




摘要
本文主要介紹了Kafka High Level Consumer,Consumer Group,Consumer Rebalance,Low Level Consumer實現的語義,以及適用場景。以及未來版本中對High Level Consumer的重新設計–使用Consumer Coordinator解決Split Brain和Herd等問題。
High Level Consumer
很多時候,客戶程序只是希望從Kafka讀取數據,不太關心消息offset的處理。同時也希望提供一些語義,例如同一條消息只被某一個Consumer消費(單播)或被所有Consumer消費(廣播)。因此,Kafka Hight Level Consumer提供了一個從Kafka消費數據的高層抽象,從而屏蔽掉其中的細節並提供豐富的語義。
Consumer Group
High Level Consumer將從某個Partition讀取的最後一條消息的offset存於Zookeeper中(Kafka從0.8.2版本開始同時支持將offset存於Zookeeper中與將offset存於專用的Kafka Topic中)。這個offset基於客戶程序提供給Kafka的名字來保存,這個名字被稱爲Consumer Group。Consumer Group是整個Kafka集羣全局的,而非某個Topic的。每一個High Level Consumer實例都屬於一個Consumer Group,若不指定則屬於默認的Group。
Zookeeper中Consumer相關節點如下圖所示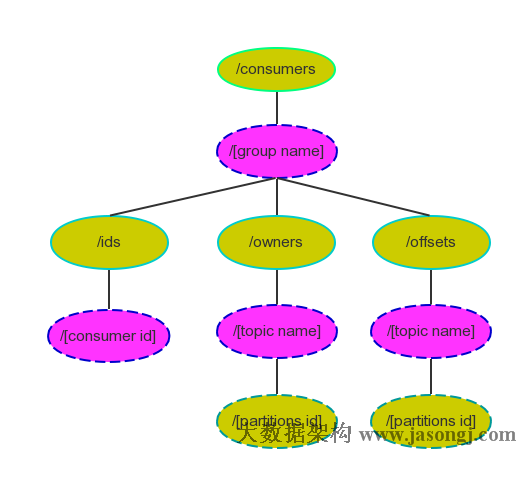
很多傳統的Message Queue都會在消息被消費完後將消息刪除,一方面避免重複消費,另一方面可以保證Queue的長度比較短,提高效率。而如上文所述,Kafka並不刪除已消費的消息,爲了實現傳統Message Queue消息只被消費一次的語義,Kafka保證每條消息在同一個Consumer Group裏只會被某一個Consumer消費。與傳統Message Queue不同的是,Kafka還允許不同Consumer Group同時消費同一條消息,這一特性可以爲消息的多元化處理提供支持。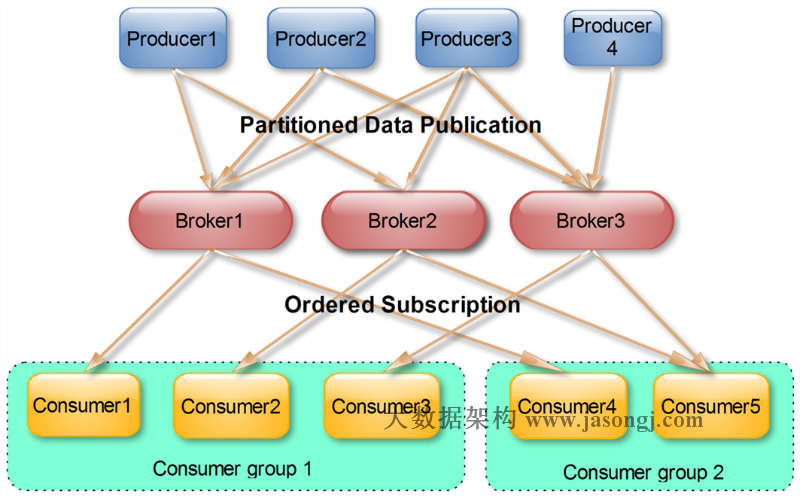
實際上,Kafka的設計理念之一就是同時提供離線處理和實時處理。根據這一特性,可以使用Storm這種實時流處理系統對消息進行實時在線處理,同時使用Hadoop這種批處理系統進行離線處理,還可以同時將數據實時備份到另一個數據中心,只需要保證這三個操作所使用的Consumer在不同的Consumer Group即可。下圖展示了Kafka在LinkedIn的一種簡化部署模型。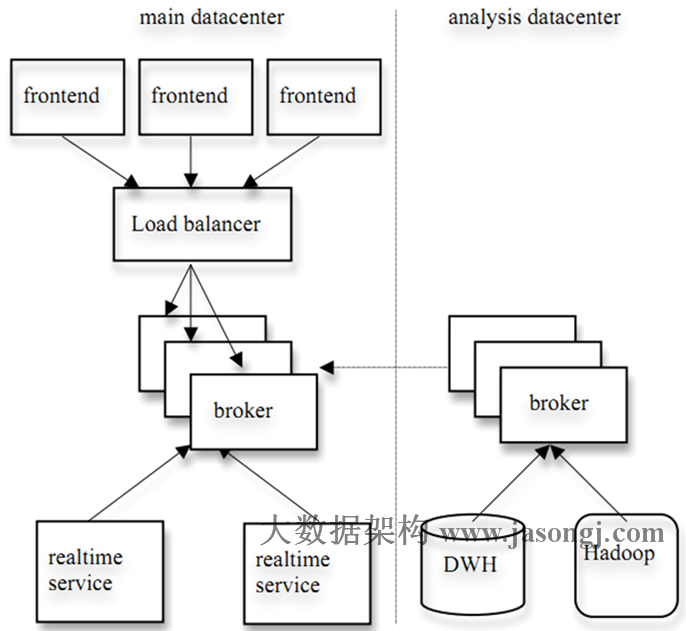
爲了更清晰展示Kafka Consumer Group的特性,筆者進行了一項測試。創建一個Topic (名爲topic1),再創建一個屬於group1的Consumer實例,並創建三個屬於group2的Consumer實例,然後通過Producer向topic1發送Key分別爲1,2,3的消息。結果發現屬於group1的Consumer收到了所有的這三條消息,同時group2中的3個Consumer分別收到了Key爲1,2,3的消息,如下圖所示。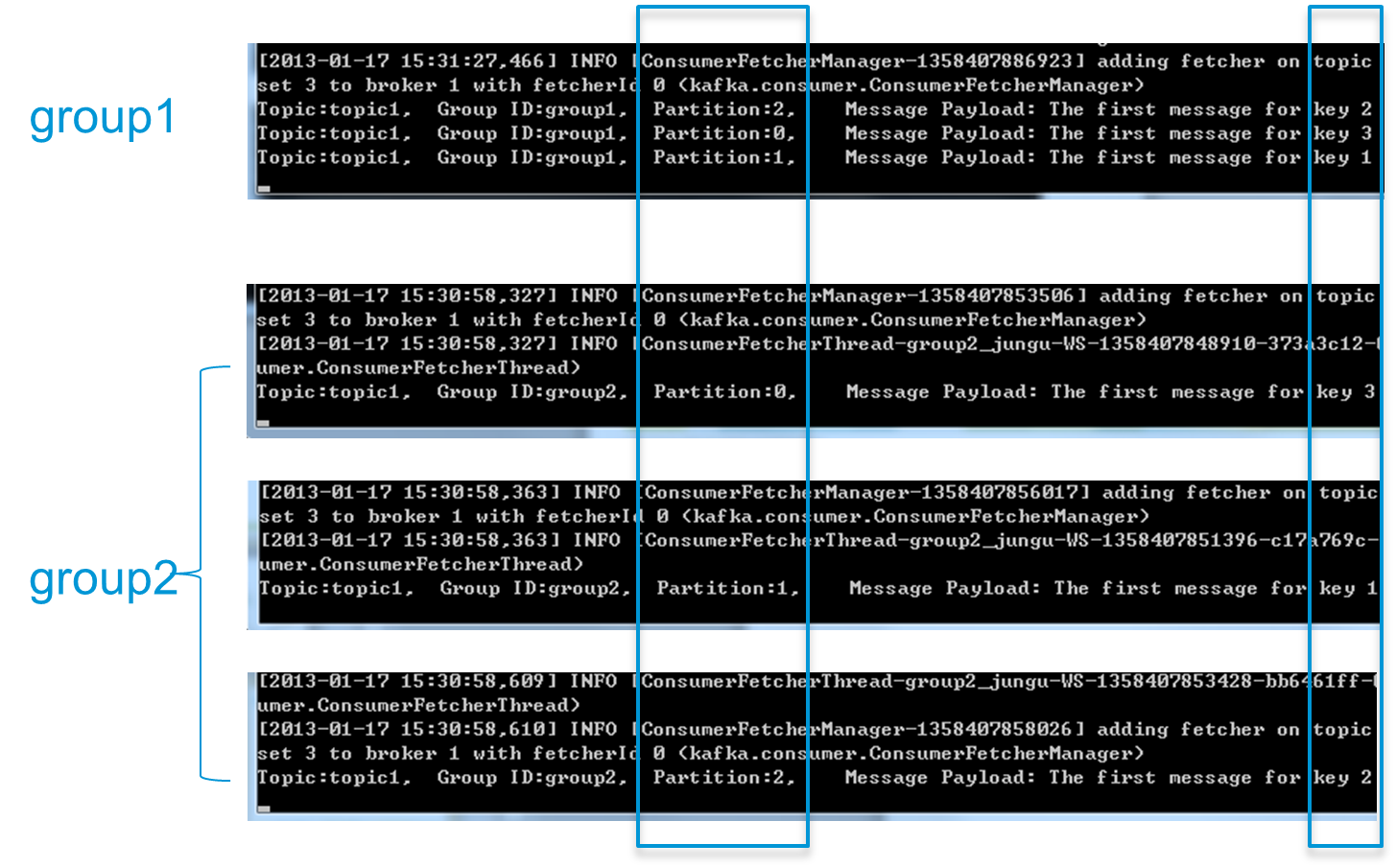
