




衆所周知,美團爲用戶提供了全方位的生活服務,包括外賣、出行、甚至是零售和生鮮等方面。

面對紛繁複雜的服務與選項,用戶怎樣才能快速地找到自己想要的結果呢?這就需要美團平臺的搜索服務來幫忙。

2018 年 11 月 30 日-12 月 1 日,由 51CTO 主辦的 WOT 全球人工智能技術峯會在北京粵財 JW 萬豪酒店隆重舉行。
本次峯會以人工智能爲主題,來自美團的高級算法技術專家蔣前程在推薦搜索專場,從美團搜索的主要特點,以及他們是如何使用自己的算法模型去應對挑戰等方面,向大家介紹《美團 O2O 服務搜索的深度學習實踐》。
美團搜索業務現狀

目前,美團搜索覆蓋了平臺 40% 的交易,具有所謂千萬級的 POI(Point of Interest,興趣點)和億級別的 SPU(Standard Product Unit,標準化產品單元),而且用戶每天的搜索頻次(即:日 PV),也能達到億級。

那麼,美團搜索具體涉及到哪些方面呢?如上圖所示,除了左圖上方的首頁搜索欄,其下方的各個業務頻道里的搜索服務,也是由我們團隊來負責的。
因此,我們搜索的服務目標可分爲許多種,包括:主體 POI,每個 POI 下不同業務所提供的不同服務,如:買單服務、外賣服務、傳統團購業務、預付業務、以及酒店預付業務等。

作爲美團搜索的平臺,我們的使命是把用戶流量進行高效的分發,並且在分發內容的基礎上儘量提升他們的搜索體驗。
在保持用戶黏性的同時,我們不但要提高用戶的交易效率,而且要爲他們的決策提供更多的信息幫助。
另一方面,對於商家而言,我們需要把更優質的用戶流量導向他們,從而帶來更高的轉化效率。這便是我們作爲美團入口的各項使命。
美團搜索的特點和挑戰
下面我們來討論一下 O2O 的搜索與其他網頁及電商的搜索,有什麼相同與相異之處,以及我們面臨着哪些挑戰。
