




OceanBase的SQL優化器和分佈式並行執行
摘要:本文主要介紹螞蟻金服自主研發的通用關係型數據庫OceanBase,OceanBase採用了分佈式架構,其通過技術創新在普通PC服務器集羣上實現了更好的可靠性、可用性和可擴展行。本文中,螞蟻金服OceanBase團隊資深技術專家潘毅(花名:柏澤)爲大家介紹了OceanBase,並分享了SQL優化器,分佈式事務的執行邏輯等內容,爲大家全面展現OceanBase底層事務引擎的技術創新。
一、OceanBase簡介
OceanBase是螞蟻金服自主研發的通用關係型數據庫,其採用了分佈式架構,目前支撐了螞蟻金服全部核心鏈路系統。
爲什麼要開發OceanBase
數據庫作爲基礎軟件,研發耗時較長且投入較大,那麼,螞蟻金服爲什麼不能採用現成的方案,如商業數據庫或者開源數據庫呢?曾經,阿里巴巴擁有亞洲最大的Oracle集羣,但是隨着互聯網業務的發展,尤其是近十年的發展非常迅速,阿里每年的流量呈指數型上升,而且在某些特定日期流量會出現激增,這也是互聯網行業與傳統銀行、電信等行業在數據庫應用方面的不同。傳統行業可以制定未來幾年的規劃,如客戶規模、業務量等,這些在一定程度上都是可預測的。但是互聯網行業則不同,互聯網行業的流量變化非常快,一方面使用商用數據庫很難進行迅速擴展來應對阿里巴巴飛速增長的規模;另一方面,傳統數據庫的可靠性、高可用性等都需要依靠極其昂貴的硬件來實現,成本將會非常高昂。同時,阿里巴巴在高峯和平峯流量差別巨大,因此通過硬件實現特殊日期的高流量支持會造成嚴重的資源浪費。綜上所述,現有的商業數據庫並不能很好的支持阿里巴巴的整個互聯網產業。而採用開源數據庫同樣也會導致一系列的問題,以MySQL爲例,第一點,互聯網產業的業務流量大,且併發高,需要每一個查詢都要在極短的時間內執行,因此對於通用數據庫而言,必須要掌握核心的代碼才能保證穩定的業務需求。第二點,金融行業需要具備強大的分析、查詢能力的數據庫,而MySQL在分析查詢方面的能力比較薄弱,無法滿足業務需求。出於以上原因,螞蟻金服需要開發一款數據庫來滿足自身的業務需求。
二、OceanBase架構