注:上圖中每個黑色區域代表一個Consumer實例,每個實例只創建一個MessageStream。實際上,本實驗將Consumer應用程序打成jar包,並在4個不同的命令行終端中傳入不同的參數運行。
High Level Consumer Rebalance
(本節所講述Rebalance相關內容均基於Kafka High Level Consumer)
Kafka保證同一Consumer Group中只有一個Consumer會消費某條消息,實際上,Kafka保證的是穩定狀態下每一個Consumer實例只會消費某一個或多個特定Partition的數據,而某個Partition的數據只會被某一個特定的Consumer實例所消費。也就是說Kafka對消息的分配是以Partition爲單位分配的,而非以每一條消息作爲分配單元。這樣設計的劣勢是無法保證同一個Consumer Group裏的Consumer均勻消費數據,優勢是每個Consumer不用都跟大量的Broker通信,減少通信開銷,同時也降低了分配難度,實現也更簡單。另外,因爲同一個Partition裏的數據是有序的,這種設計可以保證每個Partition裏的數據可以被有序消費。
如果某Consumer Group中Consumer(每個Consumer只創建1個MessageStream)數量少於Partition數量,則至少有一個Consumer會消費多個Partition的數據,如果Consumer的數量與Partition數量相同,則正好一個Consumer消費一個Partition的數據。而如果Consumer的數量多於Partition的數量時,會有部分Consumer無法消費該Topic下任何一條消息。
如下例所示,如果topic1有0,1,2共三個Partition,當group1只有一個Consumer(名爲consumer1)時,該 Consumer可消費這3個Partition的所有數據。

增加一個Consumer(consumer2)後,其中一個Consumer(consumer1)可消費2個Partition的數據(Partition 0和Partition 1),另外一個Consumer(consumer2)可消費另外一個Partition(Partition 2)的數據。
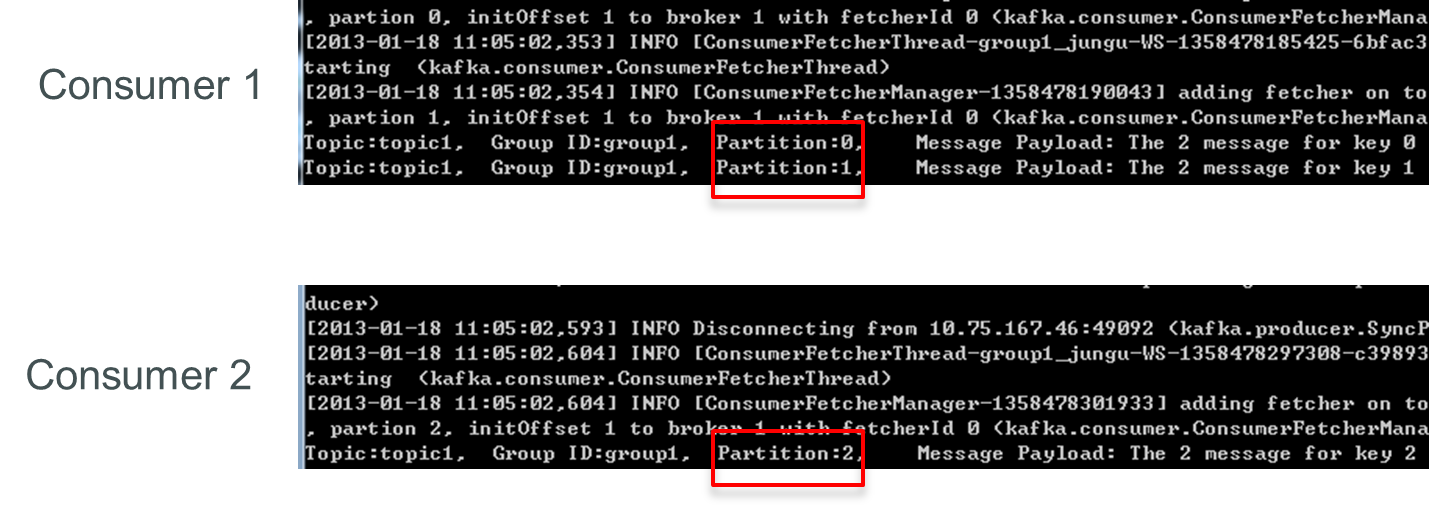
再增加一個Consumer(consumer3)後,每個Consumer可消費一個Partition的數據。consumer1消費partition0,consumer2消費partition1,consumer3消費partition2。
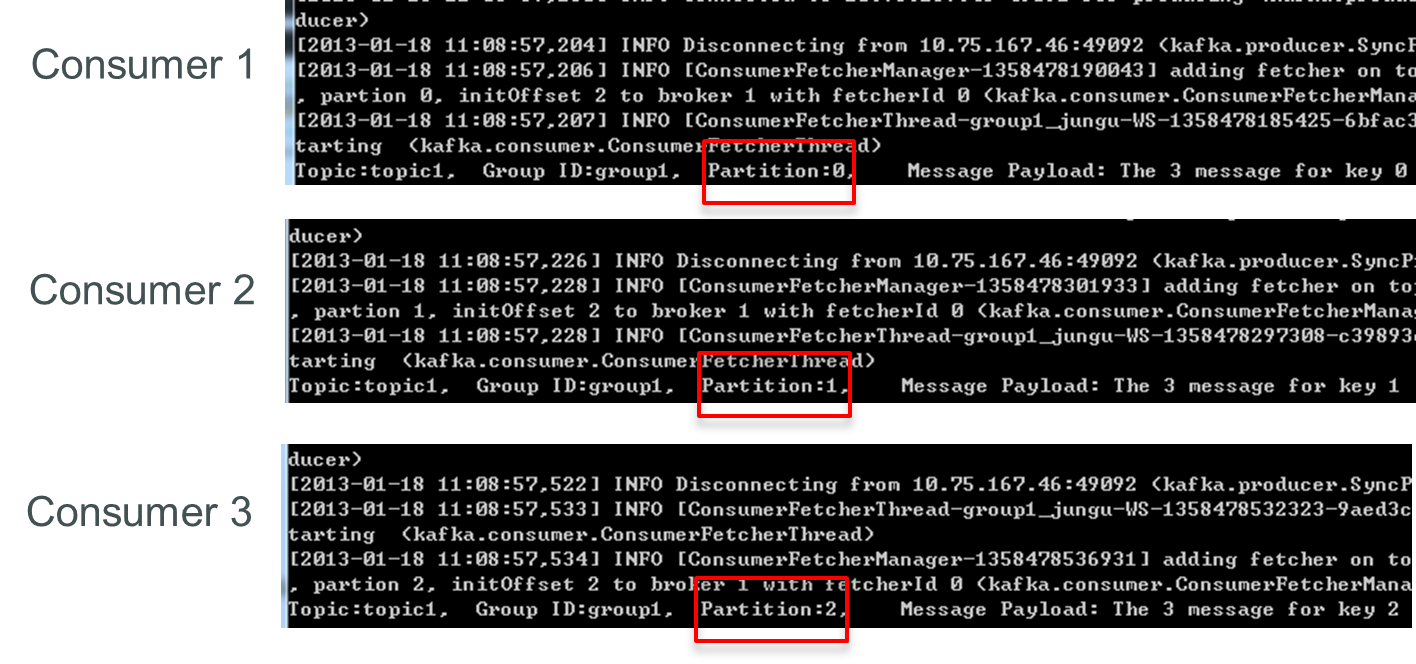
再增加一個Consumer(consumer4)後,其中3個Consumer可分別消費一個Partition的數據,另外一個Consumer(consumer4)不能消費topic1的任何數據。
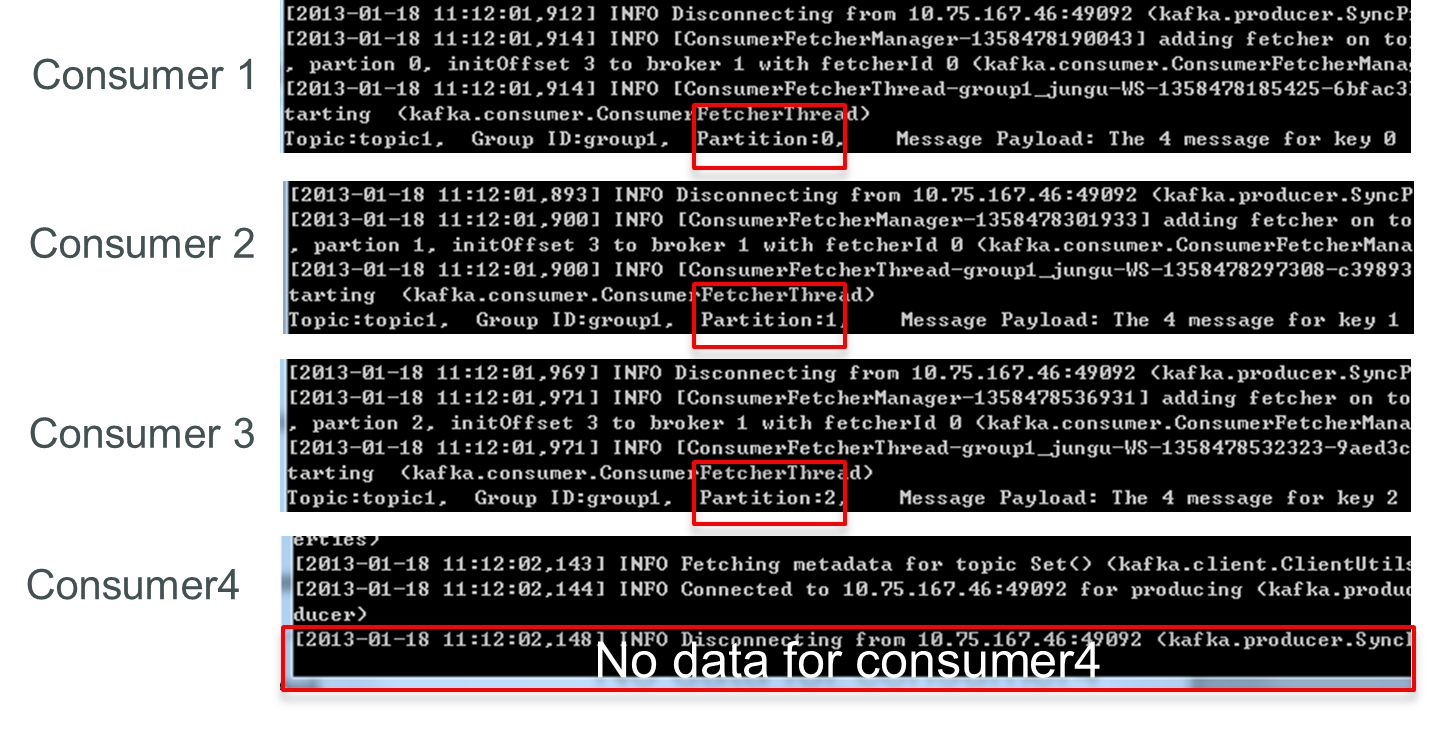
