




轉載於:https://blog.csdn.net/tonytfjing/article/details/44278233
一、JVM結構
根據《java虛擬機規範》規定,JVM的基本結構一般如下圖所示:
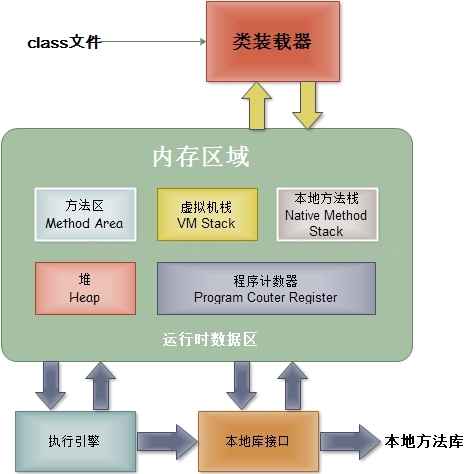
從左圖可知,JVM主要包括四個部分:
1.類加載器(ClassLoader):在JVM啓動時或者在類運行時將需要的class加載到JVM中。(右圖表示了從java源文件到JVM的整個過程,可配合理解。 關於類的加載機制,可以參考http://blog.csdn.net/tonytfjing/article/details/47212291)
2.執行引擎:負責執行class文件中包含的字節碼指令(執行引擎的工作機制,這裏也不細說了,這裏主要介紹JVM結構);
3.內存區(也叫運行時數據區):是在JVM運行的時候操作所分配的內存區。運行時內存區主要可以劃分爲5個區域,如圖:

方法區(Method Area):用於存儲類結構信息的地方,包括常量池、靜態變量、構造函數等。雖然JVM規範把方法區描述爲堆的一個邏輯部分, 但它卻有個別名non-heap(非堆),所以大家不要搞混淆了。方法區還包含一個運行時常量池。
java堆(Heap):存儲java實例或者對象的地方。這塊是GC的主要區域(後面解釋)。從存儲的內容我們可以很容易知道,方法區和堆是被所有java線程共享的。
java棧(Stack):java棧總是和線程關聯在一起,每當創建一個線程時,JVM就會爲這個線程創建一個對應的java棧。在這個java棧中又會包含多個棧幀,每運行一個方法就創建一個棧幀,用於存儲局部變量表、操作棧、方法返回值等。每一個方法從調用直至執行完成的過程,就對應一個棧幀在java棧中入棧到出棧的過程。所以java棧是現成私有的。
程序計數器(PC Register):用於保存當前線程執行的內存地址。由於JVM程序是多線程執行的(線程輪流切換),所以爲了保證線程切換回來後,還能恢復到原先狀態,就需要一個獨立的計數器,記錄之前中斷的地方,可見程序計數器也是線程私有的。
本地方法棧(Native Method Stack):和java棧的作用差不多,只不過是爲JVM使用到的native方法服務的。
4.本地方法接口:主要是調用C或C++實現的本地方法及返回結果。
二、內存分配
我覺得了解垃圾回收之前,得先了解JVM是怎麼分配內存的,然後識別哪些內存是垃圾需要回收,最後纔是用什麼方式回收。
