




Pandas是一個開源Python庫,它在Python編程中提供數據分析和操作。
它是數據表示,過濾和統計編程中非常有前途的庫。Pandas中最重要的部分是DataFrame,您可以在其中存儲和播放數據。
在本教程中,您將瞭解DataFrame是什麼,如何從不同的源創建它,如何將其導出到不同的輸出,以及如何操作其數據。
安裝熊貓
您可以使用pip在Python中安裝Pandas 。在cmd中運行以下命令:
pip install pandas

此外,您可以使用conda安裝Pandas,如下所示:
conda install pandas
閱讀Excel文件
您可以使用read_excel() Pandas中的方法從Excel文件中讀取 。爲此,您需要再導入一個名爲xlrd的模塊。
使用pip安裝xlrd:
pip install xlrd
下面的示例演示瞭如何從Excel工作表中讀取:
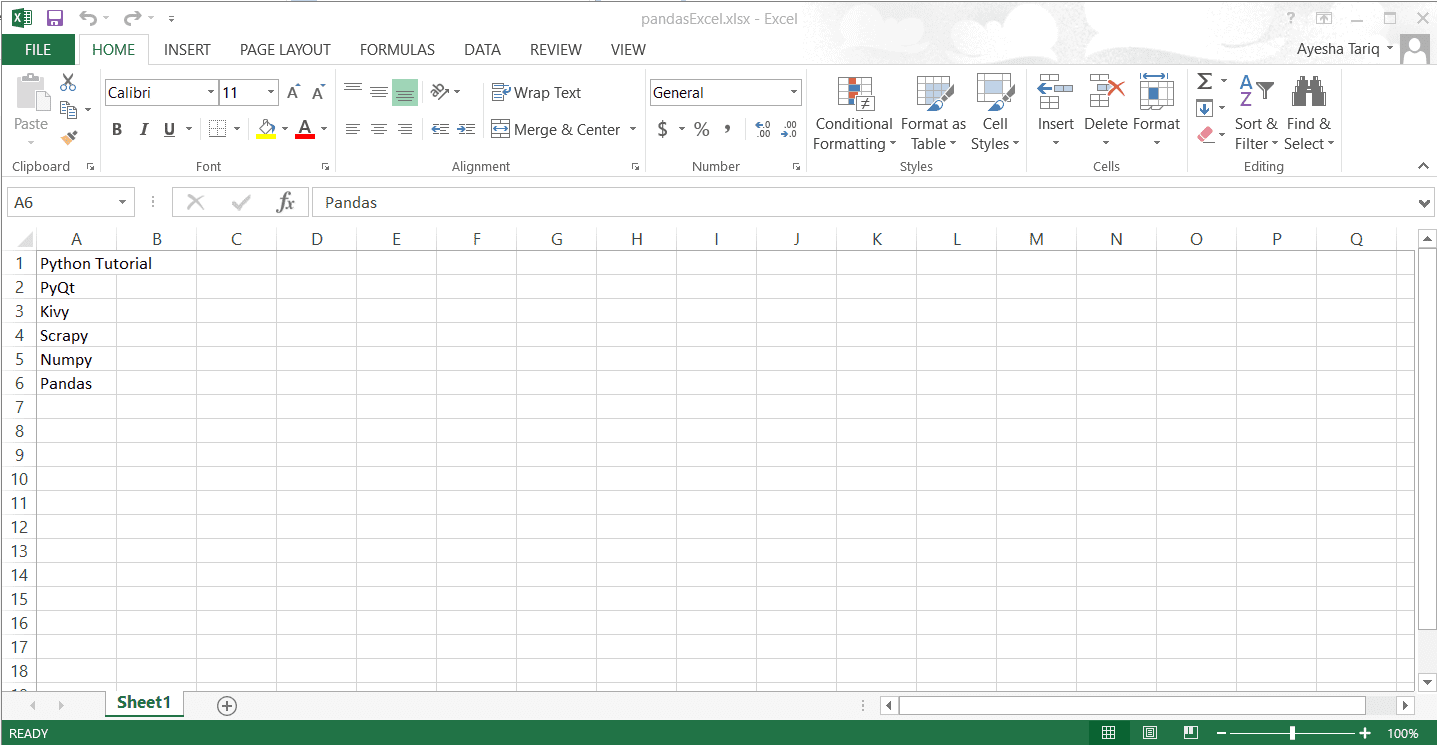
我們創建了一個包含以下內容的Excel工作表:
![3-Excel-sheet.png]()
導入Pandas模塊:
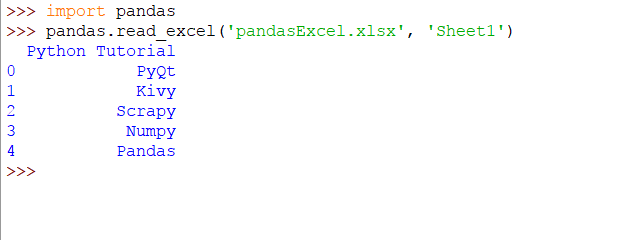
import pandas
上面的代碼片段將生成以下輸出:
如果使用type關鍵字檢查輸出的類型,它將爲您提供以下結果:
< 類 'pandas.core.frame.DataFrame' >
這稱爲DataFrame!這是我們將在本教程中處理的Pandas的基本單元。
DataFrame是一個帶標籤的二維結構,我們可以存儲不同類型的數據。DataFrame類似於SQL表或Excel電子表格。
導入CSV文件
要從CSV文件中讀取,您可以使用read_csv() Pandas 的 方法。
導入pandas模塊: import pandas
現在調用 read_csv() 方法如下:
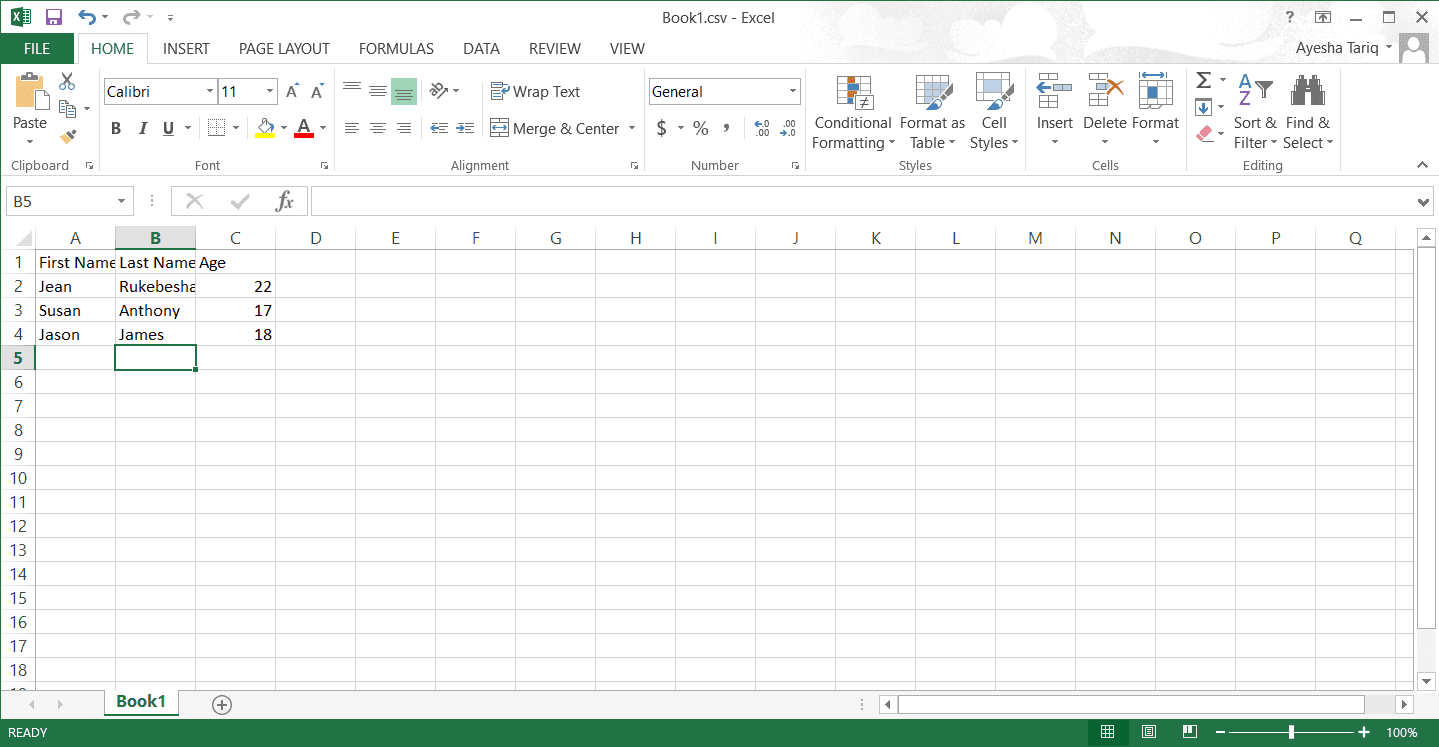
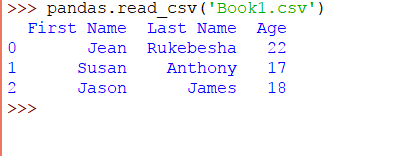
Book1.csv具有以下內容:
該代碼將生成以下DataFrame:
閱讀文本文件