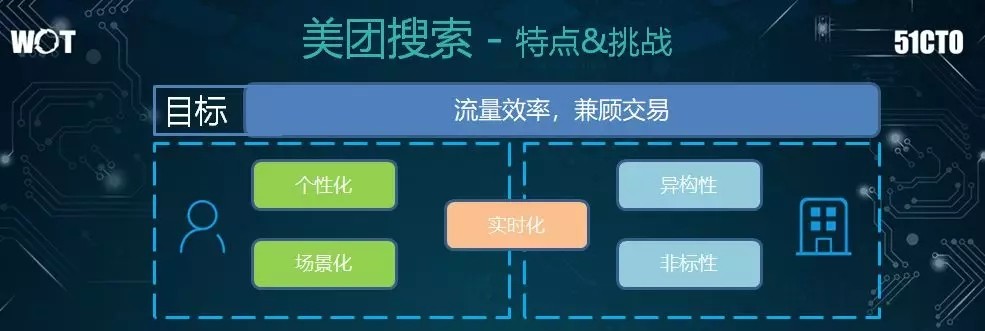
首先,就目標而言,我們的業務種類繁多,而且每種業務在不同的發展階段有着不同的優化目標:有的需要優化點擊率、有的需要優化轉化率、有的需要優化 GMV(Gross Merchandise Volume,成交總額)。
因此對於我們平臺而言,利用現有的大流量、服務好業務方、提高效率、加固平臺的交易,便是我們的整體大目標。
其次,對於用戶而言,他們需要根據不同的用戶屬性搜索到個性化的結果。另外,我們也需要根據搜索時的時間和空間等場景的不同,提供差別化的結果。
再次,對於商家而言:
異構性非常大。每個業務及其字段的關注點都有所不同。由於他們所提供的服務存在着差異性,因此其數據和檢索層面,也與傳統搜索存在着巨大的差異。
非標屬性。從平臺上的餐飲店鋪可以看到,商家的菜品本身就是一些非標準化的產品。這與電視和空調之類的標準品,有着本質上的區別。
可見,用戶與商家之間是通過實時性相關聯的。也就是說用戶的需求會隨着所處位置,以及早中晚餐的時間會有所不同。
而商家的運能也會隨着一天中的不同時段,以及是否下雨等天氣因素有所變化。因此,這些都被視爲美團搜索的特點和挑戰。

總結而言,我們搜索服務的願景便是:讓更多人更便捷地找到更多他們想要的生活服務。
其中“找到更多想要的”,可以通過智能匹配技術來實現;而“更便捷地找到”,則需要有個性化的排序。面對這兩條關鍵路徑,我們在深度學習方面進行了如下探索。
**美團搜索深度學習探索實踐
智能匹配**
一般說來,用戶的意圖表達分爲顯式和隱式兩種輸入類型:
顯式就是他直接通過篩選條件所傳遞的搜索要求。
隱式則包括用戶的搜索時間、地理位置和個人偏好。
因此,智能匹配就要求我們通過搜索結果,展現出用戶需要的集合。

那麼如何才能做好智能匹配呢?我們總結起來會涉及到如下兩個方面:
用戶意圖的匹配。
多維度的匹配。
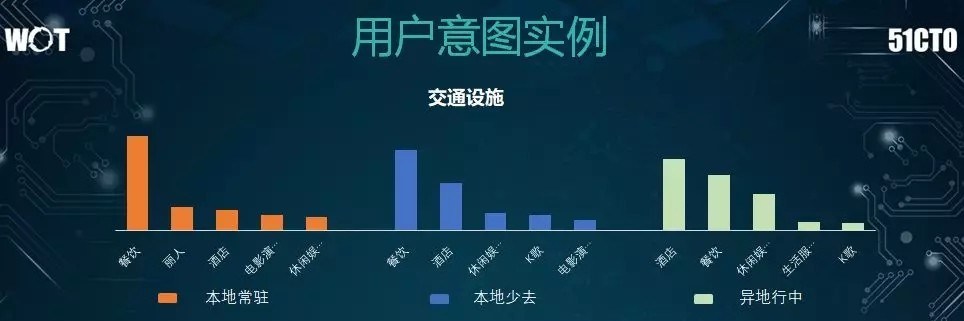
就用戶意圖而言,雖然搜索的是同一條詞彙,但是不同種類用戶的期望結果會有所不同。
例如:“北京南站”一詞:
對於北京本地常住的用戶來說,他們搜索的目的居多是出自餐飲外賣需求。
對於北京本地但少去的用戶來說,他們搜索的目的居多是出自公交換乘需求。
對於外地遊客來說,他們搜索的目的居多是出自火車與住宿需求。
因此,這就要求我們針對不同“背景”的用戶展現不一樣的內容。
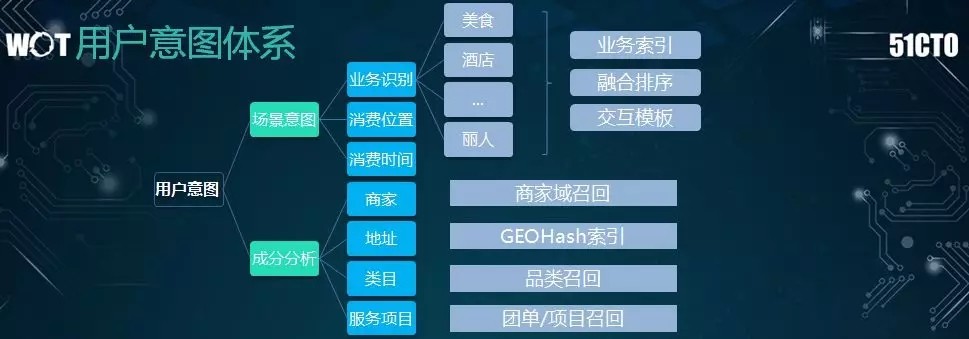
可見,用戶的意圖可以大致分爲兩個維度:
場景意圖,即基於用戶的隱式條件,我們要探究其需求是以美食爲主、酒店爲主、還是以旅遊爲主。這是業務級別上的需求。
成分分析,即針對用戶的顯式輸入,我們要分析其中間的有效成分,並籍此制定出有針對性的標準。
業務識別
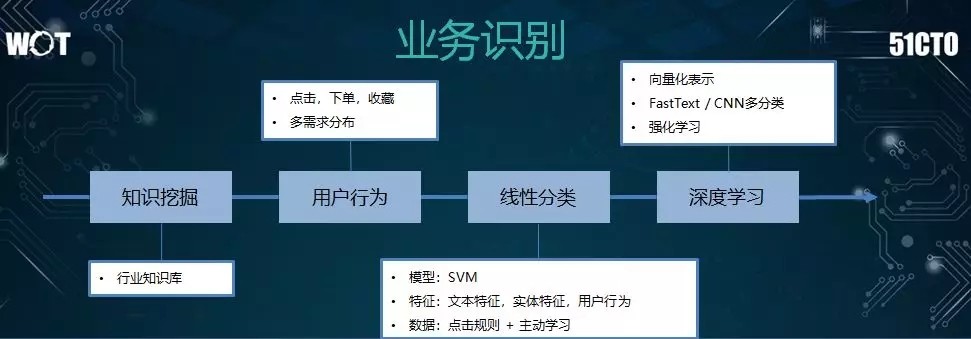
下面我來看看業務識別的基本流程。首先,我們要有一個行業知識庫,或稱爲詞表。
接着,我們挖掘出一些通用的詞彙,以保證每個詞都能對應某個需求,以及 Top 的相關問題。
在系統上線之後,我們通過迭代來匹配用戶的反饋,包括他們的點擊、下單、品類等業務分佈。然後,我們得出此類需求分佈的概率,並執行各種召回。
當然,這種簡單統計行爲的泛化能力是存在一些問題的。如果用戶的行爲特徵反饋並不充分的話,他們的需求也就不太明確。
此時我們自然而然地想到了使用各種機器學習模型,對文本和用戶行進行向量化,通過諸如 FastText 或 CNN 之類的分類模型,對用戶的各種特徵予以分類,從而得到用戶的意圖,並解決泛化的問題。
不過我們也曾經發現:通過機器學習所得到的分佈,雖然對整體而言是合理的,但是對於某些用戶卻並不合理。
