




linux上文本處理上劍客:
grep:文本過濾工具(模式:pattern)工具;
grep:基本正則表達式, -E -F
egrep:擴展正則表達式,-G -F
fgrep: 不支持正則表達式,
sed:stream editor.流編輯器;文本編輯工具;
awk:linux上的實現爲gawk,文本報告生成器(格式化文本);
正則表達式:
由一類特殊字符及文本字符所編寫的模式,其中有些字符不表示其字面意義,而是用於
表示控制或通配的功能;
分兩類:
基本正則表達式:BRE
擴展正則表達式:ERE
元字符: \(hello[[:space:]]\+\)\+ grep:global search Regular expresslon and print out the line.
作用:文本搜索工具,根據用戶指定的“模式(過濾條件)”對目標文本逐行進行匹配
檢查;打印報表到的行;
模式:由正則表達式的元字符及文本字符所編寫出的過濾條件;
正則表達式引擎:
grep [options] PATTERN [FILE...]
grep [options] [-e PATTERN | -f FILE] [FILE...]
選項:
grep='grep --color=auto'
-i:忽略字符的大小寫;
-o:只輸出文件中匹配到的部分
-v:反轉查找
-E:支持使用擴展的正則表達式元字符;
-q: --quiet, --silent;靜默模式,即不輸出任何信息;
-A#:after,後#行
-B#:before,前#行
-C#:context,前後各#行 實例:
顯示/etc/passwd文件中root的後兩行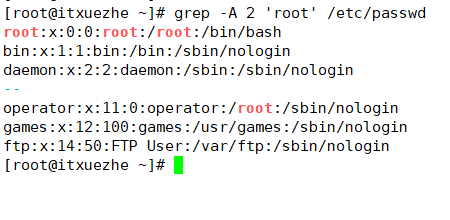
顯示/etc/passwd文件中root的前後兩行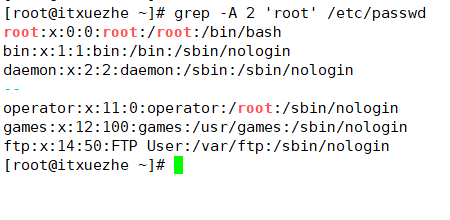
基本正則表達式元字符:
字符匹配:
. :匹配任意單個字符;
[] :匹配指定範圍內的任意單個字符;
[^] :匹配指定範圍外的任意單個字符;
[a-z],[A-Z],[0-9],[a-z0-9]
[[:upper:]] :所有大寫字母
[[:lower:]]:所有小寫字母
[[:alpha:]]:所有字母
[[:digit:]]:所有數字
[[:alnum:]]:所有數字和字母
[[:space:]]:所有空白字符
[[:punct:]]:所有標點符號
[^]: 匹配指定範圍外的任意單個字符
[^[:upper:]]
[^0-9]
[^[:alnum:]]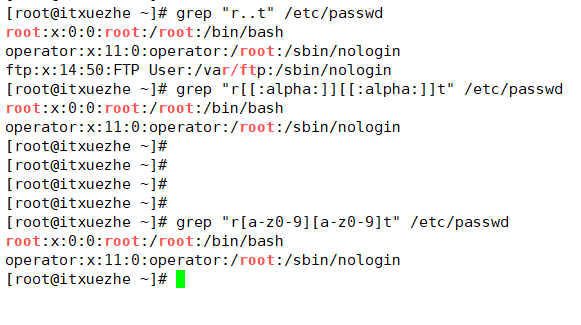
匹配次數:用在要指定其出現的次數的字符的後面,用於限制其前面字符出現的次數;默認工作於貪婪模式;
*:匹配其前面的字符任意次;0,1,多次;
.* :匹配任意長度的任意字符;
\? :匹配其前面的字符 0 次或 1 次;即其前面的字符是可有可無的;
\+ :匹配其前面的字符 1 次或多次;即其前面的字符要出現
\{m\}:匹配其前面的字符 m次;
\{m,n\}:匹配其前面的字符至少 m次,至多 n 次;
\{0,n}:至多 n 次;
\{m,\}:至少 m次; 位置錨定:
^:行首錨定:用於模式的最左側;
$:行尾錨定:用於模式的最右側;
^PATTERN$:用於PATTERN來匹配整行;
^$ :空白行;
^[[:space:]]*$: 空行或包含空白字符的行;
單詞:非特殊字符組成的連續字符(字符串)都稱爲單詞;
\<或\b :詞首錨定,用於單詞模式的左側;
\>或\b :詞尾錨定,用於單詞模式的右側;
\<PATERN\>:匹配完整單詞;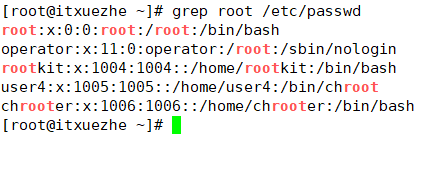
實例:
行首錨定: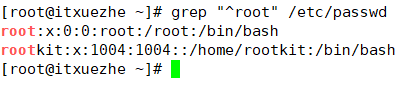
行尾錨定: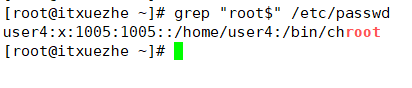

分組和引用:
\(\):將一個或多個字符捆綁在一起,當作一個整體進行處理;
\(xy\)*ab :表示 xy可以出現 0 次 1 次或多次; Note:分組括號中的模式匹配到的內容會被正則表達式引擎自動記錄於內部的變量中,這些
變量爲:
\1:模式從左側起,第一個左括號以及與之匹配右括號之間的模式所匹配到的字符;
\2:模式從左側起,第二個左括號以及與之匹配右括號之間的模式所匹配到的字符;
\3:
~]#grep “\(l..e\).*1” lovers.txt
後向引用:引用前面的分組括號中的模式所匹配到的字符;egrep: 支持擴展的正則表達式
選項:
-i:忽略字符的大小寫; -o:只輸出文件中匹配到的部分 -v:反轉查找
-q: --quiet, --silent;靜默模式,即不輸出任何信息;
-G:支持基本正則表達式;
-A#:after,後#行
-B#:before,前#行
-C#:context,前後各#行 擴展正則表達式的元字符;
字符匹配:
. :匹配任意單個字符;
[] :匹配指定範圍內的任意單個字符;
[^]:匹配指定範圍外的任意單個字符;
次數匹配
*:匹配其前面的字符任意次;0,1,多次;
* :匹配任意長度的任意字符;
? :匹配其前面的字符 0 次或 1 次;即其前面的字符是可有可無的;
+ :匹配其前面的字符 1 次或多次;即其前面的字符要出現
{m}:匹配其前面的字符 m次;
{m,n}:匹配其前面的字符至少 m次,至多 n 次;
{0,n}:至多 n 次;
{m}:至少 m次;
位置錨定:
^:行首錨定:用於模式的最左側;
$:行尾錨定:用於模式的最右側;
\<, \b :詞首錨定;
\>, \b:詞尾錨定;
分組及引用:
():分組:括號內的模式匹配到的字符會被記錄於正則表達式引擎的內部變量中;
後向引用: \1, \2 ,…
或 : a|b: a 或者 b; c|cat:c 或 cat
實例: ~]# grep -E "\<[0-9]{2,3}\>" /etc/passwd 
fgrep:不支持正則表達式元字符:
當無需要用到元字符編寫模式時,使用fgrep必能更好;