我們也可以使用read_csv Pandas 的 方法從文本文件中讀取; 考慮以下示例:
進口 大熊貓
大熊貓。read_csv('myFile.txt')
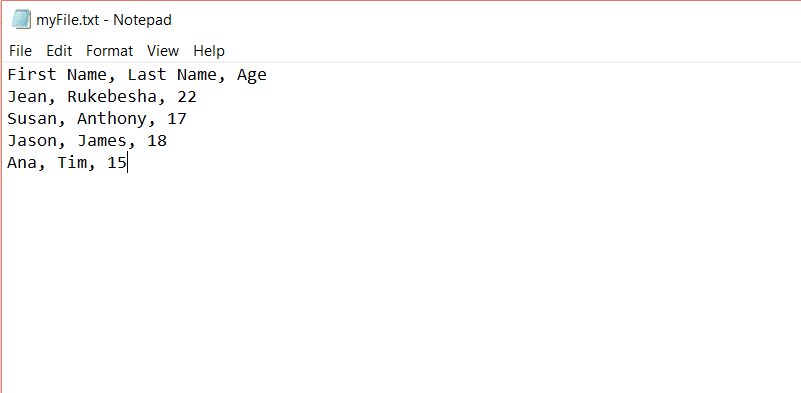
myFile.txt如下所示:
上面代碼的輸出將是:
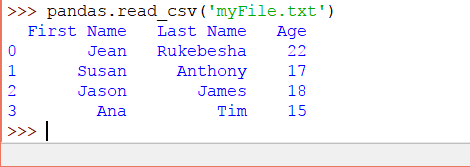
此文本文件被視爲CSV文件,因爲我們使用逗號分隔的元素。該文件還可以使用其他分隔符,例如分號,製表符等。
假設我們有一個製表符分隔符,文件如下所示:
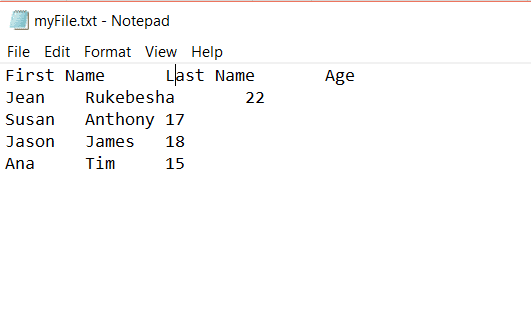
當分隔符是製表符時,我們將得到以下輸出:
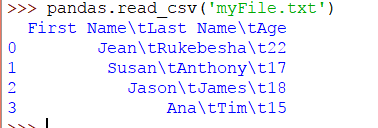
由於Pandas不知道分隔符,因此它將選項卡轉換爲\t。
要將製表符定義爲分隔符,請傳遞分隔符參數,如下所示:
大熊貓。read_csv('myFile.txt',delimiter = '\ t')
現在輸出將是:
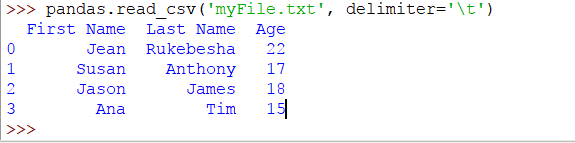
現在看起來正確。
閱讀SQL
您可以使用read_sql() Pandas 的 方法從SQL數據庫中讀取。這在以下示例中進行了演示:
import sqlite3
進口 大熊貓
con = sqlite3。connect('mydatabase.db')
大熊貓。read_sql('select * from Employee',con)
在此示例中,我們連接到一個SQLite3數據庫,該數據庫具有名爲“Employee”的表。使用read_sql() Pandas 的 方法,然後我們將查詢和連接對象傳遞給該 read_sql() 方法。查詢將獲取表中的所有數據。
我們的Employee表如下所示:
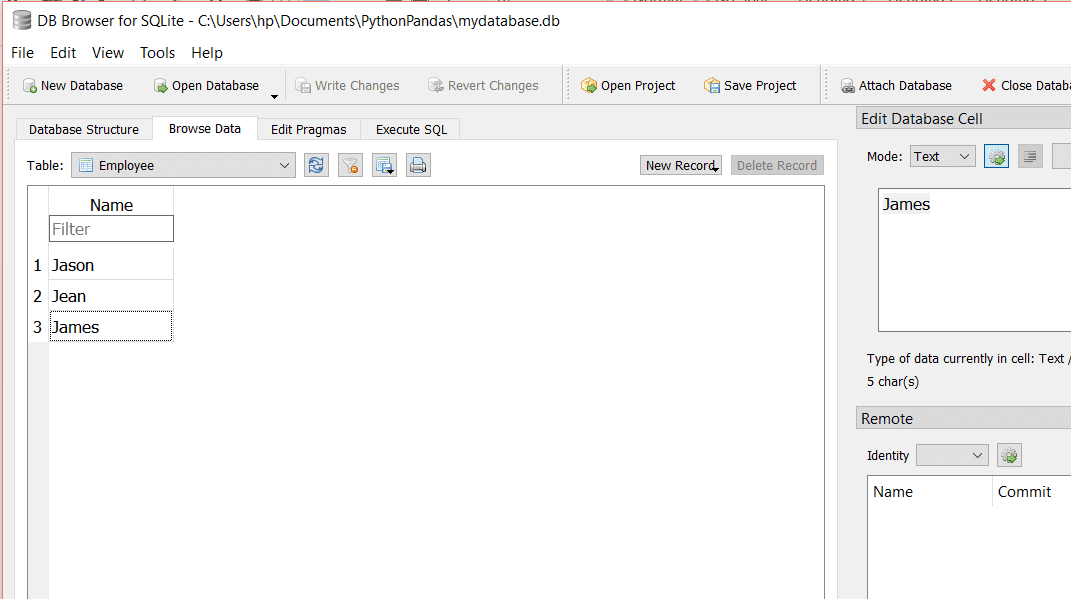
運行上面的代碼時,輸出將如下所示:

選擇列
假設我們在Employee表中有三列,如下所示:
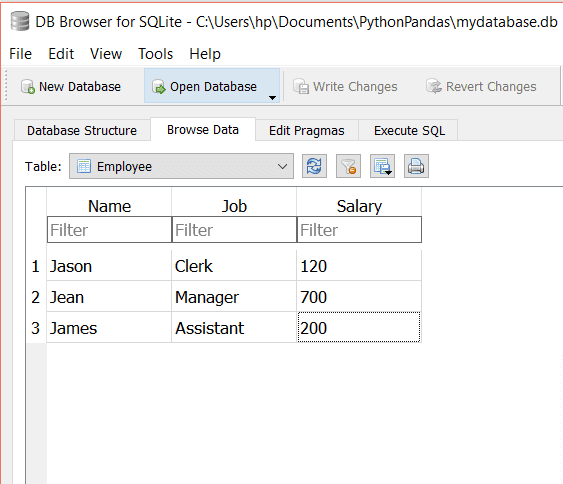
要從表中選擇列,我們將傳遞以下查詢:
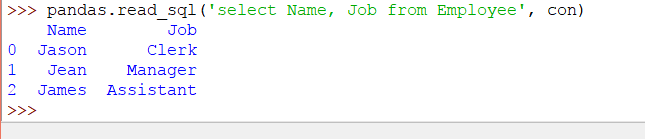
從員工中選擇姓名,工作
Pandas代碼聲明如下:
大熊貓。read_sql('select Name,Job from Employee',con)
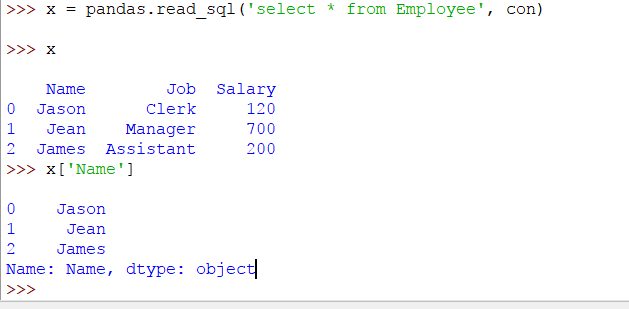
我們還可以通過訪問DataFrame從表中選擇一列。請考慮以下示例:
x = 熊貓。read_sql('select * from Employee',con)
x [ '姓名' ]
結果如下:
按值選擇行
首先,我們將創建一個DataFrame,我們將從中選擇行。
要創建DataFrame,請考慮以下代碼:
進口 大熊貓
frame_data = { '名':'詹姆斯','賈森','羅傑斯' ],'年齡':18,20,22 ],'工作':'助理','經理','職員' ] }df = 熊貓。DataFrame(frame_data)
在這段代碼中,我們使用DataFrame() Pandas 的方法創建了一個包含三列和三行的DataFrame 。結果如下:

要基於值選擇行,請運行以下語句:
df。loc [ df [ 'name' ] == 'Jason' ]
df.loc[] 或者 DataFrame.loc[] 是一個布爾數組,可用於按值或標籤訪問行或列。在上面的代碼中,將獲取行,其中名稱等於Jason。
輸出將是:

選擇按索引排序
要通過索引選擇行,我們可以使用slicing(:)運算符或 df.loc[] 數組。
請考慮以下代碼:
>> > frame_data = { '名':'詹姆斯','賈森','羅傑斯' ],'年齡':18,20,22 ],'工作':'助理','經理','職員' ]}>> > DF = 大熊貓。DataFrame(frame_data)
我們創建了一個DataFrame。現在讓我們使用df.loc[]以下方法訪問一行:
>>> df.loc[1]
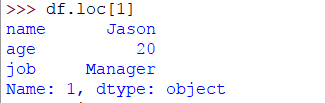
如您所見,獲取了一行。我們可以使用切片運算符執行相同的操作,如下所示:
>>> df[1:2]
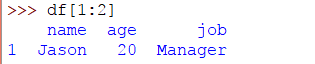