因此,我們最近採用了一些強化學習的方法:在細微之處,我們探索性地爲用戶提供業務需求的入口,從而收集到用戶後續的反饋。
通過此類迭代,我們可以識別出用戶在某方面的業務需求是否強烈。
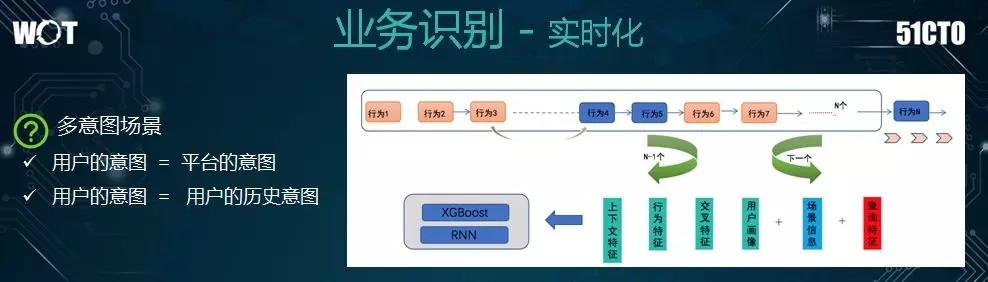
至此,我們是否可以認爲整體的業務已經識別清楚了呢?其實,我們不難發現:在用戶僅輸入單個詞語進行搜索的情況下,平臺基於大量用戶數據所統計出來的需求分佈,並不一定能夠準確地反映出用戶的意圖。
另外,用戶的歷史意圖是否會影響他的實時意圖呢?面對此類時序化的問題,我們需要基於此前他在我們系統中發生過的搜索行爲,採用大數據統計來提取相關特徵,利用 RNN 模型去預測他的下一個行爲。
當然,我們也會參照上述一些非業務方面的因素。
成分分析
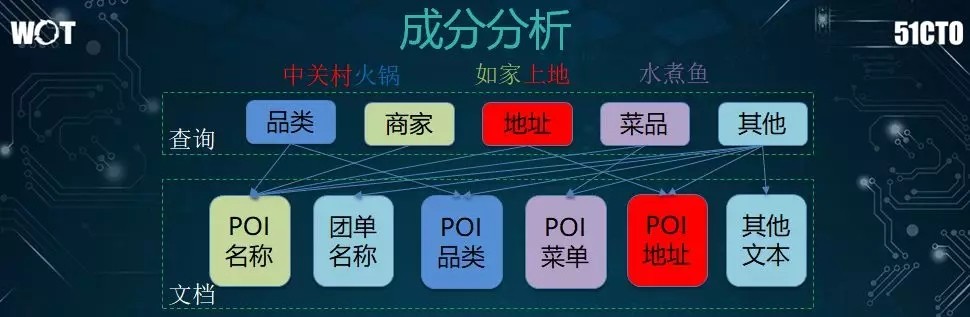
第二個方面是成分分析。考慮到用戶可能會搜索各種短語,如:“中關村火鍋”,其中,“中關村”是地址,“火鍋”是品類,那麼我們需要做好針對性的檢索。
例如:我們將地址信息轉化成地圖上的座標畫圈,將品類信息轉呈到已有成品類的檢索中,進而實現成分分析和智能匹配的完美結合。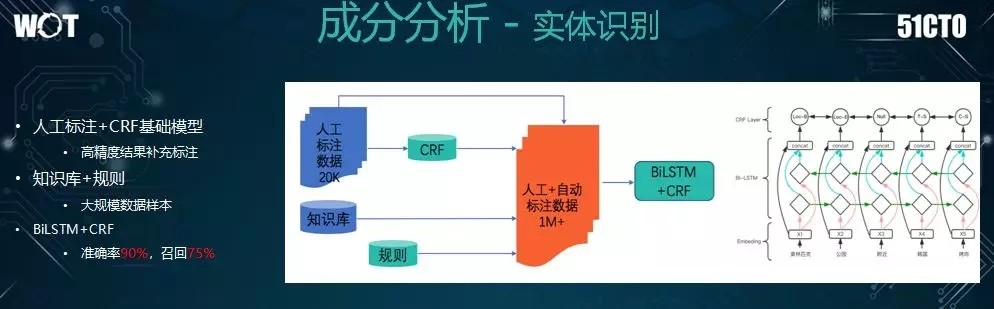
由於成分識別實際上是一個序列標註的問題,因此我們起初採用的是傳統的 CRF 模型。
雖然該模型的精度與召回尚可,但是它對於語義的理解,以及相關性的考慮是不夠的,而且它需要人工進行特徵提取與數據標註。因此,我們想到了使用基於 LS 的深度學習與 CRF 結合的方法。
初期,由於數據量太小,算法不能很好地學習到各種標籤的正確性,因此效果不如 CRF。
於是,我們採用瞭如下的方法來擴充數據量:
我們將已訓練的 CRF 模型擴展出更多的語料,使之將預測出來的結果作爲標誌數據。
