些典型的日誌提供內置解析規則。比如,用戶只需要在web控制檯上選擇日誌類別是Nginx訪問日誌,Logtail就可以自動把一條訪問日誌按照Nginx的log format配置抽取出client_ip、uri等等字段。
應對節點級容器動態伸縮
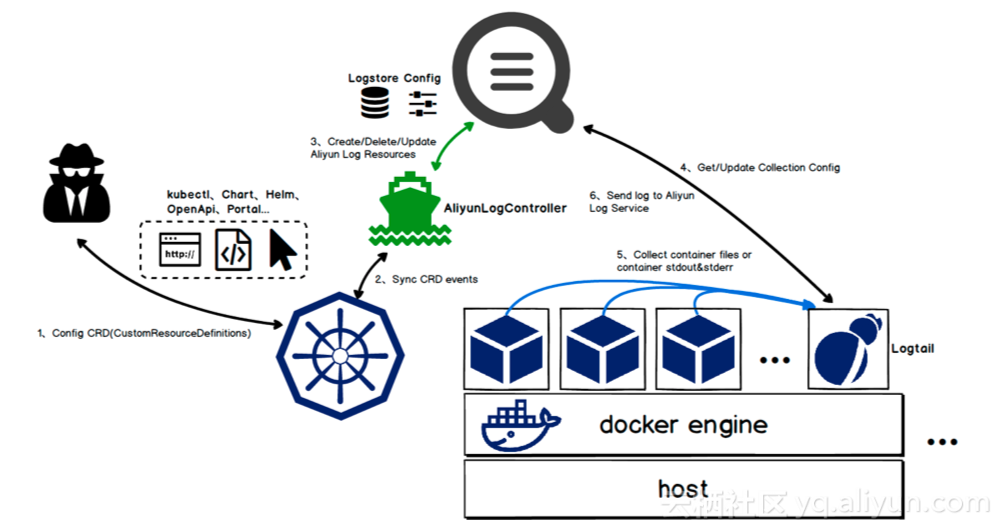
容器天生會做常態化擴容、縮容,新擴容的容器日誌需要及時被採集否則就會丟失,這要求客戶端有能力動態感知到採集源,且部署、配置需要做到足夠的易用性。Logtail從以下兩個維度來解決數據採集的完整性問題:
部署
通過DaemonSet方式來快速部署Logtail到一個Kubernetes node上,一條指令就可以完成,與K8S應用發佈集成也很方便。
Logtail客戶端部署到node上以後,通過domain socket與docker engine通信來處理該節點上的容器動態採集。增量掃描可以及時地發現node上的容器變化,再加上定期全量掃面機制來保證不會丟失掉任何一個容器更改事件,這個雙重保障的設計使得在客戶端上可以及時、完整發現候選的監控目標。
採集配置管理
Logtail從設計之初就選擇了服務端集中式採集配置管理,保證採集指令可以從服務端更高效地傳達給客戶端。這個配置管理可以抽象爲"機器組+採集配置"模型,對於一個採集配置,在機器組內的Logtail實例可以即時獲取到機器組上所關聯的採集配置,去開啓採集任務。
針對Kubernetes場景,Logtail設計了自定義標識方式來管理機器。一類pod可以聲明一個固定的機器標識,Logtail使用這個機器標識向服務端彙報心跳,同時機器組使用這個自定義標識來管理Logtail實例。當Kubernetes節點擴容時,Logtail上報pod對應的自定義機器標識到服務端,服務端就會把這個機器組上的掛載的採集配置下發給Logtail。目前在開源採集客戶端上,常見的做法是使用機器ip或hostname來標識客戶端,這樣在容器伸縮時,需要及時去增刪機器組內的機器ip或hostname,否則就會導致數據採集的缺失,需要複雜的擴容流程保證。
解決採集配置管理難題
Logtail提供兩種採集配置的管理方式,用戶根據自己的喜好任選來操作:
CRD。與Kubernetes生態深度集成,通過在客戶端上事件監聽可以聯動創建日誌服務上的日誌庫、採集配置、機器組等資源。
WEB控制檯。上手快,可視化方式來配置日誌格式化解析規則,通過wizard完成採集配置與機器組的關聯。用戶只需要按照習慣來設置一個容器的日誌目錄,Logtail在上開啓採集時會自動渲染成宿主機上的實際日誌目錄。
我們將日誌從源到目標(日誌庫)定義爲一個採集路由。使用傳統方案實現個性化採集路由功能非常麻煩,需要在客戶端本地配置,每個pod容器寫死這個採集路由,對於容器部署、管理會有強依賴。Logtail解決這個問題的突破點是對環境變量的應用,Kubernetes的env是由多個key-value組成,在部署容器時可以進行env設置。Logtail的採集配置中設計了IncludeEnv和ExcludeEnv配置項,用於加入或排除採集源。在下面的圖中,pod業務容器啓動時設置log_type環境變量,同時Logtail採集配置中定義了IncludeEnv: log_type=nginx_access_log,來指定收集nginx類用途的pod日誌到特定日誌庫。
