




如果這是第二次看到我的文章,歡迎文末掃碼訂閱我的個人公衆號(跨界架構師)喲~
本文長度爲4229字,建議閱讀11分鐘。
這是本系列中既「數據一致性」後的第二章節——「高可用」的完結篇。
前面幾篇中z哥跟你聊了聊做「高可用」的意義,以及如何做「負載均衡」和「高可用三劍客」(熔斷、限流、降級,文末會附上前文連接:))。這次,我們來聊一聊在保證對外高可用的同時,憋出的“內傷”該如何通過「補償」機制來自行消化。
一、「補償」機制的意義?
以電商的購物場景爲例:
客戶端 ---->購物車微服務 ---->訂單微服務 ----> 支付微服務。
這種調用鏈非常普遍。
那麼爲什麼需要考慮補償機制呢?
正如之前幾篇文章所說,一次跨機器的通信可能會經過DNS 服務,網卡、交換機、路由器、負載均衡等設備,這些設備都不一定是一直穩定的,在數據傳輸的整個過程中,只要任意一個環節出錯,都會導致問題的產生。
而在分佈式場景中,一個完整的業務又是由多次跨機器通信組成的,所以產生問題的概率成倍數增加。
但是,這些問題並不完全代表真正的系統無法處理請求,所以我們應當儘可能的自動消化掉這些異常。