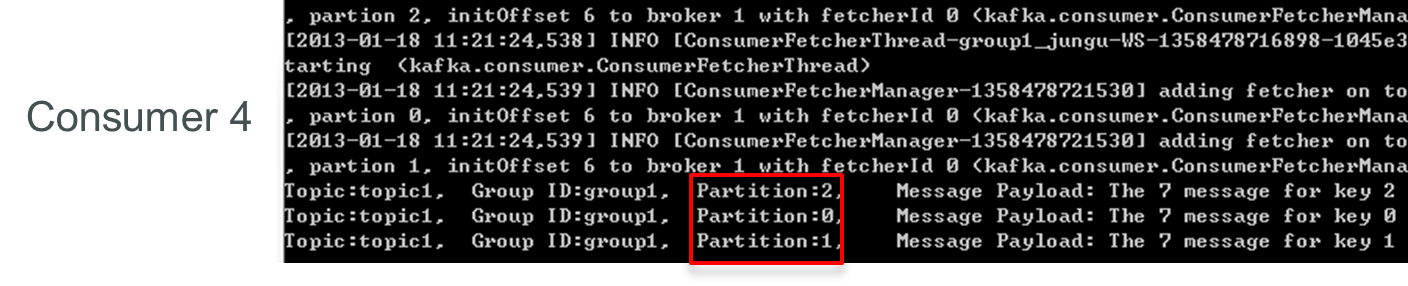
此時關閉consumer1,其餘3個Consumer可分別消費一個Partition的數據。
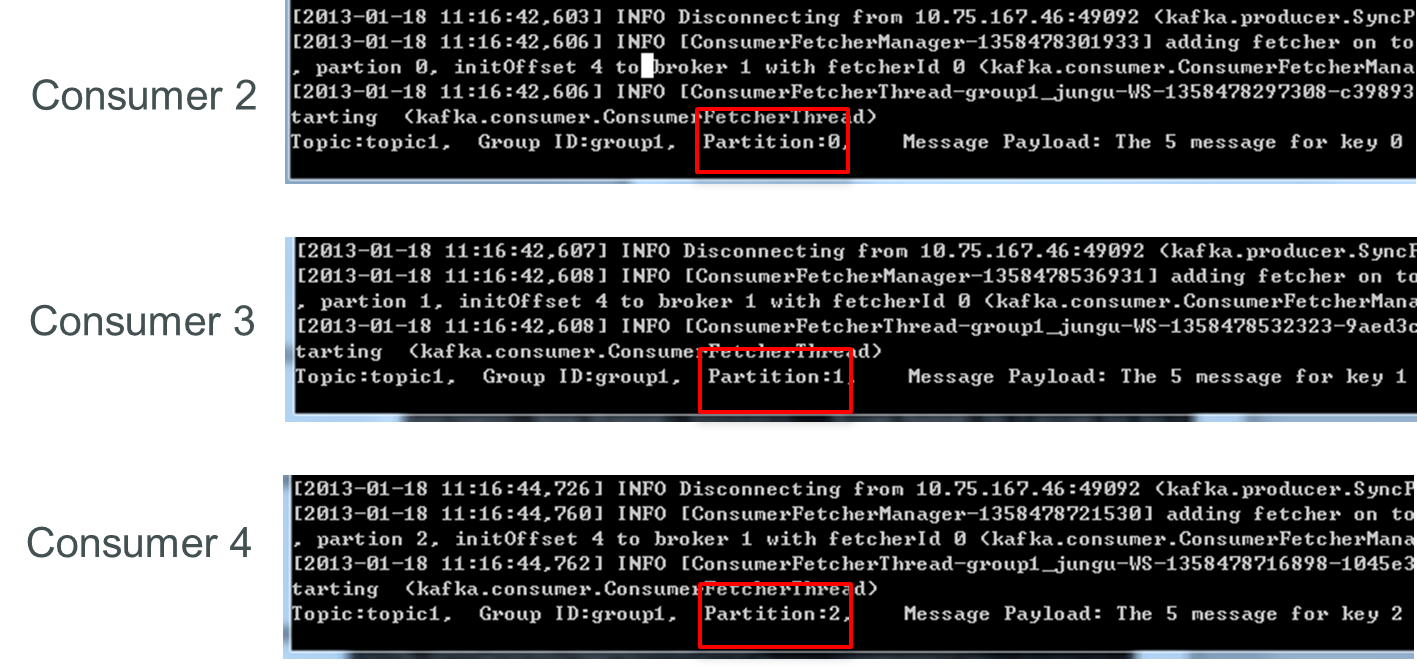
接着關閉consumer2,consumer3可消費2個Partition,consumer4可消費1個Partition。
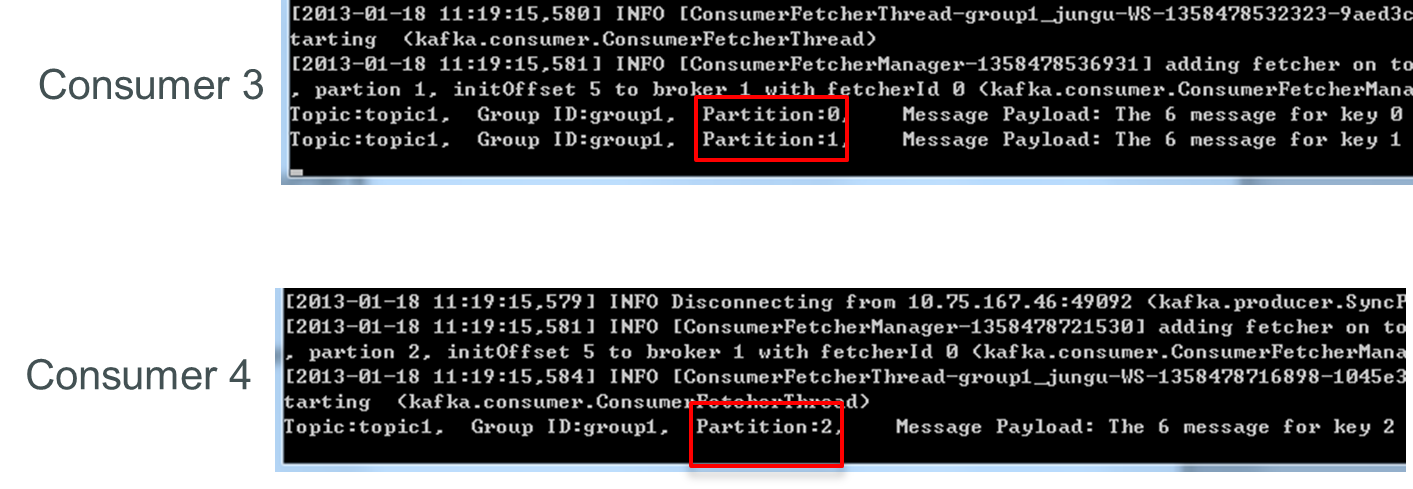
再關閉consumer3,僅存的consumer4可同時消費topic1的3個Partition。
Consumer Rebalance的算法如下:
將目標Topic下的所有Partirtion排序,存於PT
對某Consumer Group下所有Consumer排序,存於CG,第i個Consumer記爲Ci
N=size(PT)/size(CG),向上取整
解除Ci對原來分配的Partition的消費權(i從0開始)
將第i∗N到(i+1)∗N−1個Partition分配給Ci
目前,最新版(0.8.2.1)Kafka的Consumer Rebalance的控制策略是由每一個Consumer通過在Zookeeper上註冊Watch完成的。每個Consumer被創建時會觸發Consumer Group的Rebalance,具體啓動流程如下:
High Level Consumer啓動時將其ID註冊到其Consumer Group下,在Zookeeper上的路徑爲
/consumers/[consumer group]/ids/[consumer id]在
/consumers/[consumer group]/ids上註冊Watch在
/brokers/ids上註冊Watch如果Consumer通過Topic Filter創建消息流,則它會同時在
/brokers/topics上也創建Watch強制自己在其Consumer Group內啓動Rebalance流程
在這種策略下,每一個Consumer或者Broker的增加或者減少都會觸發Consumer Rebalance。因爲每個Consumer只負責調整自己所消費的Partition,爲了保證整個Consumer Group的一致性,當一個Consumer觸發了Rebalance時,該Consumer Group內的其它所有其它Consumer也應該同時觸發Rebalance。
該方式有如下缺陷:
Herd effect
任何Broker或者Consumer的增減都會觸發所有的Consumer的RebalanceSplit Brain
每個Consumer分別單獨通過Zookeeper判斷哪些Broker和Consumer 宕機了,那麼不同Consumer在同一時刻從Zookeeper“看”到的View就可能不一樣,這是由Zookeeper的特性決定的,這就會造成不正確的Reblance嘗試。調整結果不可控
所有的Consumer都並不知道其它Consumer的Rebalance是否成功,這可能會導致Kafka工作在一個不正確的狀態。