更改列類型
可以使用astype() DataFrame 的屬性更改列的數據類型 。要檢查列的數據類型,我們使用dtypes DataFrame 的 屬性。
>>> df.dtypes
輸出將是:

現在將數據類型從一個轉換爲另一個:
>> > DF。name = df。名字。astype(str)
我們從DataFrame中獲取了列'name',並將其數據類型從object更改爲string。
將函數應用於列/行
要在列或行上應用函數,可以使用apply() DataFrame 的 方法。
請考慮以下示例:
>> > frame_data = { 'A':[ 1,2,3 ],'B':[ 18,20,22 ],'C':[ 54,12,13 ]}>> > DF = 大熊貓。DataFrame(frame_data)
我們創建了一個DataFrame,並在行中添加了整數類型的值。要在值上應用函數(例如平方根),我們將導入NumPy模塊以使用sqrt 它中的 函數,如下所示:
>> > 進口 numpy的 爲 NP
>> > DF。申請(NP。開方)
輸出如下:
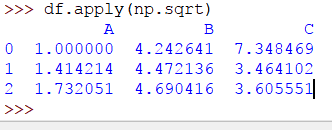
要應用該 sum 功能,代碼將是:
>>> df.apply(np.sum)

要將函數應用於特定列,可以像這樣指定列:
>>>df['A'].apply(np.sqrt)
排序值/按列排序
要對DataFrame中的值進行排序,請使用DataFrame的 sort_values() 方法。
使用整數值創建DataFrame:
>> > frame_data = { 'A':[ 23,12,30 ],'B':[ 18,20,22 ],'C':[ 54,112,13 ]}>> > DF = 大熊貓。DataFrame(frame_data)
現在要對值進行排序:
>> > DF。sort_values(by = [ 'A' ])
輸出將是:
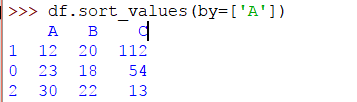
該 sort_values() 方法具有必要的屬性“by”。在上面的代碼中,值按列A排序。要按多列排序,代碼將是:
>> > DF。sort_values(by = [ 'A','B' ])