對於已總結的數據庫,我們根據用戶反饋的規則,挖掘出更多的數據。
通過各種擴充,待樣本增長了百萬級的規模時,我們再運用深度學習模型進行實體識別。
在實體識別的過程中,我們所用到的輸入特徵包括:值向量特徵,以及以前 CRF 所用到的人工特徵,通過 BiLSTM 再進行 CIF,最後達到了實體識別。而由此所產生的效果相對於 CRF,已經有了大幅的提升。
當然根據業務屬性,由於商家的名稱以及微信地址都是五花八門的,因此我們無法做到及時的全面覆蓋,召回也就不那麼的理想。
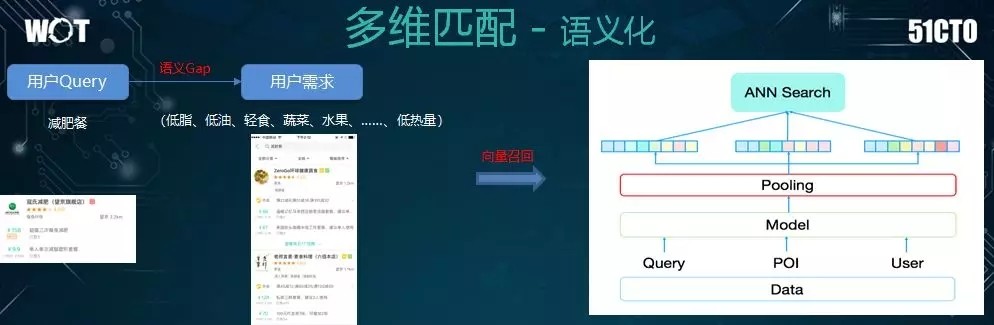
前面提到的是用戶意圖在智能匹配上的作用。下面我們來看爲何要進行多維匹配。
例如:某個用戶輸入了“減肥餐”,那麼我們僅僅使用文本匹配予以返回顯然是不夠的。
他的潛在需求,可能還包括:低油、低脂、輕食、蔬菜、水果等一系列方面。因此,這就產生了需求之間的語義 Gap。
爲了彌補該 Gap,我們需要建立向量化的召回框架結構,由上方的示意圖可見,我們將文本數據和用戶行爲序列數據,導入語義模型,處理完畢後得到了 Query、POI、User 三者的向量,再根據這些向量執行召回。
如今,該框架已經能夠被在線使用到了。
語義模型
下面我們來介紹一下美團在語義模型方面的具體嘗試。
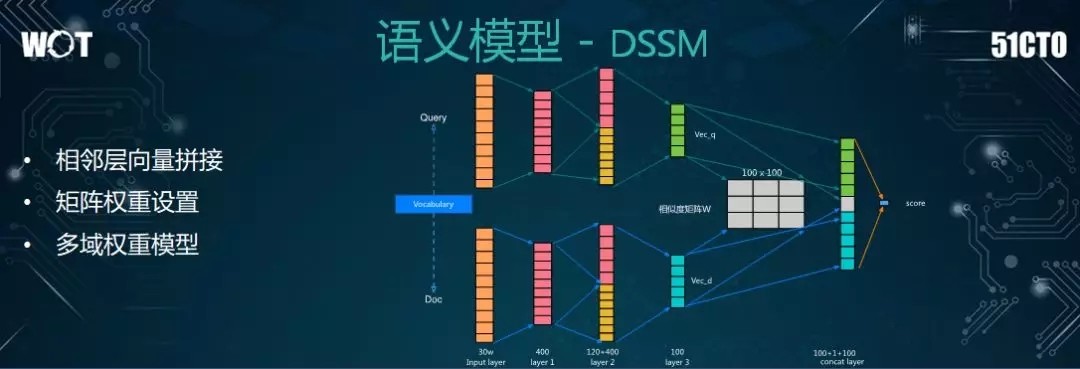
首先是 DSSM 模型。我們在其原生模型的基礎上進行了一些修改。在輸入方面,我們採用的是文檔(Doc)和查詢(Query)的雙塔結構。此處,我們已經做好了文本的過濾(包括低頻次的過濾)。
通常情況下,系統會經過兩個隱藏層。而在此處,我們改進爲:讓第二層將第一層向量選出來的隱性層轉到第三層,以便數據能夠更好地向下傳遞。