根據Kafka社區wiki,Kafka作者正在考慮在還未發佈的0.9.x版本中使用中心協調器(Coordinator)。大體思想是爲所有Consumer Group的子集選舉出一個Broker作爲Coordinator,由它Watch Zookeeper,從而判斷是否有Partition或者Consumer的增減,然後生成Rebalance命令,並檢查是否這些Rebalance在所有相關的Consumer中被執行成功,如果不成功則重試,若成功則認爲此次Rebalance成功(這個過程跟Replication Controller非常類似)。具體方案將在後文中詳細闡述。
Low Level Consumer
使用Low Level Consumer (Simple Consumer)的主要原因是,用戶希望比Consumer Group更好的控制數據的消費。比如:
同一條消息讀多次
只讀取某個Topic的部分Partition
管理事務,從而確保每條消息被處理一次,且僅被處理一次
與Consumer Group相比,Low Level Consumer要求用戶做大量的額外工作。
必須在應用程序中跟蹤offset,從而確定下一條應該消費哪條消息
應用程序需要通過程序獲知每個Partition的Leader是誰
必須處理Leader的變化
使用Low Level Consumer的一般流程如下
查找到一個“活着”的Broker,並且找出每個Partition的Leader
找出每個Partition的Follower
定義好請求,該請求應該能描述應用程序需要哪些數據
Fetch數據
識別Leader的變化,並對之作出必要的響應
Consumer重新設計
根據社區社區wiki,Kafka在0.9.*版本中,重新設計Consumer可能是最重要的Feature之一。本節會根據社區wiki介紹Kafka 0.9.*中對Consumer可能的設計方向及思路。
設計方向
簡化消費者客戶端
部分用戶希望開發和使用non-java的客戶端。現階段使用non-java發SimpleConsumer比較方便,但想開發High Level Consumer並不容易。因爲High Level Consumer需要實現一些複雜但必不可少的失敗探測和Rebalance。如果能將消費者客戶端更精簡,使依賴最小化,將會極大的方便non-java用戶實現自己的Consumer。
中心Coordinator
如上文所述,當前版本的High Level Consumer存在Herd Effect和Split Brain的問題。如果將失敗探測和Rebalance的邏輯放到一個高可用的中心Coordinator,那麼這兩個問題即可解決。同時還可大大減少Zookeeper的負載,有利於Kafka Broker的Scale Out。
允許手工管理offset
一些系統希望以特定的時間間隔在自定義的數據庫中管理Offset。這就要求Consumer能獲取到每條消息的metadata,例如Topic,Partition,Offset,同時還需要在Consumer啓動時得到每個Partition的Offset。實現這些,需要提供新的Consumer API。同時有個問題不得不考慮,即是否允許Consumer手工管理部分Topic的Offset,而讓Kafka自動通過Zookeeper管理其它Topic的Offset。一個可能的選項是讓每個Consumer只能選取1種Offset管理機制,這可極大的簡化Consumer API的設計和實現。