該部分將從集羣拓撲、分區&分佈式協議、存儲引擎三個部分介紹OceanBase的架構設計。
1. 集羣拓撲
多副本:一般部署爲三個子集羣,每個子集羣由多臺機器組成,數據存儲在不同的集羣中。
全對等節點:每個節點的功能對等,各自管理不同的數據分區。
不依賴共享存儲:共享存儲的價格較爲昂貴,故採用本機存儲的方式。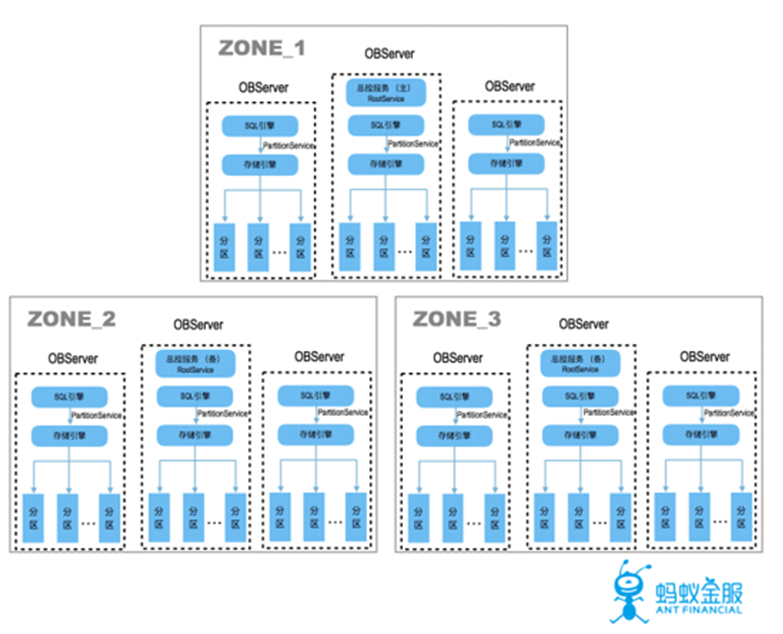
2.分區&分佈式協議
數據分區:支持數據分區,每一個數據以分區爲單位作爲管理組,各分區獨立選主,寫日誌。
高可用&強一致:通過PAXOS協議保證數據(日誌)同步到多數機器,發生故障時自動切主。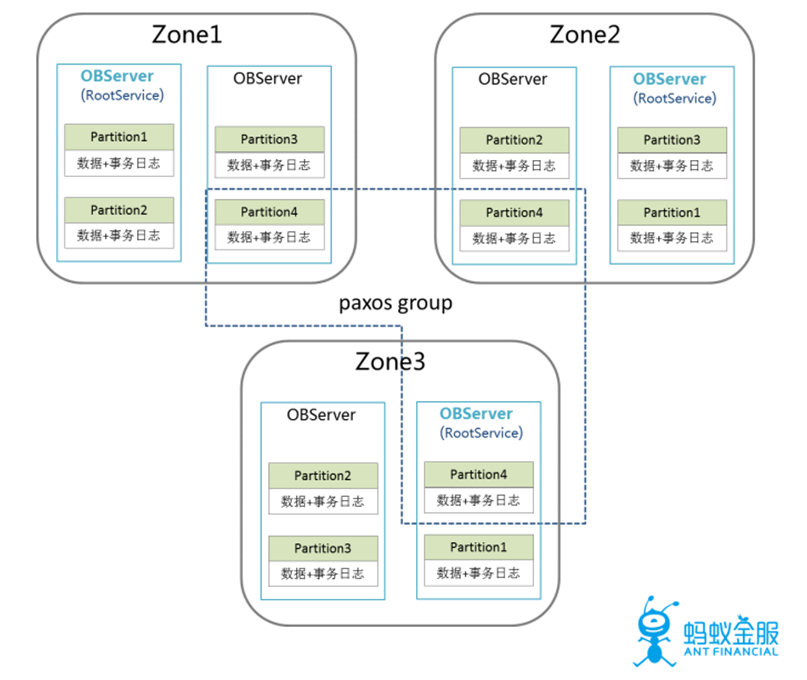
3. 存儲引擎
OceanBase採用的存儲引擎是經典的LSM-Tree架構,數據主要分爲兩個部分,分別是是存儲於硬盤的基線數據(SSTable)以及存儲於內存的增量數據(MenTable)。在該存儲引擎中,所有數據的增刪改操作都會在內存中進行,並形成增量數據,每隔一段時間將增量數據和基線數據進行合併,來避免對於SSD的隨機寫。因爲對於數據庫的操作爲全內存操作,所以DML操作的效果非常好,但如果某一段時間的數據修改操作非常多,數據量過大,導致內存溢出,在這種情況下OceanBase提供了相應的解決方案,即轉儲操作,轉儲會將數據移動至硬盤上,但不會進行數據的合併操作,在後續合併時,會同時對增量數據,基線數據和轉儲數據一起進行合併。可以看出這個架構會面臨一個很大的挑戰,即在進行增刪改的操作後,再進行查詢操作,可能需要對基線數據和增量數據進行融合,因此在該架構下,讀操作可能會受到一定的時間懲罰,這也是SQL優化器需要進行考慮的問題。事實上如果優化器不是基於自身架構和業務需求來進行開發的,可能不會獲得良好的效果,這也是爲什麼要自研數據庫的另一個理由。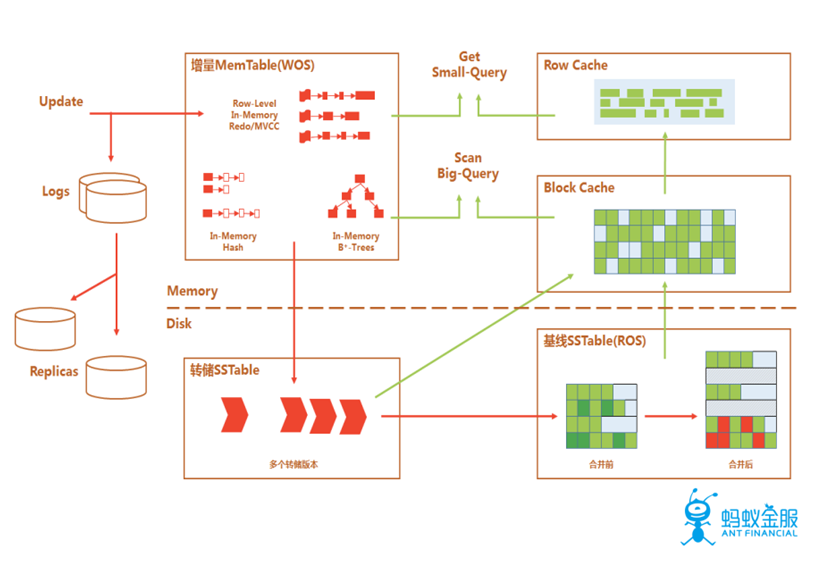
三、SQL優化器