而在輸出層,我們會更細膩地考慮兩者之間的權重。我們會做一個相似度的矩陣,同時將這兩個向量傳遞到最後的輸出層,以線性加權的方式得到最終的分數,這便是我們在 DSSM 語義模型上的探索。

前面我們討論了監督的模型,其實我們也嘗試了一些非監督的模型。非監督模型主要是基於用戶的行爲序列。
例如:用戶會在某個查詢會話中會點擊多處(POI1、POI2),那麼我們就將此序列當成一個文檔。
相比前面提及的主要體現在文本上的模型,此處則更偏向於推薦的思想。如果用戶既點了 A,又點了 B,那麼兩者之間就存在相似性,因此我們採用了單獨的模型來訓練此類序列。
而且,我們在輸入層不只是把 POI 進行了向量化,還將與 POI 相關的品類信息、GU 哈希信息等都拼接成額外的向量。這便是我們所做的簡單的改動。
上圖右側是一個向量的展現,可見系統能夠把一些相關的信息學習出來,以便我們進行各種相關性的召回。
針對上述智能匹配技術,我們總結起來有兩個方面:
怎麼做好用戶的意圖識別。
怎麼實現多維度匹配,即:在傳統文本匹配的基礎上,加入了向量化召回的思路。
個性化排序
在完成了用戶匹配之後,我們幫用戶搜到大量的匹配結果。那麼,我們勢必需要通過個性化排序,來優先顯示用戶最需要的結果信息。
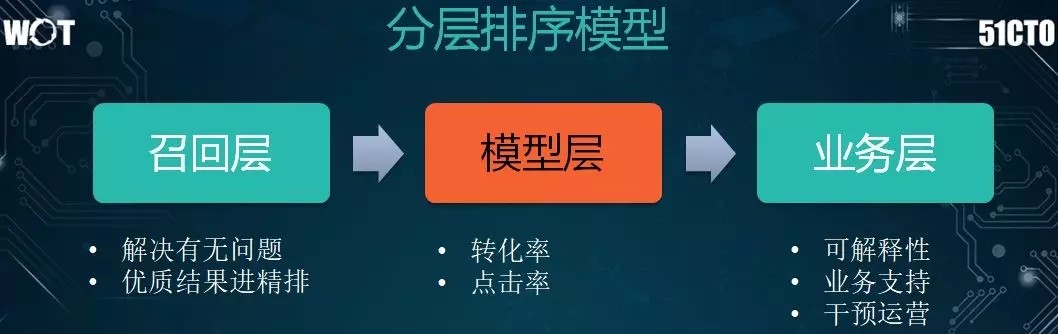
如上圖所示,排序的整體流程爲:
我們使用召回層進行簡單的粗排,它適用於一些簡單的特徵,即通過線性模型對結果進行初步過濾。
把少量的結果送到模型層,執行點擊率和轉化率的預估。
在業務層會有一些可解釋性、業務規則的排序。

其中,模型層的演進過程是:線性模型→決策樹模型(如 GBDT)→PairWise 模型→實時模型→深度學習,以滿足個性化的特徵。
下面,我們來重點討論實時模型和深度學習的實現方式。
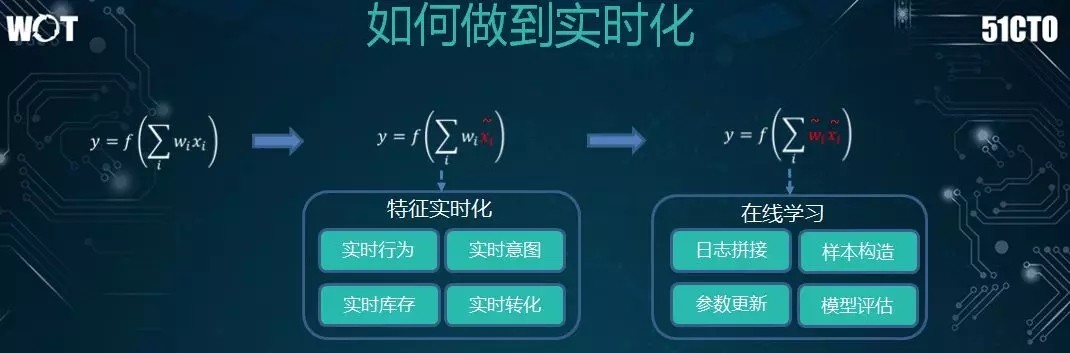