所有在Kubernetes上採集到的數據,Logtail都自動進行了pod/namesapce/contanier/image維度的打標,方便後續的數據分析。
日誌上下文查詢的設計
上下文查詢是指:給定一條日誌,查看該日誌在原機器、文件位置的上一條或下一條日誌,類似於Linux上的grep -A -B。
在devops等一些場景下,邏輯性異常需要這個時序來輔助定位,有了上下文查看功能會事半功倍。然後在分佈式系統下,在源和目標上都很難保證原先的日誌順序:
在採集客戶端層面,Kubernetes可能產生大量日誌,日誌採集軟件需要利用機器的多個cpu核心解析、預處理日誌,並通過多線程併發或者單線程異步回調的方式處理網絡發送的慢IO問題。這使得日誌數據不能按照機器上的事件產生順序依次到達服務端。
在分佈式系統的服務端層面,由於水平擴展的多機負載均衡架構,使得同一客戶端機器的日誌會分散在多臺存儲節點上。在分散存儲的日誌基礎上再恢復最初的順序是困難的。
傳統上下文查詢方案,一般是根據日誌到達服務端時間、日誌業務時間字段做兩次排序。這在大數據場景下存在:排序性能問題、時間精度不足問題,無法真實還原事件的真實時序。
Logtail與日誌服務(關鍵詞查詢功能)相結合來解決這個問題:
一個容器文件的日誌在採集上傳時,其數據包是由一批的多條日誌組成,多條日誌對應特定文件的一個block,比如512KB。在這一個數據包的多條日誌是按照源文件的日誌序排列,也就意味着某日誌的下一條可能是在同一個數據包裏也可能在下一個數據包裏。
Logtail在採集時會給這個數據包設置唯一的日誌來源sourceId,並在上傳的數據包裏設置包自增Id,叫做packageID。每個package內,任意一條日誌擁有包內的位移offset。
雖然數據包在服務端後存儲可能是無序狀態,但日誌服務有索引可以去精確seek指定sourceId和packageId的數據包。
當我們指定容器A的序號2日誌(source_id:A,package_id:N,offset:M)查看其下文時,先判斷日誌在當前數據包的offset是否爲數據包的末尾(包的日誌條數定義爲L,末尾的offset爲L-1):如果offset M小於(L-1),則說明它的下一條日誌位置是:source_id:A,package_id:N,offset:M+1;而如果當前日誌是數據包的最後一條,則其下一條日誌的位置是:source_id:A,package_id:N+1,offset:0。
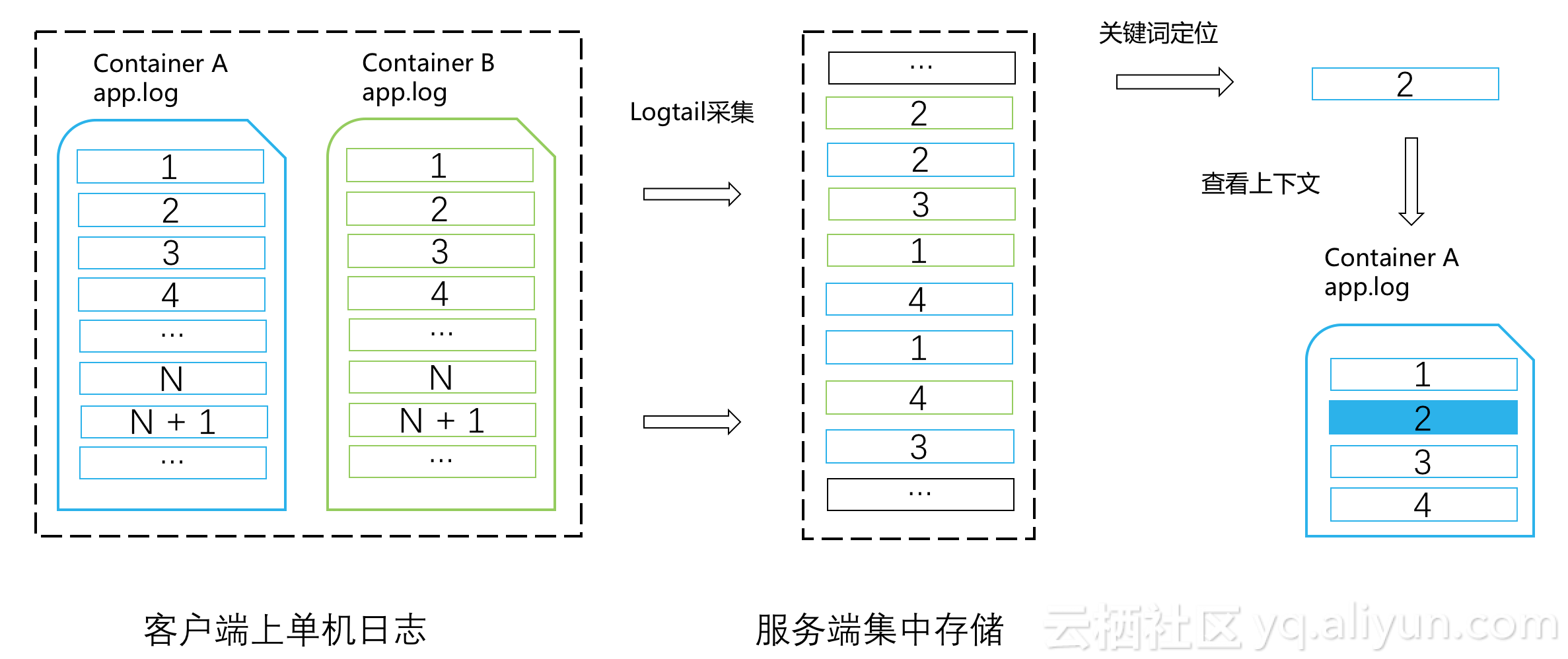
在大部分場景下,利用關鍵詞隨機查詢獲取到的一個package,可以支持當前包長度L次數的上下文翻頁,在提升查詢性能同時也大大降低的後臺服務隨機IO的次數。