Java的內存分配原理與C/C++不同,C/C++每次申請內存時都要malloc進行系統調用,而系統調用發生在內核空間,每次都要中斷進行切換,這需要一定的開銷,而Java虛擬機是先一次性分配一塊較大的空間,然後每次new時都在該空間上進行分配和釋放,減少了系統調用的次數,節省了一定的開銷,這有點類似於內存池的概念;二是有了這塊空間過後,如何進行分配和回收就跟GC機制有關了。
java一般內存申請有兩種:靜態內存和動態內存。很容易理解,編譯時就能夠確定的內存就是靜態內存,即內存是固定的,系統一次性分配,比如int類型變量;動態內存分配就是在程序執行時才知道要分配的存儲空間大小,比如java對象的內存空間。根據上面我們知道,java棧、程序計數器、本地方法棧都是線程私有的,線程生就生,線程滅就滅,棧中的棧幀隨着方法的結束也會撤銷,內存自然就跟着回收了。所以這幾個區域的內存分配與回收是確定的,我們不需要管的。但是java堆和方法區則不一樣,我們只有在程序運行期間才知道會創建哪些對象,所以這部分內存的分配和回收都是動態的。一般我們所說的垃圾回收也是針對的這一部分。
總之Stack的內存管理是順序分配的,而且定長,不存在內存回收問題;而Heap 則是爲java對象的實例隨機分配內存,不定長度,所以存在內存分配和回收的問題;
三、垃圾檢測、回收算法
垃圾收集器一般必須完成兩件事:檢測出垃圾;回收垃圾。怎麼檢測出垃圾?一般有以下幾種方法:
引用計數法:給一個對象添加引用計數器,每當有個地方引用它,計數器就加1;引用失效就減1。
好了,問題來了,如果我有兩個對象A和B,互相引用,除此之外,沒有其他任何對象引用它們,實際上這兩個對象已經無法訪問,即是我們說的垃圾對象。但是互相引用,計數不爲0,導致無法回收,所以還有另一種方法:
可達性分析算法:以根集對象爲起始點進行搜索,如果有對象不可達的話,即是垃圾對象。這裏的根集一般包括java棧中引用的對象、方法區常良池中引用的對象
本地方法中引用的對象等。
總之,JVM在做垃圾回收的時候,會檢查堆中的所有對象是否會被這些根集對象引用,不能夠被引用的對象就會被垃圾收集器回收。一般回收算法也有如下幾種:
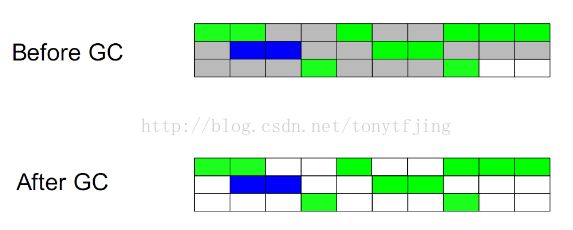
1.標記-清除(Mark-sweep)
算法和名字一樣,分爲兩個階段:標記和清除。標記所有需要回收的對象,然後統一回收。這是最基礎的算法,後續的收集算法都是基於這個算法擴展的。
不足:效率低;標記清除之後會產生大量碎片。效果圖如下:
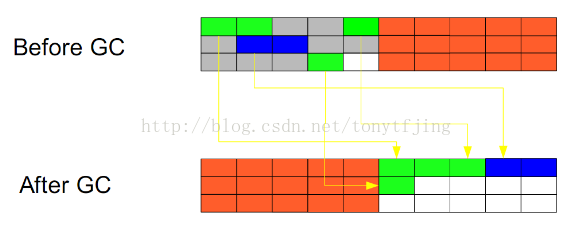
2.複製(Copying)