Rebalance後觸發用戶指定的回調
一些應用可能會在內存中爲每個Partition維護一些狀態,Rebalance時,它們可能需要將該狀態持久化。因此該需求希望支持用戶實現並指定一些可插拔的並在Rebalance時觸發的回調。如果用戶使用手動的Offset管理,那該需求可方便得由用戶實現,而如果用戶希望使用Kafka提供的自動Offset管理,則需要Kafka提供該回調機制。
非阻塞式Consumer API
該需求源於那些實現高層流處理操作,如filter by, group by, join等,的系統。現階段的阻塞式Consumer幾乎不可能實現Join操作。
##如何通過中心Coordinator實現Rebalance
成功Rebalance的結果是,被訂閱的所有Topic的每一個Partition將會被Consumer Group內的一個(有且僅有一個)Consumer擁有。每一個Broker將被選舉爲某些Consumer Group的Coordinator。某個Cosnumer Group的Coordinator負責在該Consumer Group的成員變化或者所訂閱的Topic的Partititon變化時協調Rebalance操作。
Consumer
1) Consumer啓動時,先向Broker列表中的任意一個Broker發送ConsumerMetadataRequest,並通過ConsumerMetadataResponse獲取它所在Group的Coordinator信息。ConsumerMetadataRequest和ConsumerMetadataResponse的結構如下
ConsumerMetadataRequest
{
GroupId => String
}
ConsumerMetadataResponse
{
ErrorCode => int16
Coordinator => Broker
}
2)Consumer連接到Coordinator併發送HeartbeatRequest,如果返回的HeartbeatResponse沒有任何錯誤碼,Consumer繼續fetch數據。若其中包含IllegalGeneration錯誤碼,即說明Coordinator已經發起了Rebalance操作,此時Consumer停止fetch數據,commit offset,併發送JoinGroupRequest給它的Coordinator,並在JoinGroupResponse中獲得它應該擁有的所有Partition列表和它所屬的Group的新的Generation ID。此時Rebalance完成,Consumer開始fetch數據。相應Request和Response結構如下
HeartbeatRequest
{
GroupId => String
GroupGenerationId => int32
ConsumerId => String
}
HeartbeatResponse
{
ErrorCode => int16
}
JoinGroupRequest
{
GroupId => String
SessionTimeout => int32
Topics => [String]
ConsumerId => String