SQL優化的目標是最小化SQL的執行時間(計劃生成+計劃執行),該部分主要會從OLTP(Online Transaction Processing)和OLAP(Online Analytical Processing)兩個方面進行SQL優化的介紹。對於數據量巨大的查詢來說,計劃執行往往佔據大部分的時間,但是對於很多數據量較小的查詢,更多的要考慮計劃生成的優化方案。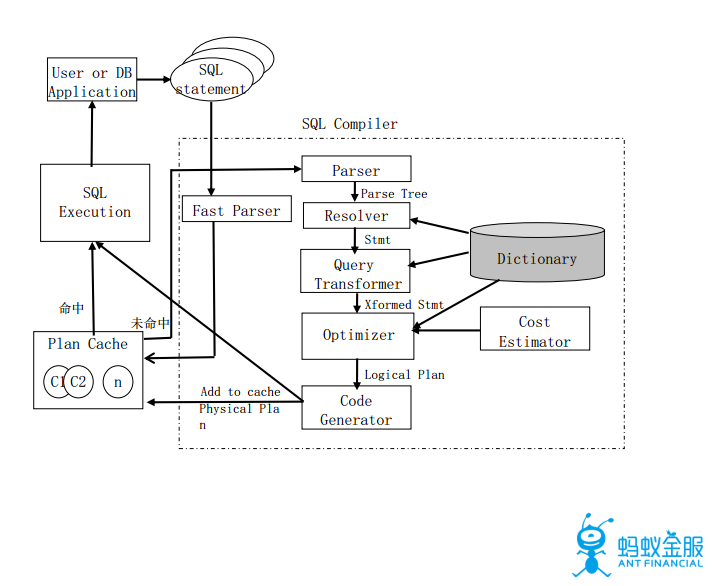
1.基於LSM-Tree結構的代價優化器
OceanBase優化器是基於經典的System R模式,主要進行兩個階段的優化。第一階段是生成基於所有關係都是本地的最優計劃,主要考慮的是CPU和IO的代價;第二階段是並行執行優化,考慮的是CPU,IO,Network和Overhead的代價。同時,代價模型也需要考慮LSM-Tree結構的特點,比如進行MemTable和SSTable的數據融合,不同表的代價可能不同,因此代價需要採用動態採樣計算;系統爲分佈式share nothing系統;索引回表操作會有額外的代價開銷,使用的是邏輯的rowkey而不是物理的rowid,因此回表的時間消耗會增加等,這些都是優化器需要考慮的因素。
2.優化器的基本能力
優化器主要包括兩種類型,分別是邏輯優化器和物理優化器,邏輯優化器主要做查詢改寫等操作的優化,比如基於規則和基於代價的優化,物理優化器主要對連接順序,連接算法,訪問路徑進行優化,同時會考慮到Meta Data,比如統計信息,表分區信息。當有了統計信息和代價模型後,就能估算出模型的執行代價,然後選擇出代價最好的模型進行相應的操作。而計劃管理模塊,對於OLTP的意義更加重要,可以更好的對短查詢進行優化。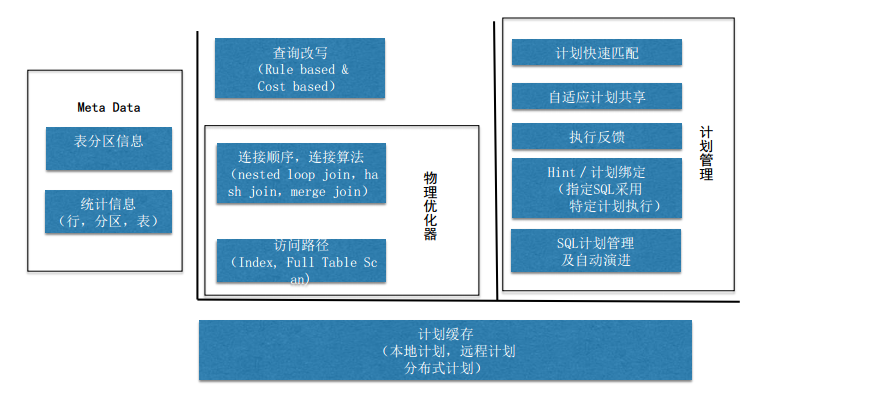
3.優化器的統計信息
OceanBase優化器實現了非常完備的統計信息,包括表(avg rowlen, # of rows),列(column NDV, null value, histogram, min/max),分區/行級的統計信息。爲了防止引入額外的開銷,統計只會在數據進行大版本合併的時候進行。存儲引擎對於某些謂詞可以提供較精準的數據量Cardinality估計,比如通過謂詞可以推算出掃描索引的開始和結束區間,在SStable中每個block都有metadata統計行數,在MemTable中可以統計關於insert,delete,update操作的metadata。在OceanBase中,如果數據在合併過程中進行了修改,會導致數據不夠精準,此時將採用動態採樣的方式來解決該問題。