此算法把內存空間劃爲兩個相等的區域,每次只使用其中一個區域。垃圾回收時,遍歷當前使用區域,把正在使用中的對象複製到另外一個區域中。此算法每次只處理正在使用中的對象,因此複製成本比較小,同時複製過去以後還能進行相應的內存整理,不會出現“碎片”問題。當然,此算法的缺點也是很明顯的,就是需要兩倍內存空間。效果圖如下:
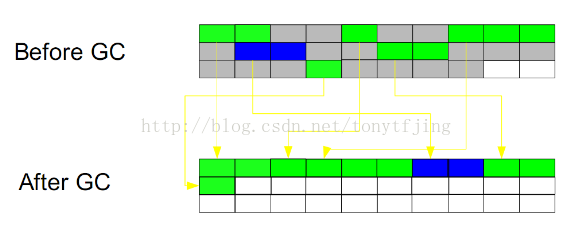
3.標記-整理(Mark-Compact)
此算法結合了“標記-清除”和“複製”兩個算法的優點。也是分兩階段,第一階段從根節點開始標記所有被引用對象,第二階段遍歷整個堆,把清除未標記對象並且把存活對象“壓縮”到堆的其中一塊,按順序排放。此算法避免了“標記-清除”的碎片問題,同時也避免了“複製”算法的空間問題。效果圖如下:
(1,2,3 圖文摘自 http://pengjiaheng.iteye.com/blog/520228,感謝原作者。)
4.分代收集算法
這是當前商業虛擬機常用的垃圾收集算法。分代的垃圾回收策略,是基於這樣一個事實:不同的對象的生命週期是不一樣的。因此,不同生命週期的對象可以採取不同的收集方式,以便提高回收效率。
爲什麼要運用分代垃圾回收策略?在java程序運行的過程中,會產生大量的對象,因每個對象所能承擔的職責不同所具有的功能不同所以也有着不一樣的生命週期,有的對象生命週期較長,比如Http請求中的Session對象,線程,Socket連接等;有的對象生命週期較短,比如String對象,由於其不變類的特性,有的在使用一次後即可回收。試想,在不進行對象存活時間區分的情況下,每次垃圾回收都是對整個堆空間進行回收,那麼消耗的時間相對會很長,而且對於存活時間較長的對象進行的掃描工作等都是徒勞。因此就需要引入分治的思想,所謂分治的思想就是因地制宜,將對象進行代的劃分,把不同生命週期的對象放在不同的代上使用不同的垃圾回收方式。
如何劃分?將對象按其生命週期的不同劃分成:年輕代(Young Generation)、年老代(Old Generation)、持久代(Permanent Generation)。其中持久代主要存放的是類信息,所以與java對象的回收關係不大,與回收息息相關的是年輕代和年老代。這裏有個比喻很形象
“假設你是一個普通的 Java 對象,你出生在 Eden 區,在 Eden 區有許多和你差不多的小兄弟、×××妹,可以把 Eden 區當成幼兒園,在這個幼兒園裏大家玩了很長時間。Eden 區不能無休止地放你們在裏面,所以當年紀稍大,你就要被送到學校去上學,這裏假設從小學到高中都稱爲 Survivor 區。開始的時候你在 Survivor 區裏面劃分出來的的“From”區,讀到高年級了,就進了 Survivor 區的“To”區,中間由於學習成績不穩定,還經常來回折騰。直到你 18 歲的時候,高中畢業了,該去社會上闖闖了。於是你就去了年老代,年老代裏面人也很多。在年老代裏,你生活了 20 年 (每次 GC 加一歲),最後壽終正寢,被 GC 回收。有一點沒有提,你在年老代遇到了一個同學,他的名字叫愛德華 (慕光之城裏的帥哥吸血鬼),他以及他的家族永遠不會死,那麼他們就生活在永生代。”