PartitionAssignmentStrategy => String
}
JoinGroupResponse
{
ErrorCode => int16
GroupGenerationId => int32
ConsumerId => String
PartitionsToOwn => [TopicName [Partition]]
}
TopicName => String
Partition => int32CoordinatorConsumer狀態機
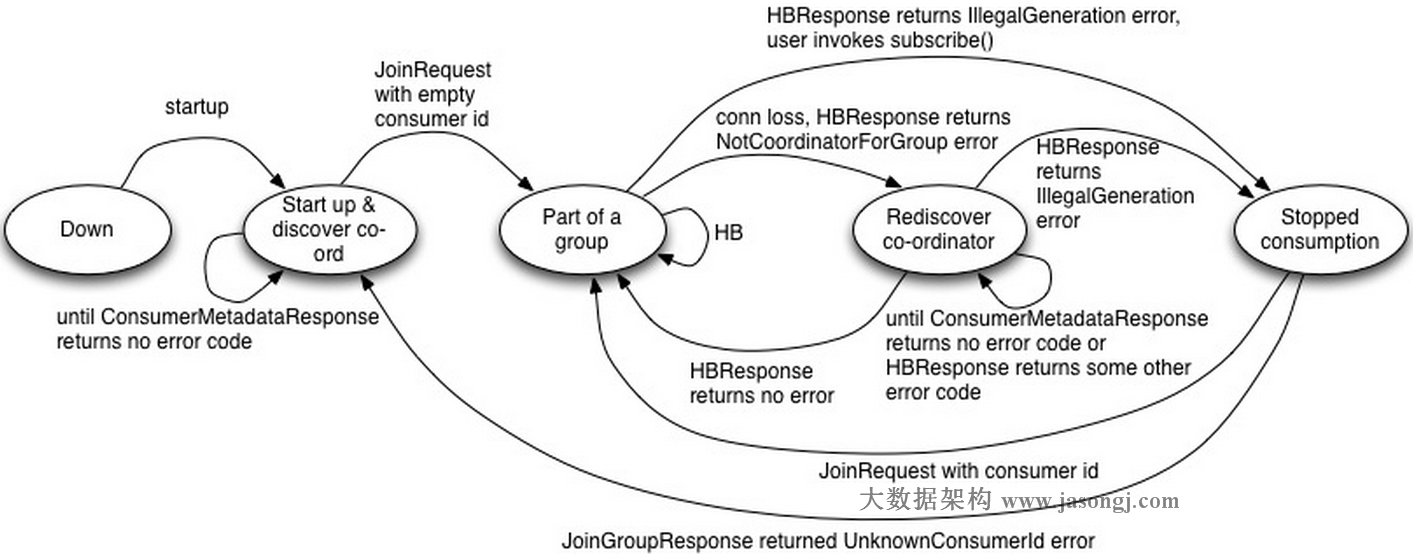
Down:Consumer停止工作
Start up & discover coordinator:Consumer檢測其所在Group的Coordinator。一旦它檢測到Coordinator,即向其發送JoinGroupRequest。
Part of a group:該狀態下,Consumer已經是該Group的成員,並週期性發送HeartbeatRequest。如HeartbeatResponse包含IllegalGeneration錯誤碼,則轉換到Stopped Consumption狀態。若連接丟失,HeartbeatResponse包含NotCoordinatorForGroup錯誤碼,則轉換到Rediscover coordinator狀態。
Rediscover coordinator:該狀態下,Consumer不停止消費而是嘗試通過發送ConsumerMetadataRequest來探測新的Coordinator,並且等待直到獲得無錯誤碼的響應。
Stopped consumption:該狀態下,Consumer停止消費並提交offset,直到它再次加入Group。
故障檢測機制
Consumer成功加入Group後,Consumer和相應的Coordinator同時開始故障探測程序。Consumer向Coordinator發起週期性的Heartbeat(HeartbeatRequest)並等待響應,該週期爲 session.timeout.ms/heartbeat.frequency。若Consumer在session.timeout.ms內未收到HeartbeatResponse,或者發現相應的Socket channel斷開,它即認爲Coordinator已宕機並啓動Coordinator探測程序。若Coordinator在session.timeout.ms內沒有收到一次HeartbeatRequest,則它將該Consumer標記爲宕機狀態併爲其所在Group觸發一次Rebalance操作。
Coordinator Failover過程中,Consumer可能會在新的Coordinator完成Failover過程之前或之後發現新的Coordinator並向其發送HeatbeatRequest。對於後者,新的Cooodinator可能拒絕該請求,致使該Consumer重新探測Coordinator併發起新的連接請求。如果該Consumer向新的Coordinator發送連接請求太晚,新的Coordinator可能已經在此之前將其標記爲宕機狀態而將之視爲新加入的Consumer並觸發一次Rebalance操作。