如果要按降序排序,請將升序屬性設置 set_values 爲False,如下所示:
>> > DF。sort_values(by = [ 'A' ],ascending = False)
輸出將是:

刪除/刪除重複項
要從DataFrame中刪除重複行,請使用DataFrame的 drop_duplicates() 方法。
請考慮以下示例:
>> > frame_data = { '名':'詹姆斯','賈森','羅傑斯','傑森' ],'年齡':18,20,22,20 ],'工作':'助理','經理','職員','經理' ]}>> > DF = 大熊貓。DataFrame(frame_data)
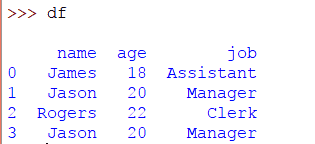
在這裏,我們創建了一個具有重複行的DataFrame。要檢查DataFrame中是否存在任何重複行,請使用DataFrame的 duplicated() 方法。
結果將是:

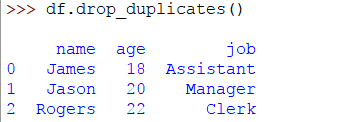
可以看出最後一行是重複的。要刪除或刪除此行,請運行以下代碼行:
>> > DF。drop_duplicates()
現在的結果將是:
![28-Remove-duplicates.png]() 按列刪除重複項
按列刪除重複項
有時,我們有數據列的值相同,我們希望刪除它們。我們可以通過傳遞我們需要刪除的列的名稱來逐行刪除。
例如,我們有以下DataFrame:
>> > frame_data = { '名':'詹姆斯','賈森','羅傑斯','傑森' ],'年齡':18,20,22,21 ],'工作':'助理','經理','職員','員工' ]}>> > DF = 大熊貓。DataFrame(frame_data)

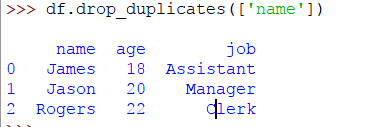
在這裏你可以看到Jason是兩次。如果要按列刪除重複項,只需傳遞列名稱,如下所示:
>> > DF。drop_duplicates([ 'name' ])
結果如下:
刪除列
要刪除整個列或行,我們可以drop() 通過指定列或行的名稱來使用DataFrame 的 方法。