具體區域可以通過VisualVM中的VisaulGC插件查看,如圖(openjdk 1.7):
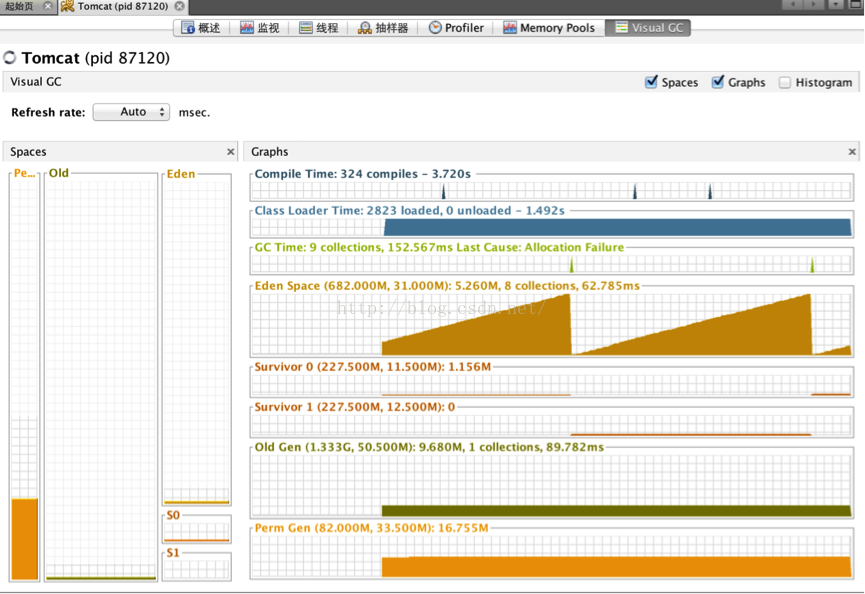
年輕代:是所有新對象產生的地方。年輕代被分爲3個部分——Enden區和兩個Survivor區(From和to)當Eden區被對象填滿時,就會執行Minor GC。並把所有存活下來的對象轉移到其中一個survivor區(假設爲from區)。Minor GC同樣會檢查存活下來的對象,並把它們轉移到另一個survivor區(假設爲to區)。這樣在一段時間內,總會有一個空的survivor區。經過多次GC週期後,仍然存活下來的對象會被轉移到年老代內存空間。通常這是在年輕代有資格提升到年老代前通過設定年齡閾值來完成的。需要注意,Survivor的兩個區是對稱的,沒先後關係,from和to是相對的。
年老代:在年輕代中經歷了N次回收後仍然沒有被清除的對象,就會被放到年老代中,可以說他們都是久經沙場而不亡的一代,都是生命週期較長的對象。對於年老代和永久代,就不能再採用像年輕代中那樣搬移騰挪的回收算法,因爲那些對於這些回收戰場上的老兵來說是小兒科。通常會在老年代內存被佔滿時將會觸發Full GC,回收整個堆內存。
持久代:用於存放靜態文件,比如java類、方法等。持久代對垃圾回收沒有顯著的影響。
分代回收的效果圖如下:
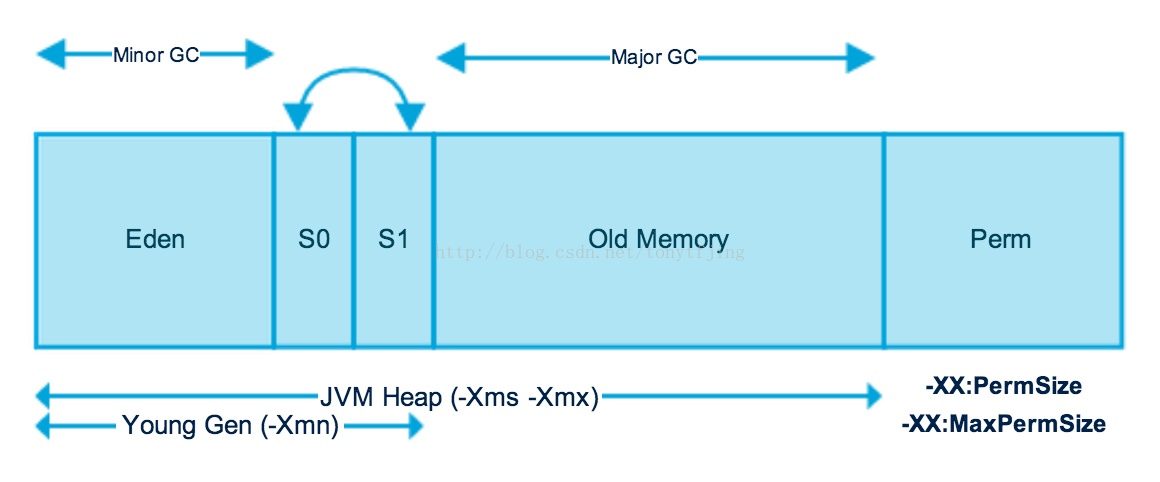
我這裏之所以最後講分代,是因爲分代裏涉及了前面幾種算法。年輕代:涉及了複製算法;年老代:涉及了“標記-整理(Mark-Sweep)”的算法。
四、垃圾收集器
垃圾收集算法是內存回收的方法論,而實現這些方法論的則是垃圾收集器。不同廠商不同版本JVM所提供的垃圾收集器可能不同,這裏參照《深入理解Java虛擬機》說的是JDK1.7版本Hotspot虛擬機,關於垃圾收集器有篇博文總結的不錯,我就不說了,詳見:http://blog.csdn.net/java2000_wl/article/details/8030172
GC 命令
1、jstat -gccause pid
監視Java堆狀況,包括Eden區、兩個survivor區、老年代、永久代等的容量、已用空間、GC時間合計等信息、導致上一次GC產生的原因
eg.