4.訪問路徑
因爲OLTP的SQL查詢計劃比較簡單,一般來說往往是單表,單索引的查詢,所以訪問路徑對於OLTP非常重要。因此進行SQL查詢時要進行相應的選擇,例如主鍵掃描還是索引掃描,採用單列索引還是多列索引。選擇的標準主要基於規則模型和代價模型,規則模型包括決定性規則(如主鍵全覆蓋則採用主鍵掃描進行查詢)和剪枝規則(運用skyline剪枝規則,多個維度比較,選擇更好的索引)。之後再通過代價模型的比較選出最優模型進行查詢。模型主要考慮的因素包括:掃描範圍,是否回表,過濾條件,Interesting order等。
5.計劃緩存
計劃緩存是指在一個計劃生成之後,後續如果出現同一個查詢或者相似的查詢,可以使用現有的計劃而無需重新生成計劃,計劃緩存通過高效的詞法解析器匹配輸入的查詢語句,使用參數化查詢優化進行匹配。下面爲一個計劃查詢的例子。
可以看到,在計劃緩存中對於查詢語句會進行參數的模糊匹配,但對於特定含義的參數會加入限定條件,比如order by 3中的參數3代表是第三列,該參數的修改可能會導致計劃緩存的不適用,因此存儲計劃緩存時加入了限定條件@3 = 3。
6.自適應共享計劃
對於一個查詢語句只要參數相似就一定能進行計劃緩存的匹配嗎?答案是否定的,舉一個例子,在一個查詢語句中對於salesman因爲數據量較大,會採用全表掃描的方式進行查詢,而對於president,因爲數據量非常少,可能通過索引的方式進行查詢的代價要比全表掃描的代價更好,因此對於這種情況,同樣需要加入相應的限定條件。但重新生成的計劃可能和原有計劃相同,發生這種情況後,便會對於原有的限定條件進行修改,方便之後的查詢語句進行計劃匹配,以此來達到自適應計劃共享。
7. Hint/Outline
在OceanBase中如果對於自動化生成的計劃不滿意,也可以通過創建Outline的方式來綁定自定義的計劃,也就是通過Hint來制定計劃的生成,Hint的類型十分豐富,包括:access path, join order, join method, parallel distribution等,下面是Outline綁定的兩個例子。