請考慮以下示例:
>> > DF。drop([ 'job' ],axis = 1)
在這行代碼中,我們將刪除名爲“job”的列。這裏需要axis參數。如果軸值爲1,則表示我們要刪除列,如果軸值爲0,則表示將刪除該行。在軸值中,0表示索引,1表示列。
結果將是:

刪除行
我們可以使用該 drop() 方法通過傳遞行的索引來刪除或刪除行。
假設我們有以下DataFrame:
>> > frame_data = { '名':'詹姆斯','賈森','羅傑斯' ],'年齡':18,20,22 ],'工作':'助理','經理','職員' ]}>> > DF = 大熊貓。DataFrame(frame_data)
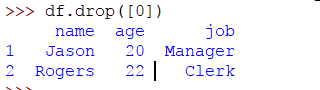
要刪除索引爲0的行,其中名稱爲James,age爲18且作業爲Assistant,請使用以下代碼:
>>> df.drop([0])
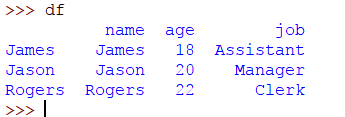
讓我們創建一個DataFrame,索引是名稱:
>> > frame_data = { '名':'詹姆斯','賈森','羅傑斯' ],'年齡':18,20,22 ],'工作':'助理','經理','職員' ]}>> > DF = 大熊貓。DataFrame(frame_data,index = [ 'James','Jason','Rogers' ])
現在我們可以刪除具有特定值的行。例如,如果我們要刪除名稱爲Rogers的行,則代碼將爲:
>>> df.drop(['Rogers'])
輸出將是:
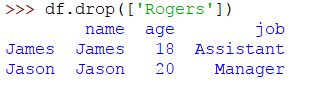
您還可以刪除一系列行:
>>> df.drop(df.index[[0, 1]])
這將刪除從索引0到1的行以及僅剩下一行,因爲我們的DataFrame由3行組成:

如果要從DataFrame中刪除最後一行並且不知道總行數是多少,那麼可以使用負索引,如下所示:
-1刪除最後一行。同樣-2將刪除最後2行,依此類推。
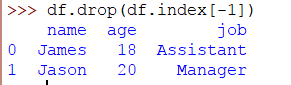
總結一列