jstat -gccause 28061
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT LGCC GCC
36.15 0.00 56.61 30.54 91.83 87.63 944 119.607 5 5.926 125.532 Allocation Failure No GC
S0:年輕代中第一個survivor(倖存區)已使用的佔當前容量百分比
S1:年輕代中第二個survivor(倖存區)已使用的佔當前容量百分比
E:年輕代中Eden(伊甸園)已使用的佔當前容量百分比
O:old代已使用的佔當前容量百分比
M:元空間(Metaspace)已使用的佔當前容量百分比,類似1.8之前的永久代(PermGen)
CCS:CCS表示的是Metaspace的使用率,也就是CCSU/CCSC算出來的
YGC:從應用程序啓動到採樣時年輕代中gc次數
YGCT:從應用程序啓動到採樣時年輕代中gc所用時間(s)
FGC:從應用程序啓動到採樣時old代(全gc)gc次數
FGCT:從應用程序啓動到採樣時old代(全gc)gc所用時間(s)
GCT:從應用程序啓動到採樣時gc用的總時間(s)
LGCC:最近一次full gc的原因
GCC:
2、jmap -heap pid
顯示Java堆詳細信息,如使用哪種回收器、參數配置、分代狀況等
eg.
jmap -heap 28061
Attaching to process ID 28061, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.91-b14
using thread-local object allocation.
Parallel GC with 30 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 23622320128 (22528.0MB)
NewSize = 7516192768 (7168.0MB)
MaxNewSize = 7516192768 (7168.0MB)
OldSize = 16106127360 (15360.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 7132413952 (6802.0MB)
used = 1967181000 (1876.0499954223633MB)
free = 5165232952 (4925.950004577637MB)
27.580858503710132% used
From Space:
capacity = 190840832 (182.0MB)
used = 29685552 (28.310348510742188MB)
free = 161155280 (153.6896514892578MB)
15.555136544363839% used
To Space:
capacity = 191365120 (182.5MB)
used = 0 (0.0MB)
free = 191365120 (182.5MB)
0.0% used
PS Old Generation
capacity = 16106127360 (15360.0MB)
used = 5054486720 (4820.334167480469MB)
free = 11051640640 (10539.665832519531MB)
31.382383902867634% used
74399 interned Strings occupying 7907472 bytes.
3、jmap -dump:[live,]format=b,file=<filename> pid
生成Java堆轉儲快照。格式爲:-dump:[live,]format=b,file=<filename>,其中live子
參數說明是否只dump出存活的對象
生成dump文件跟當前jvm內存大小有關,可能生成的文件會很大。
4、jmap -histo pid 顯示堆中對象統計信息,包括類、實例數據、合計容量。
eg.
jmap -histo 28061
num #instances #bytes class name
----------------------------------------------
1: 11410026 1362675080 [C
2: 2219154 1103383864 [B
3: 21667070 866682800 java.util.LinkedHashMap$Entry
4: 12121603 387891296 java.util.Hashtable$Entry
5: 5064770 283627120 java.security.Provider$Service
6: 10239384 245745216 java.security.Provider$ServiceKey
7: 10129191 243100584 java.lang.String
8: 856460 242869960 [Ljava.util.HashMap$Node;
9: 859192 236504032 [I
10: 3646059 145784816 [Ljava.lang.Object;
11: 20705 88713496 [Ljava.util.Hashtable$Entry;
12: 2650951 84830432 java.lang.StackTraceElement
13: 2806632 67359168 java.util.ArrayList
14: 1980684 63381888 java.util.HashMap$Node
15: 906512 43512576 java.util.HashMap
16: 76402 22543104 [Ljava.lang.StackTraceElement;
17: 231233 18500968 [S
......................................................
其中:
[C is a char[]
[S is a short[]
[I is a int[]
[B is a byte[]
[[I is a int[][]
C對象佔用Heap這麼多,往往跟String有關,String其內部使用final char[]數組來保存數據的
5、tomcat jvm 參數
eg.