爲了更好地滿足用戶的需求。我們有兩種實時化的方向:
許多公司會將包括實時行爲、實時庫存、實時轉化等在內的特徵放入模型,以進行實時更新。
通過在線學習,拼接各種實時流,實時更新參數,根據模型的評估,判斷是否要替換成新訓練的模型。
實時特徵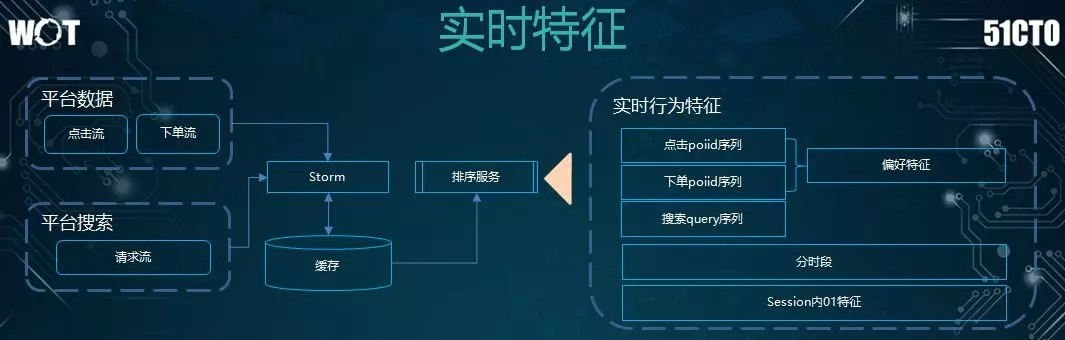
同時,在提取實時特徵的過程中,我們需要將用戶實時的數據,如:點擊流、下單流等請求數據緩存到 Storm 裏。
接着,基於這些數據,我們需要提取到用戶的實時行爲特徵,包括:品類偏好、價格偏好、距離偏好等。
另外,我們會對序列區分不同的時段,並逐一“兌換”特徵,當然,我們也會考慮該用戶會話(Session)內部的 01 特徵。結合業務特點的挖掘,我們最終把實時特徵提取了出來。
深度模型
對於美團而言,深度模型的需求源自如下三個方面:
場景非常複雜,每個業務的需求都存在着巨大差異。
前面提到的樹模型雖然有較好的泛化能力,但是缺少針對用戶行爲的記憶能力。
需要對一些稀疏特徵,以及特徵組合進行處理。
因此,基於業務和工程師的實際需求,我們有必要採用深度學習模型。
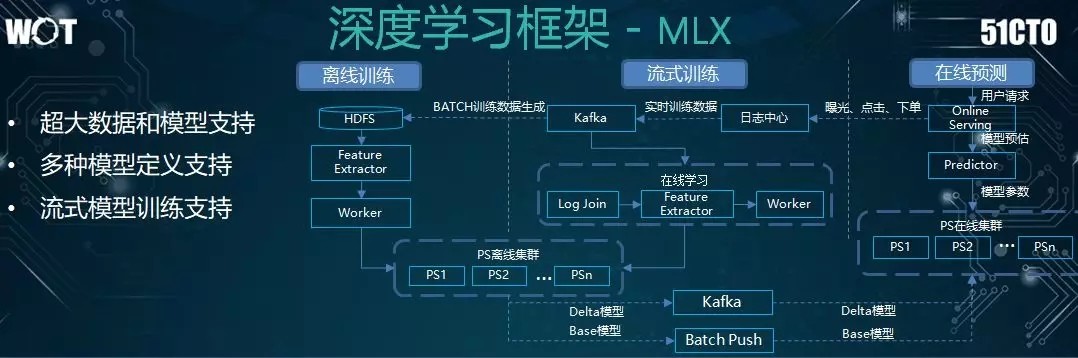
上圖是我們的深度學習框架。其特點在於如下三個方面:
能夠更好地在線支持超大規模的數據和模型,如:幾十個 G 的模型。
能夠方便地支持多種模型的定義。
能夠很好地支持流式模式的訓練與上線。
簡單來看,該模型也分爲三個部分:
離線訓練,即Base模型,是從日誌數據表裏提取特徵,通過訓練,將參數存到離線集羣之中。
流式訓練,將實時收集到的數據作爲日誌予以拼接,通過特徵的提取,最後執行訓練。
在線預測,通過實時優先級對模型進行評估。如果通過,則更新到 PS 在線集羣裏進行預測。