可能你會問,之前也看到過「補償」和「事務補償」或者「重試」,它們之間的關係是什麼?
你其實可以不用太糾結這些名字,從目的來說都是一樣的。就是一旦某個操作發生了異常,如何通過內部機制將這個異常產生的「不一致」狀態消除掉。
題外話:在Z哥看來,不管用什麼方式,只要通過額外的方式解決了問題都可以理解爲是「補償」,所以「事務補償」和「重試」都是「補償」的子集。前者是一個逆向操作,而後者則是一個正向操作。
只是從結果來看,兩者的意義不同。「事務補償」意味着“放棄”,當前操作必然會失敗。
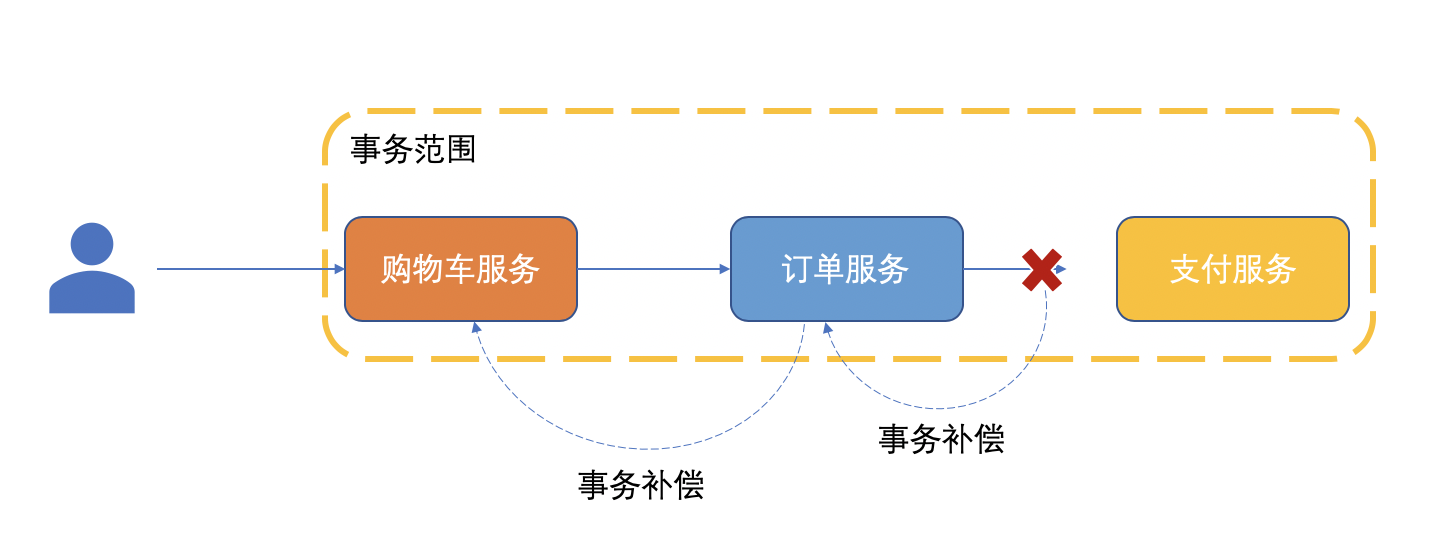
▲事務補償
「重試」則還有處理成功的機會。這兩種方式分別適用於不同的場景。
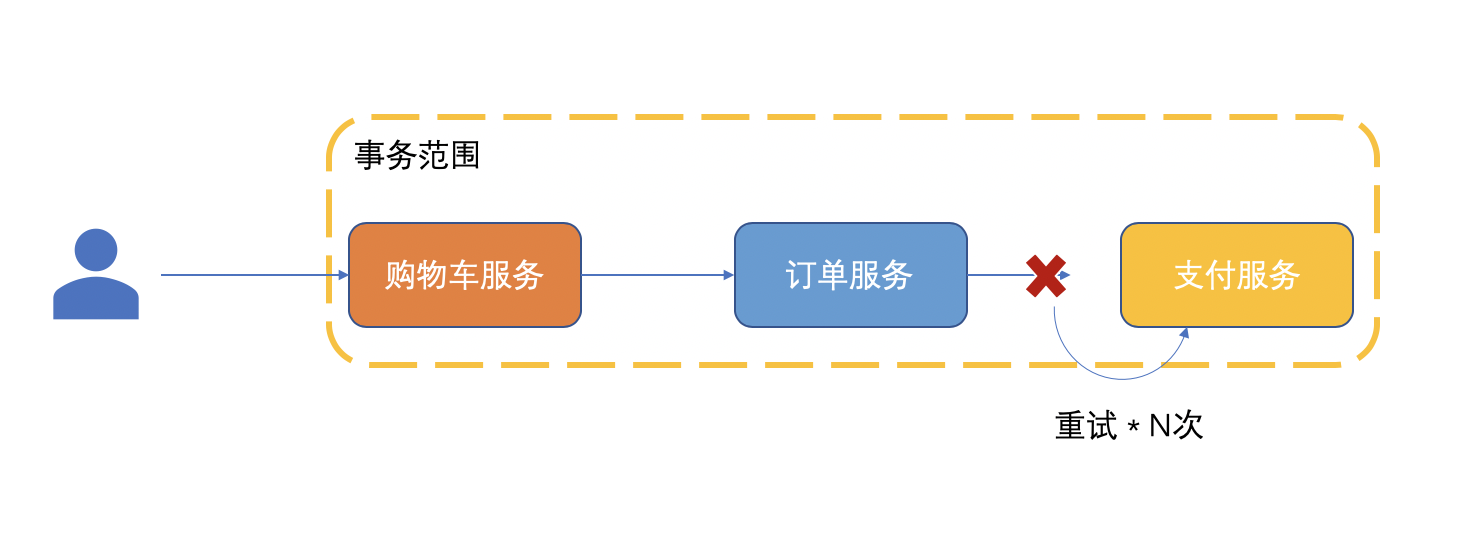
▲重試
因爲「補償」已經是一個額外流程了,既然能夠走這個額外流程,說明時效性並不是第一考慮的因素,所以做補償的核心要點是:寧可慢,不可錯。
因此,不要草率的就確定了補償的實施方案,需要謹慎的評估。雖說錯誤無法100%避免,但是抱着這樣的一個心態或多或少可以減少一些錯誤的發生。
二、「補償」該怎麼做?