CATALINA_OPTS="
-server
-Xms6000M
-Xmx6000M
-Xss512k
-XX:NewSize=2250M
-XX:MaxNewSize=2250M
-XX:PermSize=128M
-XX:MaxPermSize=256M
-XX:+AggressiveOpts
-XX:+UseBiasedLocking
-XX:+DisableExplicitGC
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:MaxTenuringThreshold=31
-XX:+CMSParallelRemarkEnabled
-XX:+UseCMSCompactAtFullCollection
-XX:LargePageSizeInBytes=128m
-XX:+UseFastAccessorMethods
-XX:+UseCMSInitiatingOccupancyOnly
-Duser.timezone=Asia/Shanghai
-Djava.awt.headless=true"
eg2.
JAVA_OPTS="-server -Xms22528m -Xmx22528m -Xmn7g -Xss1024K -XX:+UseParallelGC -XX:ParallelGCThreads=30 -XX:TargetSurvivorRatio=85 -verbose:gc -Xloggc:/tmp/civp_gc_$(date +%Y%m%d%H%M%S).log -XX:+PrintGCDateStamps -XX:+PrintGCDe
tails -XX:ErrorFile=/tmp/civp_err_$(date +%Y%m%d%H%M%S).log";
-Xms:表示 Java 初始化堆的大小,-Xms 與-Xmx 設成一樣的值,避免 JVM 反覆重新申請內存,導致性能大起大落,默認值爲物理內存的 1/64,默認(MinHeapFreeRatio參數可以調整)空餘堆內存小於 40% 時,JVM 就會增大堆直到 -Xmx 的最大限制。
-Xmx:表示最大 Java 堆大小,當應用程序需要的內存超出堆的最大值時虛擬機就會提示內存溢出,並且導致應用服務崩潰,因此一般建議堆的最大值設置爲可用內存的最大值的80%。如何知道我的 JVM 能夠使用最大值,使用 java -Xmx512M -version 命令來進行測試,然後逐漸的增大 512 的值,如果執行正常就表示指定的內存大小可用,否則會打印錯誤信息,默認值爲物理內存的 1/4,默認(MinHeapFreeRatio參數可以調整)空餘堆內存大於 70% 時,JVM 會減少堆直到-Xms 的最小限制。
-Xss:表示每個 Java 線程堆棧大小,JDK 5.0 以後每個線程堆棧大小爲 1M,以前每個線程堆棧大小爲 256K。根據應用的線程所需內存大小進行調整,在相同物理內存下,減小這個值能生成更多的線程,但是操作系統對一個進程內的線程數還是有限制的,不能無限生成,經驗值在 3000~5000 左右。一般小的應用, 如果棧不是很深, 應該是128k 夠用的,大的應用建議使用 256k 或 512K,一般不易設置超過 1M,要不然容易出現out ofmemory。這個選項對性能影響比較大,需要嚴格的測試。
-XX:NewSize:設置新生代內存大小。
-XX:MaxNewSize:設置最大新生代新生代內存大小
-XX:PermSize:設置持久代內存大小
-XX:MaxPermSize:設置最大值持久代內存大小,永久代不屬於堆內存,堆內存只包含新生代和老年代。
-XX:+AggressiveOpts:作用如其名(aggressive),啓用這個參數,則每當 JDK 版本升級時,你的 JVM 都會使用最新加入的優化技術(如果有的話)。
-XX:+UseBiasedLocking:啓用一個優化了的線程鎖,我們知道在我們的appserver,每個http請求就是一個線程,有的請求短有的請求長,就會有請求排隊的現象,甚至還會出現線程阻塞,這個優化了的線程鎖使得你的appserver內對線程處理自動進行最優調配。