1)穩定狀態下,Coordinator通過上述故障探測機制跟蹤其所管理的每個Group下的每個Consumer的健康狀態。
2)剛啓動時或選舉完成後,Coordinator從Zookeeper讀取它所管理的Group列表及這些Group的成員列表。如果沒有獲取到Group成員信息,它不會做任何事情直到某個Group中有成員註冊進來。
3)在Coordinator完成加載其管理的Group列表及其相應的成員信息之前,它將爲HeartbeatRequest,OffsetCommitRequest和JoinGroupRequests返回CoordinatorStartupNotComplete錯誤碼。此時,Consumer會重新發送請求。
4)Coordinator會跟蹤被其所管理的任何Consumer Group註冊的Topic的Partition的變化,併爲該變化觸發Rebalance操作。創建新的Topic也可能觸發Rebalance,因爲Consumer可以在Topic被創建之前就已經訂閱它了。
Coordinator發起Rebalance操作流程如下所示。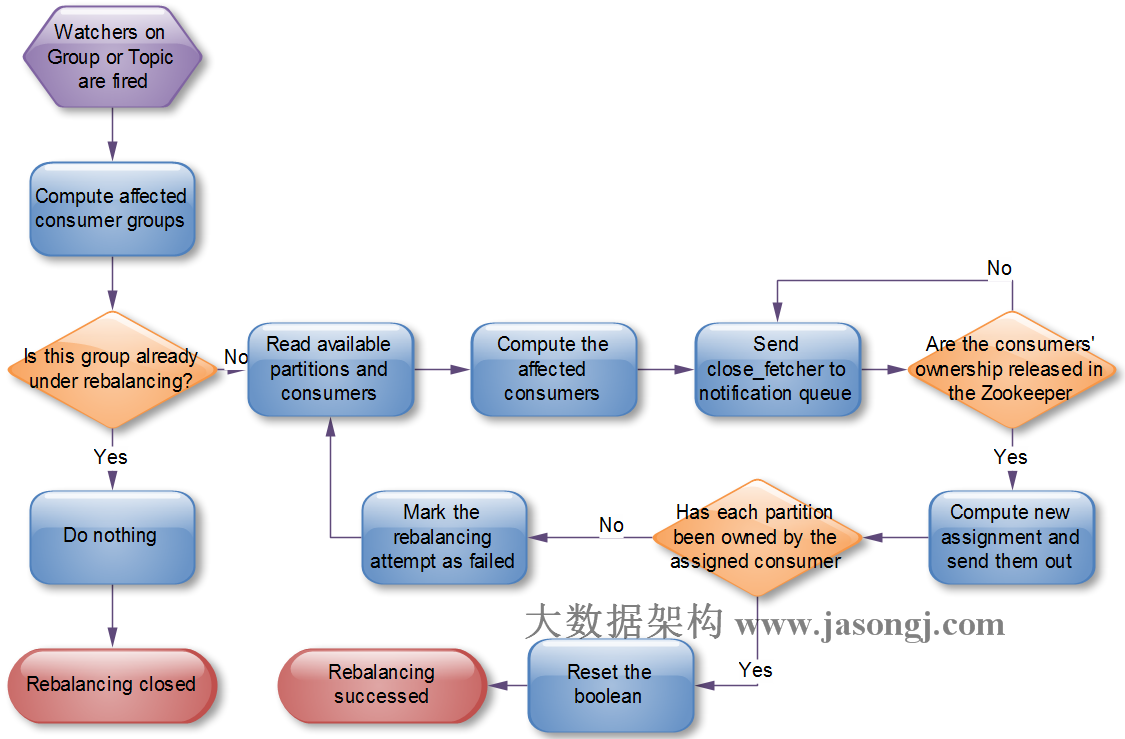
Coordinator狀態機
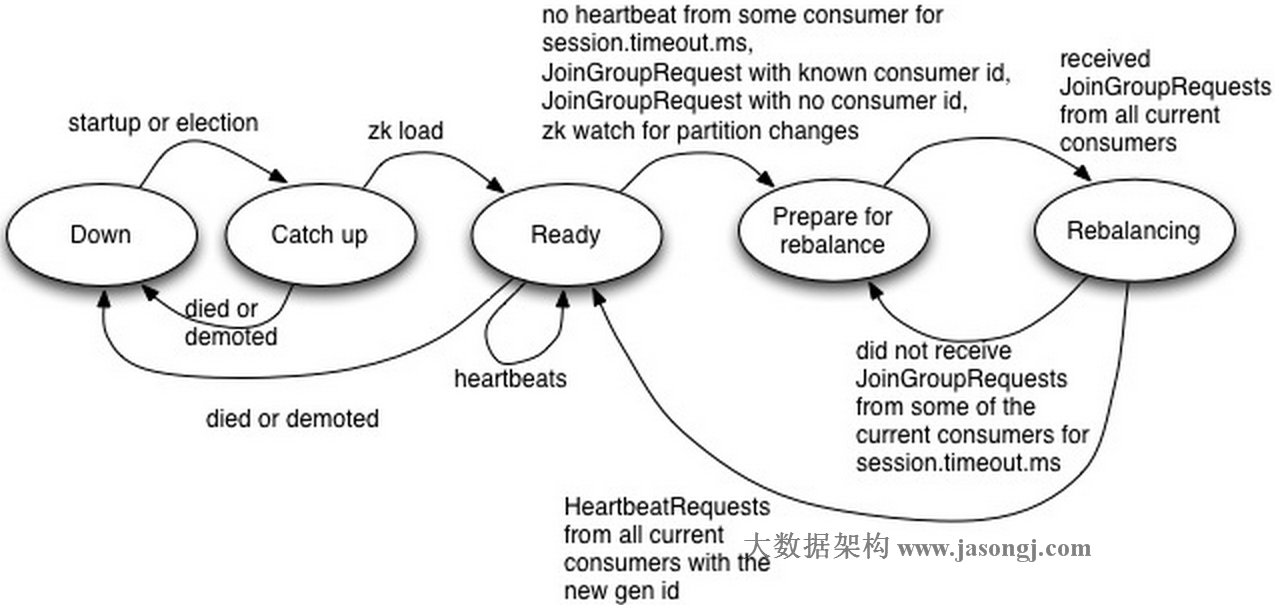
Down:Coordinator不再擔任之前負責的Consumer Group的Coordinator
Catch up:該狀態下,Coordinator競選成功,但還未能做好服務相應請求的準備。
Ready:該狀態下,新競選出來的Coordinator已經完成從Zookeeper中加載它所負責管理的所有Group的metadata,並可開始接收相應的請求。
Prepare for rebalance:該狀態下,Coordinator在所有HeartbeatResponse中返回IllegalGeneration錯誤碼,並等待所有Consumer向其發送JoinGroupRequest後轉到Rebalancing狀態。
Rebalancing:該狀態下,Coordinator已經收到了JoinGroupRequest請求,並增加其Group Generation ID,分配Consumer ID,分配Partition。Rebalance成功後,它會等待接收包含新的Consumer Generation ID的HeartbeatRequest,並轉至Ready狀態。
Coordinator Failover
如前文所述,Rebalance操作需要經歷如下幾個階段
1)Topic/Partition的改變或者新Consumer的加入或者已有Consumer停止,觸發Coordinator註冊在Zookeeper上的watch,Coordinator收到通知準備發起Rebalance操作。
2)Coordinator通過在HeartbeatResponse中返回IllegalGeneration錯誤碼發起Rebalance操作。
3)Consumer發送JoinGroupRequest
4)Coordinator在Zookeeper中增加Group的Generation ID並將新的Partition分配情況寫入Zookeeper
5)Coordinator發送JoinGroupResponse