做「補償」的主流方式就前面提到的「事務補償」和「重試」,以下會被稱作「回滾」和「重試」。
我們先來聊聊「回滾」。相比「重試」,它邏輯上更簡單一些。
「回滾」
Z哥將回滾分爲2種模式,一種叫「顯式回滾」(調用逆向接口),一種叫「隱式回滾」(無需調用逆向接口)。
最常見的就是「顯式回滾」。這個方案無非就是做2個事情:
首先要確定失敗的步驟和狀態,從而確定需要回滾的範圍。一個業務的流程,往往在設計之初就制定好了,所以確定回滾的範圍比較容易。但這裏唯一需要注意的一點就是:如果在一個業務處理中涉及到的服務並不是都提供了「回滾接口」,那麼在編排服務時應該把提供「回滾接口」的服務放在前面,這樣當後面的工作服務錯誤時還有機會「回滾」。
其次要能提供「回滾」操作使用到的業務數據。「回滾」時提供的數據越多,越有益於程序的健壯性。因爲程序可以在收到「回滾」操作的時候可以做業務的檢查,比如檢查賬戶是否相等,金額是否一致等等。
由於這個中間狀態的數據結構和數據大小並不固定,所以Z哥建議你在實現這點的時候可以將相關的數據序列化成一個json,然後存放到一個nosql類型的存儲中。
「隱式回滾」相對來說運用場景比較少。它意味着這個回滾動作你不需要進行額外處理,下游服務內部有類似“預佔”並且“超時失效”的機制的。例如:
電商場景中,會將訂單中的商品先預佔庫存,等待用戶在 15 分鐘內支付。如果沒有收到用戶的支付,則釋放庫存。
下面聊聊可以有很多玩法,也更容易陷入坑裏的「重試」。
「重試」
「重試」最大的好處在於,業務系統可以不需要提供「逆向接口」,這是一個對長期開發成本特別大的利好,畢竟業務是天天在變的。所以,在可能的情況下,應該優先考慮使用「重試」。
不過,相比「回滾」來說「重試」的適用場景更少一些,所以我們第一步首先要判斷,當前場景是否適合「重試」。比如:
下游系統返回「請求超時」、「被限流中」等臨時狀態的時候,我們可以考慮重試
而如果是返回“餘額不足”、“無權限”等明確無法繼續的業務性錯誤的時候就不需要重試了
一些中間件或者rpc框架中返回Http503、404等沒有何時恢復的預期的時候,也不需要重試
如果確定要進行「重試」,我們還需要選定一個合適的「重試策略」。主流的「重試策略」主要是以下幾種。
策略1.立即重試。有時故障是候暫時性,可能是因網絡數據包衝突或硬件組件流量高峯等事件造成的。在此情況下,適合立即重試操作。不過,立即重試次數不應超過一次,如果立即重試失敗,應改用其它的策略。
策略2.固定間隔。應用程序每次嘗試的間隔時間相同。 這個好理解,例如,固定每 3 秒重試操作。(以下所有示例代碼中的具體的數字僅供參考。)
策略1和策略2多用於前端系統的交互式操作中。
策略3.增量間隔。每一次的重試間隔時間增量遞增。比如,第一次0秒、第二次3秒、第三次6秒,9、12、15這樣。
return (retryCount - 1) * incrementInterval;
使得失敗次數越多的重試請求優先級排到越後面,給新進入的重試請求讓道。
策略4.指數間隔。每一次的重試間隔呈指數級增加。和增量間隔“殊途同歸”,都是想讓失敗次數越多的重試請求優先級排到越後面,只不過這個方案的增長幅度更大一些。
return 2 ^ retryCount;
策略5.全抖動。在遞增的基礎上,增加隨機性(可以把其中的指數增長部分替換成增量增長。)。適用於將某一時刻集中產生的大量重試請求進行壓力分散的場景。
return random(0 , 2 ^ retryCount);
策略6.等抖動。在「指數間隔」和「全抖動」之間尋求一箇中庸的方案,降低隨機性的作用。適用場景和「全抖動」一樣。
var baseNum = 2 ^ retryCount;return baseNum + random(0 , baseNum);
3、4、5、6策略的表現情況大致是這樣。(x軸爲重試次數)

爲什麼說「重試」有坑呢?