-XX:+DisableExplicitGC:在 程序代碼中不允許有顯示的調用“System.gc()”。每次在到操作結束時手動調用 System.gc() 一下,付出的代價就是系統響應時間嚴重降低,就和關於 Xms,Xmx 裏的解釋的原理一樣,這樣去調用 GC 導致系統的 JVM 大起大落。
-XX:+UseConcMarkSweepGC:設置年老代爲併發收集,即 CMS gc,這一特性只有 jdk1.5
後續版本才具有的功能,它使用的是 gc 估算觸發和 heap 佔用觸發。我們知道頻頻繁的 GC 會造面 JVM
的大起大落從而影響到系統的效率,因此使用了 CMS GC 後可以在 GC 次數增多的情況下,每次 GC 的響應時間卻很短,比如說使用了 CMS
GC 後經過 jprofiler 的觀察,GC 被觸發次數非常多,而每次 GC 耗時僅爲幾毫秒。
-XX:+UseParNewGC:對新生代採用多線程並行回收,這樣收得快,注意最新的 JVM 版本,當使用 -XX:+UseConcMarkSweepGC 時,-XX:UseParNewGC 會自動開啓。因此,如果年輕代的並行 GC 不想開啓,可以通過設置 -XX:-UseParNewGC 來關掉。
-XX:MaxTenuringThreshold:設置垃圾最大年齡。如果設置爲0的話,則新生代對象不經過 Survivor 區,直接進入老年代。對於老年代比較多的應用(需要大量常駐內存的應用),可以提高效率。如果將此值設置爲一 個較大值,則新生代對象會在 Survivor 區進行多次複製,這樣可以增加對象在新生代的存活時間,增加在新生代即被回收的概率,減少Full GC的頻率,這樣做可以在某種程度上提高服務穩定性。該參數只有在串行 GC 時纔有效,這個值的設置是根據本地的 jprofiler 監控後得到的一個理想的值,不能一概而論原搬照抄。
-XX:+CMSParallelRemarkEnabled:在使用 UseParNewGC 的情況下,儘量減少 mark 的時間。
-XX:+UseCMSCompactAtFullCollection:在使用 concurrent gc 的情況下,防止 memoryfragmention,對 live object 進行整理,使 memory 碎片減少。
-XX:LargePageSizeInBytes:指定 Java heap 的分頁頁面大小,內存頁的大小不可設置過大, 會影響 Perm 的大小。
-XX:+UseFastAccessorMethods:使用 get,set 方法轉成本地代碼,原始類型的快速優化。
-XX:+UseCMSInitiatingOccupancyOnly:只有在 oldgeneration 在使用了初始化的比例後 concurrent collector 啓動收集。
-Duser.timezone=Asia/Shanghai:設置用戶所在時區。
-Djava.awt.headless=true:這個參數一般我們都是放在最後使用的,這全參數的作用是這樣的,有時我們會在我們的 J2EE 工程中使用一些圖表工具如:jfreechart,用於在 web 網頁輸出 GIF/JPG 等流,在 winodws 環境下,一般我們的 app server 在輸出圖形時不會碰到什麼問題,但是在linux/unix 環境下經常會碰到一個 exception 導致你在 winodws 開發環境下圖片顯示的好好可是在 linux/unix 下卻顯示不出來,因此加上這個參數以免避這樣的情況出現。
-
Xmn:新生代的內存空間大小,注意:此處的大小是(eden+ 2 survivor space)。與 jmap -heap 中顯示的 New gen 是不同的。整個堆大小 = 新生代大小 + 老生代大小 + 永久代大小。在保證堆大小不變的情況下,增大新生代後,將會減小老生代大小。此值對系統性能影響較大,Sun官方推薦配置爲整個堆的 3/8。