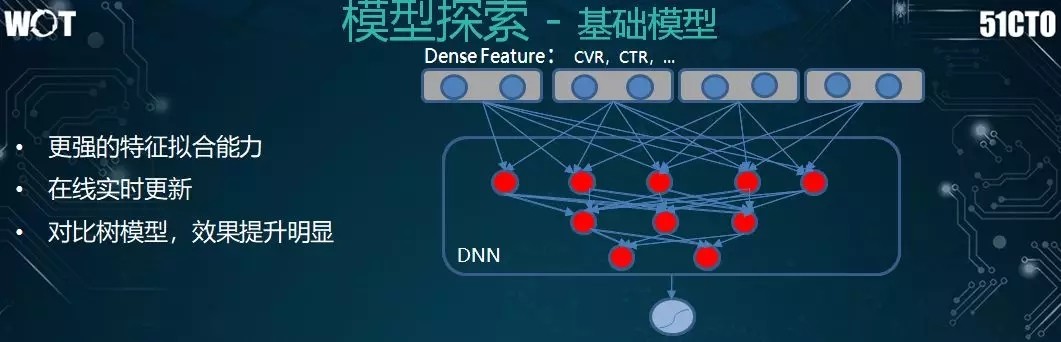
有了上述框架的感念,我們再來看看在該深度模型上的探索路徑。起初,我們直接將 Dense 特徵拿過來,扔到簡單的 MLP 裏執行快速迭代。
憑藉着更強的特徵擬合能力,我們能夠實時地迭代出參數的模型,進而實現了在線式的實時更新。因此,相比之前的樹模型,深度學習模型的效果有了明顯的提升。
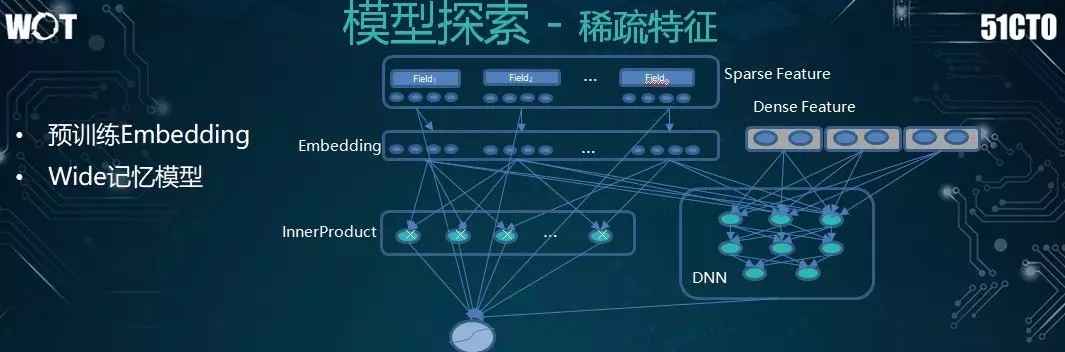
而針對稀疏特徵,我們採用瞭如下兩種方法:
直接用模型去學習和訓練 Embedding 特徵,進而輸入到模型之中。
通過 Wide 記錄模型來實現深度學習。
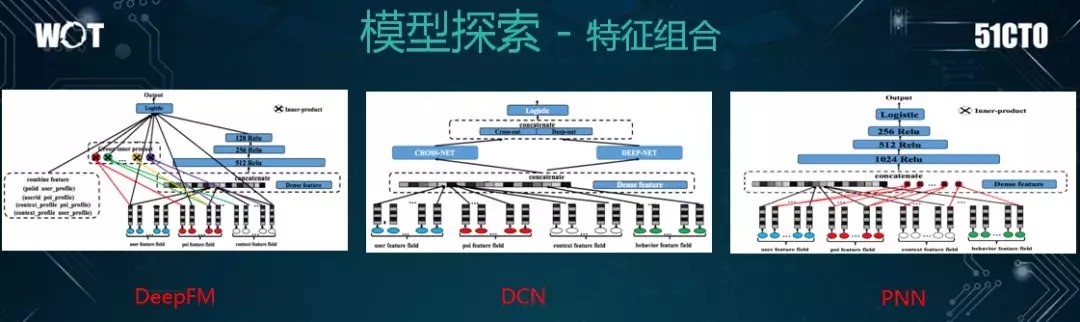
如上圖所示,在特徵組合方面,我們嘗試了一些知名的模型。其實它們之間並無明顯的優劣勢,就看哪個更適合業務項目罷了。
例如:PNN 是將特徵作爲一個組合放在了輸入層;DeepFM 則多了一個 FM 值;而 DCN 是做到了特徵高階的模型。
因此,我們在不同的業務場景中,都嘗試了上述這些模型。一旦發現效果較好,我們就會將其替換成當前業務的主模型。

總的說來,我們現在的主體模型是:流式的深度學習模型。從上圖的各項指標可以看出,其整體效果都有了正向的提升。
未來展望
展望未來,我們會在如下兩大方面繼續個性化排序的探索:
智能匹配。在深度上,我們會深耕成分分析、用戶意圖、以及業務預測等方面。
在廣度上,我們會針對文本匹配效果不佳的場景,補充一些向量召回,進而實現根據用戶的不同屬性,達到多維度個性化召回的效果。
排序模型。類似於阿里的 DIEN 模型,我們會對用戶的興趣進行單獨建模,進而與我們的排序模型相組合。
考慮到各種品類的相關性、文本的相關性、以及實際業務場景的不確定性,我們將在深度學習中嘗試多目標的聯合優化。