在這個過程中的每個階段,Coordinator都可能出現故障。下面給出Rebalance不同階段中Coordinator的Failover處理方式。
1)如果Coordinator的故障發生在第一階段,即它收到Notification並未來得及作出響應,則新的Coordinator將從Zookeeper讀取Group的metadata,包含這些Group訂閱的Topic列表和之前的Partition分配。如果某個Group所訂閱的Topic數或者某個Topic的Partition數與之前的Partition分配不一致,亦或者某個Group連接到新的Coordinator的Consumer數與之前Partition分配中的不一致,新的Coordinator會發起Rebalance操作。
2)如果失敗發生在階段2,它可能對部分而非全部Consumer發出帶錯誤碼的HeartbeatResponse。與第上面第一種情況一樣,新的Coordinator會檢測到Rebalance的必要性併發起一次Rebalance操作。如果Rebalance是由Consumer的失敗所觸發並且Cosnumer在Coordinator的Failover完成前恢復,新的Coordinator不會爲此發起新的Rebalance操作。
3)如果Failure發生在階段3,新的Coordinator可能只收到部分而非全部Consumer的JoinGroupRequest。Failover完成後,它可能收到部分Consumer的HeartRequest及另外部分Consumer的JoinGroupRequest。與第1種情況類似,它將發起新一輪的Rebalance操作。
4)如果Failure發生在階段4,即它將新的Group Generation ID和Group成員信息寫入Zookeeper後。新的Generation ID和Group成員信息以一個原子操作一次性寫入Zookeeper。Failover完成後,Consumer會發送HeartbeatRequest給新的Coordinator,幷包含舊的Generation ID。此時新的Coordinator通過在HeartbeatResponse中返回IllegalGeneration錯誤碼發起新的一輪Rebalance。這也解釋了爲什麼每次HeartbeatRequest中都需要包含Generation ID和Consumer ID。
5)如果Failure發生在階段5,舊的Coordinator可能只向Group中的部分Consumer發送了JoinGroupResponse。收到JoinGroupResponse的Consumer在下次向已經失效的Coordinator發送HeartbeatRequest或者提交Offset時會檢測到它已經失敗。此時,它將檢測新的Coordinator並向其發送帶有新的Generation ID 的HeartbeatRequest。而未收到JoinGroupResponse的Consumer將檢測新的Coordinator並向其發送JoinGroupRequest,這將促使新的Coordinator發起新一輪的Rebalance。
點擊鏈接加入羣【悅分享測試聯盟】:https://jq.qq.com/?_wv=1027&k=5DiePik