-XX:CMSInitiatingOccupancyFraction:當堆滿之後,並行收集器便開始進行垃圾收集,例如,當沒有足夠的空間來容納新分配或提升的對象。對於 CMS 收集器,長時間等待是不可取的,因爲在併發垃圾收集期間應用持續在運行(並且分配對象)。因此,爲了在應用程序使用完內存之前完成垃圾收集週期,CMS 收集器要比並行收集器更先啓動。因爲不同的應用會有不同對象分配模式,JVM 會收集實際的對象分配(和釋放)的運行時數據,並且分析這些數據,來決定什麼時候啓動一次 CMS 垃圾收集週期。這個參數設置有很大技巧,基本上滿足(Xmx-Xmn)*(100-CMSInitiatingOccupancyFraction)/100 >= Xmn 就不會出現 promotion failed。例如在應用中 Xmx 是6000,Xmn 是 512,那麼 Xmx-Xmn 是 5488M,也就是老年代有 5488M,CMSInitiatingOccupancyFraction=90 說明老年代到 90% 滿的時候開始執行對老年代的併發垃圾回收(CMS),這時還 剩 10% 的空間是 5488*10% = 548M,所以即使 Xmn(也就是新生代共512M)裏所有對象都搬到老年代裏,548M 的空間也足夠了,所以只要滿足上面的公式,就不會出現垃圾回收時的 promotion failed,因此這個參數的設置必須與 Xmn 關聯在一起。
-XX:+CMSIncrementalMode:該標誌將開啓 CMS 收集器的增量模式。增量模式經常暫停 CMS 過程,以便對應用程序線程作出完全的讓步。因此,收集器將花更長的時間完成整個收集週期。因此,只有通過測試後發現正常 CMS 週期對應用程序線程干擾太大時,才應該使用增量模式。由於現代服務器有足夠的處理器來適應併發的垃圾收集,所以這種情況發生得很少,用於但 CPU情況。
-XX:NewRatio:年輕代(包括 Eden 和兩個 Survivor 區)與年老代的比值(除去持久代),-XX:NewRatio=4 表示年輕代與年老代所佔比值爲 1:4,年輕代佔整個堆棧的 1/5,Xms=Xmx 並且設置了 Xmn 的情況下,該參數不需要進行設置。
-XX:SurvivorRatio:Eden 區與 Survivor 區的大小比值,設置爲 8,表示 2 個 Survivor 區(JVM 堆內存年輕代中默認有 2 個大小相等的 Survivor 區)與 1 個 Eden 區的比值爲 2:8,即 1 個 Survivor 區佔整個年輕代大小的 1/10。
-XX:+UseSerialGC:設置串行收集器。
-XX:+UseParallelGC:設置爲並行收集器。此配置僅對年輕代有效。即年輕代使用並行收集,而年老代仍使用串行收集。
-XX:+UseParallelOldGC:配置年老代垃圾收集方式爲並行收集,JDK6.0 開始支持對年老代並行收集。
-XX:ConcGCThreads:早期 JVM 版本也叫-XX:ParallelCMSThreads,定義併發 CMS 過程運行時的線程數。比如 value=4 意味着 CMS 週期的所有階段都以 4 個線程來執行。儘管更多的線程會加快併發 CMS 過程,但其也會帶來額外的同步開銷。因此,對於特定的應用程序,應該通過測試來判斷增加 CMS 線程數是否真的能夠帶來性能的提升。如果還標誌未設置,JVM 會根據並行收集器中的 -XX:ParallelGCThreads 參數的值來計算出默認的並行 CMS 線程數。
-XX:ParallelGCThreads:配置並行收集器的線程數,即:同時有多少個線程一起進行垃圾回收,此值建議配置與 CPU 數目相等。
-XX:OldSize:設置 JVM 啓動分配的老年代內存大小,類似於新生代內存的初始大小 -XX:NewSize。
以上就是一些常用的配置參數,有些參數是可以被替代的,配置思路需要考慮的是 Java 提供的垃圾回收機制。虛擬機的堆大小決定了虛擬機花費在收集垃圾上的時間和頻度。收集垃圾能夠接受的速度和應用有關,應該通過分析實際的垃圾收集的時間和頻率來調整。假如堆的大小很大,那麼完全垃圾收集就會很慢,但是頻度會降低。假如您把堆的大小和內存的需要一致,完全收集就很快,但是會更加頻繁。調整堆大小的的目的是最小化垃圾收集的時間,以在特定的時間內最大化處理客戶的請求。在基準測試的時候,爲確保最好的性能,要把堆的大小設大,確保垃圾收集不在整個基準測試的過程中出現。
假如系統花費很多的時間收集垃圾,請減小堆大小。一次完全的垃圾收集應該不超過 3-5 秒。假如垃圾收集成爲瓶頸,那麼需要指定代的大小,檢查垃圾收集的周詳輸出,研究垃圾收集參數對性能的影響。當增加處理器時,記得增加內存,因爲分配能夠並行進行,而垃圾收集不是並行的。