8.SQL計劃管理及演進
很多用戶特別是企業級用戶對於穩定性的要求非常高,因此OceanBase在進行系統升級,統計信息更新,硬件更新後會自動進行一個流量的演進,即同時運行新計劃和老計劃,當確定新計劃相較於老計劃無性能回退時,纔會逐漸將老計劃替換成新計劃。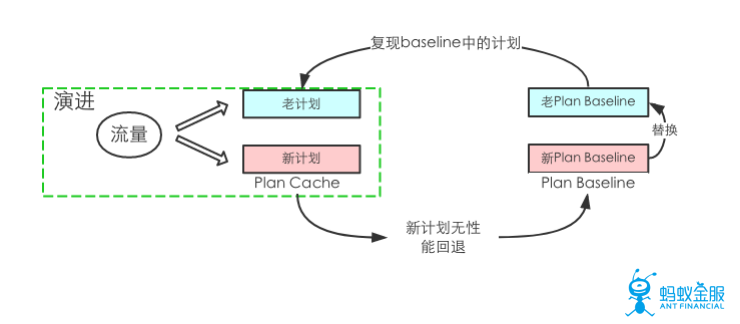
9.分區及分區裁剪
OceanBase支持多種分區類型,包括Range,Hash,Key,List。對於二級分區支持Range/Range, Range/Hash, Range/List, Hash/Hash, Hash/Range等。對於靜態或動態分區裁剪支持inlist, 函數表達式,join filter等多種方式。
10.查詢改寫
查詢改寫主要包括基於規則的改寫以及基於代價的改寫,基於規則的改寫主要包括視圖合併,子查詢展開,過濾條件下推, 連接條件下推,等價條件推導,外連接消除等。基於代價的改寫主要包括OR-expansion,Window function等,查詢改寫對於OLAP的優化效果非常好。下圖爲基於代價模型的改寫框架。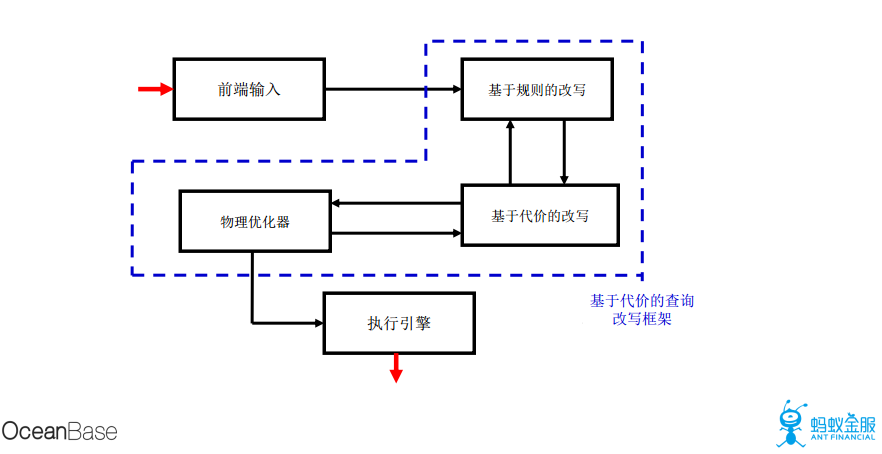
四、SQL執行引擎
優化器和執行引擎是相輔相成的,優化器所能優化的計劃取決於執行引擎的執行計劃。
1.並行執行
並行執行的概念就是分治,分治包括垂直分治(比如拆分計劃爲子計劃單元)和水平分治(比如GI(Granule Iterator)獲取掃描任務),並行執行主要用於OLAP場景中,解決查詢RT時間的問題,這在很多在線分析的場景下是十分必要的。RT時間對於RDBMS查詢是一個重要指標,傳統的Map-Reduce的執行性能並不能滿足OLAP的性能需求,因此如何找到高效的執行計劃及數據流水線非常關鍵。在OceanBase中採用兩級調度,自適應的子計劃調度框架,各節點獨立的任務切分等方案來進行並行執行。對於數據重分佈,OceanBase支持大多數常見的數據分佈,包括Hash, Broadcast/Replicate,,Round Robin,Merge Sort等。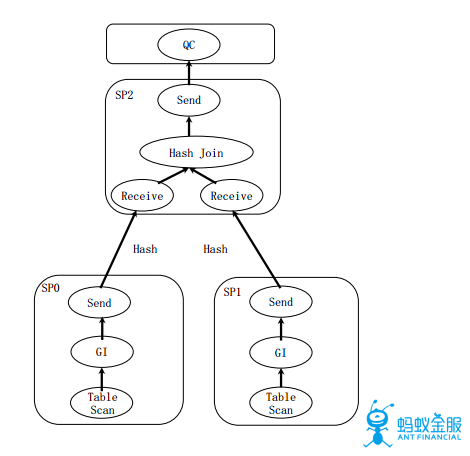