正如前面聊到的那樣,出於對開發成本考慮,你在做「重試」的時候可能是複用的常規調用的接口。那麼此時就不得不提一個「冪等性」問題。
如果實現「重試」選用的技術方案不能100%確保不會重複發起重試,那麼「冪等性」問題是一個必須要考慮的問題。哪怕技術方案可以確保100%不會重複發起重試,出於對意外情況的考量,儘量也考慮一下「冪等性」問題。
冪等性:不管對程序發起幾次重複調用,程序表現的狀態(所有相關的數據變化)與調用一次的結果是一致的話,就是保證了冪等性。
這意味着可以根據需要重複或重試操作,而不會導致意外的影響。對於非冪等操作,算法可能必須跟蹤操作是否已經執行。
所以,一旦某個功能支持「重試」,那麼整個鏈路上的接口都需要考慮冪等性問題,不能因爲服務的多次調用而導致業務數據的累計增加或減少。
滿足「冪等性」其實就是需要想辦法識別重複的請求,並且將其過濾掉。思路就是:
給每個請求定義一個唯一標識。
在進行「重試」的時候判斷這個請求是否已經被執行或者正在被執行,如果是則拋棄該請求。
第1點,我們可以使用一個全局唯一id生成器或者生成服務(可以擴展閱讀,分佈式系統中的必備良藥 —— 全局唯一單據號生成)。 或者簡單粗暴一些,使用官方類庫自帶的Guid、uuid之類的也行。
然後通過rpc框架在發起調用的客戶端中,對每個請求增加一個唯一標識的字段進行賦值。
第2點,我們可以在服務端通過Aop的方式切入到實際的處理邏輯代碼之前和之後,一起配合做驗證。
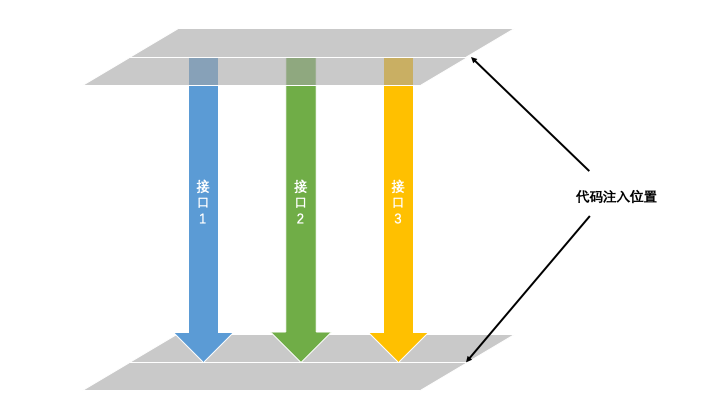
大致的代碼思路如下。
【方法執行前】if(isExistLog(requestId)){ //1.判斷請求是否已被接收過。 對應序號3
var lastResult = getLastResult(); //2.獲取用於判斷之前的請求是否已經處理完成。 對應序號4
if(lastResult == null){
var result = waitResult(); //掛起等待處理完成
return result;
}
else{
return lastResult;
}
}
else{
log(requestId); //3.記錄該請求已接收
}
//do something..【方法執行後】
logResult(requestId, result); //4.將結果也更新一下。
如果「補償」這個工作是通過MQ來進行的話,這事就可以直接在對接MQ所封裝的SDK中做。在生產端賦值全局唯一標識,在消費端通過唯一標識消重。
三、「重試」的最佳實踐
再聊一些Z哥積累的最佳實踐吧(劃重點:)),都是針對「重試」的,的確這也是工作中最常用的方案。
「重試」特別適合在高負載情況下被「降級」,當然也應當受到「限流」和「熔斷」機制的影響。當「重試」的“矛”與「限流」和「熔斷」的“盾”搭配使用,效果纔是最好。
需要衡量增加補償機制的投入產出比。一些不是很重要的問題時,應該「快速失敗」而不是「重試」。
過度積極的重試策略(例如間隔太短或重試次數過多)會對下游服務造成不利影響,這點一定要注意。
一定要給「重試」制定一個終止策略。
當回滾的過程很困難或代價很大的情況下,可以接受很長的間隔及大量的重試次數,DDD中經常被提到的「saga」模式其實也是這樣的思路。不過,前提是不會因爲保留或鎖定稀缺資源而阻止其他操作(比如1、2、3、4、5幾個串行操作。由於2一直沒處理完成導致3、4、5沒法繼續進行)。
四、總結
這篇我們先聊了下做「補償」的意義,以及做補償的2個方式「回滾」和「重試」的實現思路。
然後,提醒你要注意「重試」的時候需要考慮冪等性問題,並且z哥也給出了一個解決思路。
最後,分享了幾個z哥總結的針對「重試」的最佳實踐。
希望對你有所幫助。
Question:
你之前有哪些時候是通過自己人工來做「補償」的經歷嗎?歡迎吐槽~
z哥自己就有多次熬到半夜才把“意外”造成的混亂清理乾淨,刻骨銘心啊