您可以使用sum() DataFrame 的 方法對列項進行求和。
假設我們有以下DataFrame:
>> > frame_data = { 'A':[ 23,12,12 ],'B':[ 18,18,22 ],'C':[ 13,112,13 ]}>> > DF = 大熊貓。DataFrame(frame_data)
現在總結A列的項目,使用以下代碼行:
>>> df['A'].sum()
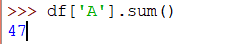
您還可以使用apply() DataFrame 的 方法並傳入NumPy的sum方法來對值進行求和。
計算唯一值
要計算列中的唯一值,可以使用nunique() DataFrame 的 方法。
假設我們有如下的DataFrame:
>> > frame_data = { 'A':[ 23,12,12 ],'B':[ 18,18,22 ],'C':[ 13,112,13 ]}>> > DF = 大熊貓。DataFrame(frame_data)
要計算A列中的唯一值:
>>> df['A'].nunique()

如您所見,A列只有2個唯一值23和12,另外12個是重複,這就是爲什麼我們在輸出中有2個。
如果要計算列中的所有值,可以使用以下 count() 方法:
>>> df['A'].count()
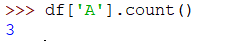
子集行
要選擇DataFrame的子集,可以使用方括號。
例如,我們有一個包含一些整數的DataFrame。我們可以像這樣選擇或分配一行:
df.[start:count]
起點將包含在子集中,但不包括停止點。例如,要從第一行開始選擇3行,您將編寫:
>>> df[0:3]
輸出將是:
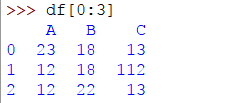
該代碼表示從第一行開始,該行爲0並選擇3行。
同樣,要選擇前兩行,您將編寫:
>>> df[0:2]
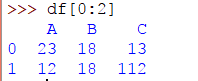
要選擇或子集最後一行,請使用否定索引:
>>> df[-1:]
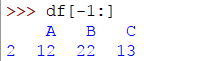
寫入Excel