2.兩級調度
在OceanBase中通過下面所述的方式形成兩級調度。即將查詢涉及到的各個機器上分別創建一個執行節點(SQC),來讓主控節點(QC)控制SQC,其中QC爲機器級的控制,SQC爲線程級的控制。QC進行全局調度,依據總並行度分配各節點各子計劃並行度, SQC進行本機調度,其中各節點獨立決定水平並行粒度及執行。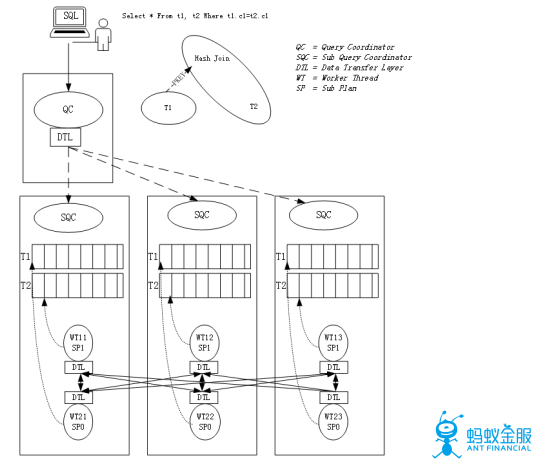
3.計劃動態調度
計劃動態調度是指根據用戶指定或系統資源自適應決定在允許的資源使用範圍內,減少中間結果緩存,構建2組或以上計劃子樹的執行流水線(垂直並行),這種方式可以有效的避免物化,減少物化算子對並行執行所造成的不良影響。該功能正在開發測試中。
4.並行執行計劃
OceanBase中擁有所有主要算子的並行執行方法,包括nested-loop join, merge join, hash join,aggregation, distinct, group by,window function, count, limit等,同時支持豐富的重分佈方法和多種候選計劃,例如partition-wise join, partial partitionwise join,broadcast, hash, sort(for distributedorder by)等。
事實上,並行查詢的優化技術在MPP架構下產生了新的問題,比如分區連接要求各表的分區從邏輯上和物理上都是一樣的,這也是一個需要考慮和優化的方向。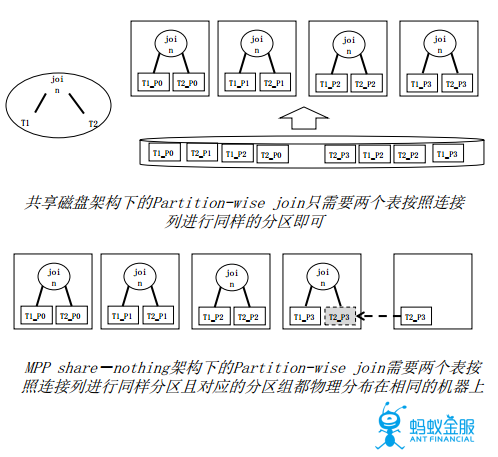
5.編譯執行
傳統執行方式如類型檢查,多態(虛函數)對於內存操作很低效。OceanBase考慮採用LLVM 動態生成執行碼,SQL表達式可以支持動態生成執行碼,存儲過程採用直接編譯執行的方式,來進行性能提升。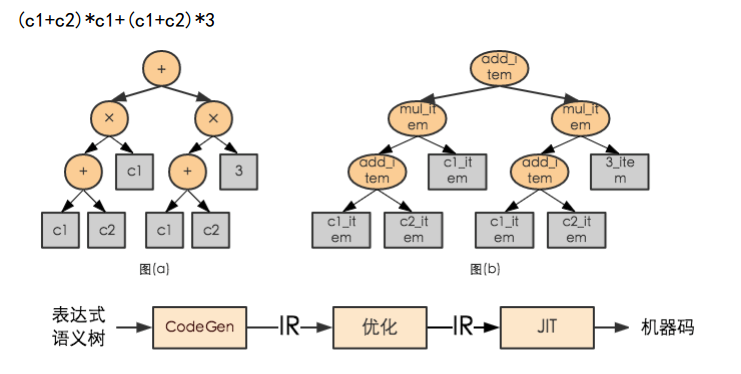
整理:楊德宇