要將DataFrame寫入Excel工作表,我們可以使用該 to_excel() 方法。
要寫入Excel工作表,您必須打開工作表並打開Excel工作表,我們必須導入openpyxl模塊。
使用pip安裝openpyxl:
pip install openpyxl
請考慮以下示例:
>> > 進口 openpyxl
>> > frame_data = { '名':'詹姆斯','賈森','羅傑斯' ],'年齡':18,20,22 ],'工作':'助理','經理','職員' ]}>> > DF = 大熊貓。DataFrame(frame_data)
>> > DF。to_excel(“pandasExcel.xlsx”,“Sheet1”)
Excel文件如下所示:
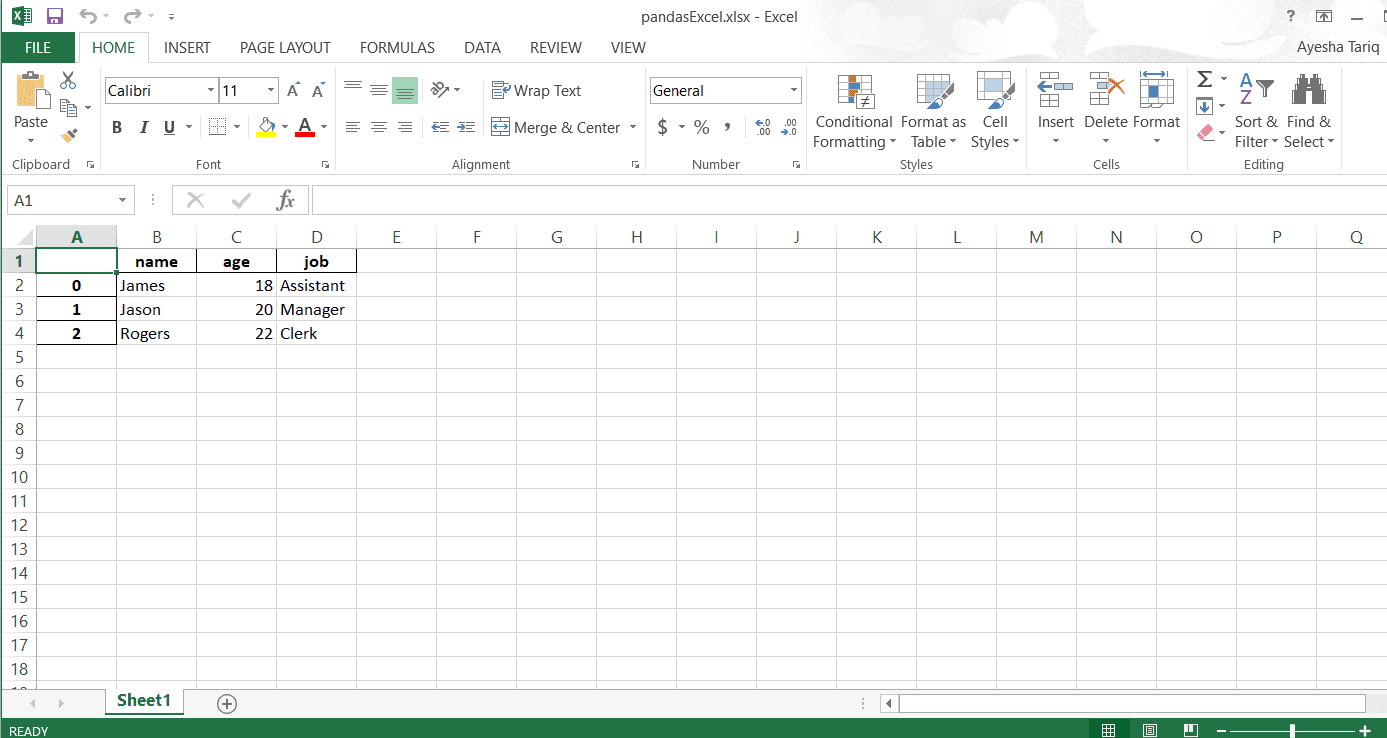
寫入CSV
同樣,要將DataFrame寫入CSV,您可以使用to_csv() 以下代碼行中的 方法:
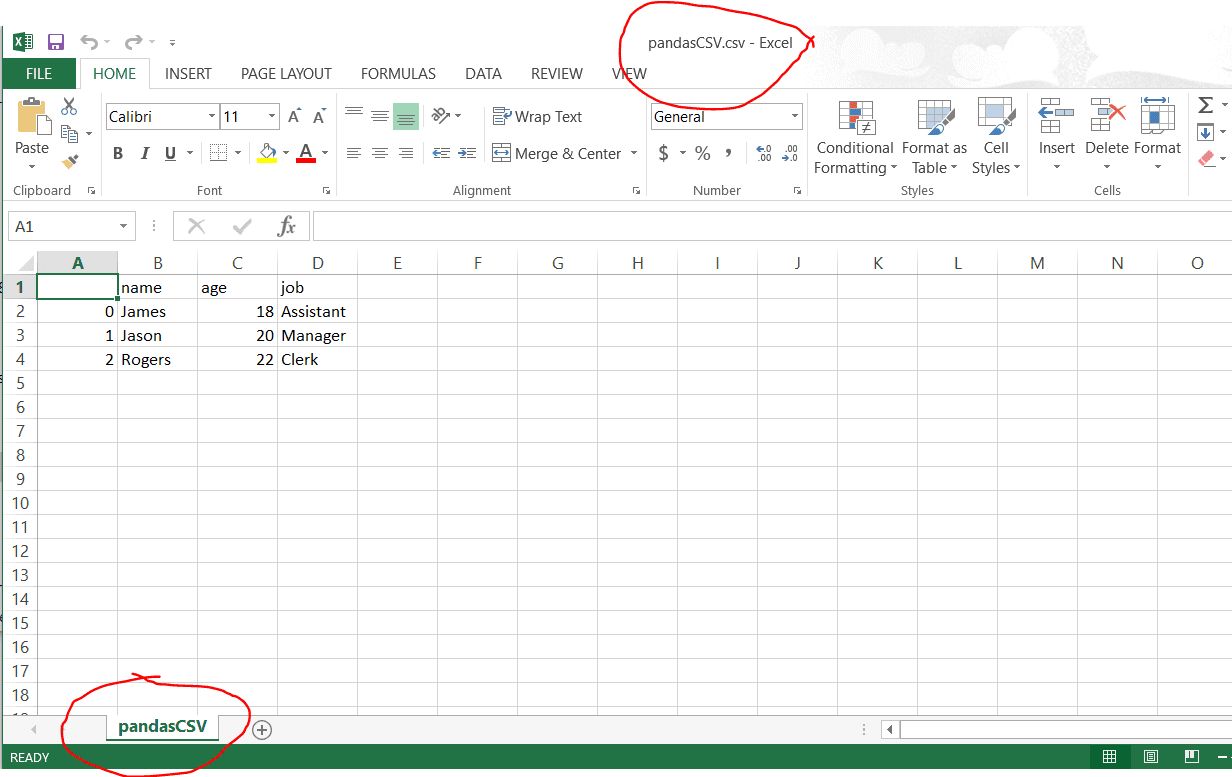
>>> df.to_csv("pandasCSV.csv")
輸出文件如下所示:
寫入SQL
要將數據寫入SQL,我們可以使用該 to_sql() 方法。
請考慮以下示例:
import sqlite3
進口 大熊貓
con = sqlite3。connect('mydatabase.db')
frame_data = { '名':'詹姆斯','賈森','羅傑斯' ],'年齡':18,20,22 ],'工作':'助理','經理','職員' ] }df = 熊貓。DataFrame(frame_data)
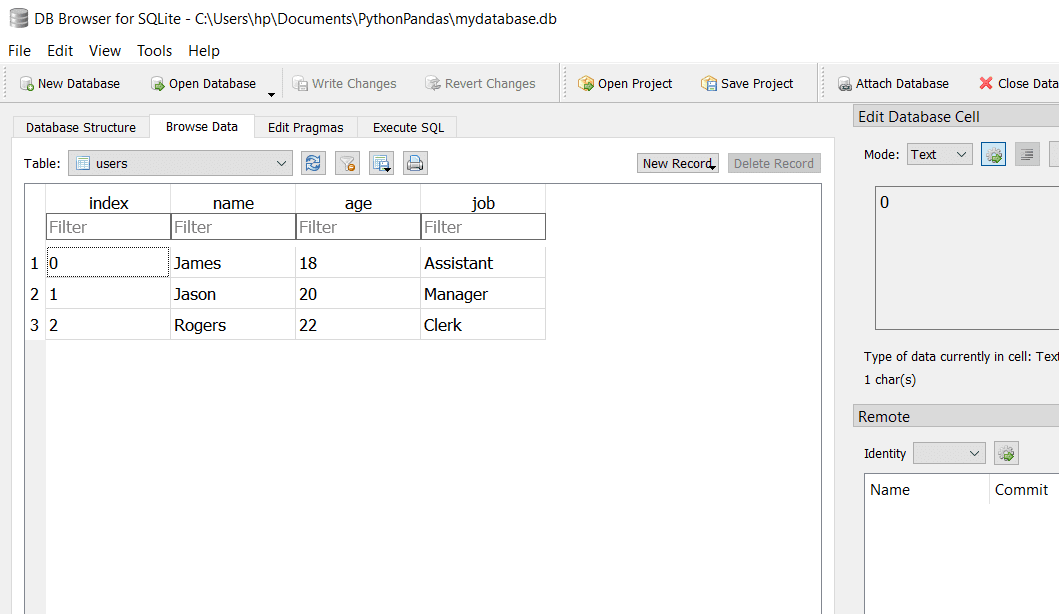
df。to_sql('users',con)
在此代碼中,我們創建了與SQLite3數據庫的連接。然後我們創建了一個包含三行三列的DataFrame。
最後,我們使用to_sql 了DataFrame(df)的 方法,並傳遞了數據將與連接對象一起存儲的表的名稱。
SQL數據庫將如下所示:
寫信給JSON
您可以使用to_json() DataFrame 的 方法寫入JSON文件。
這在以下示例中進行了演示:
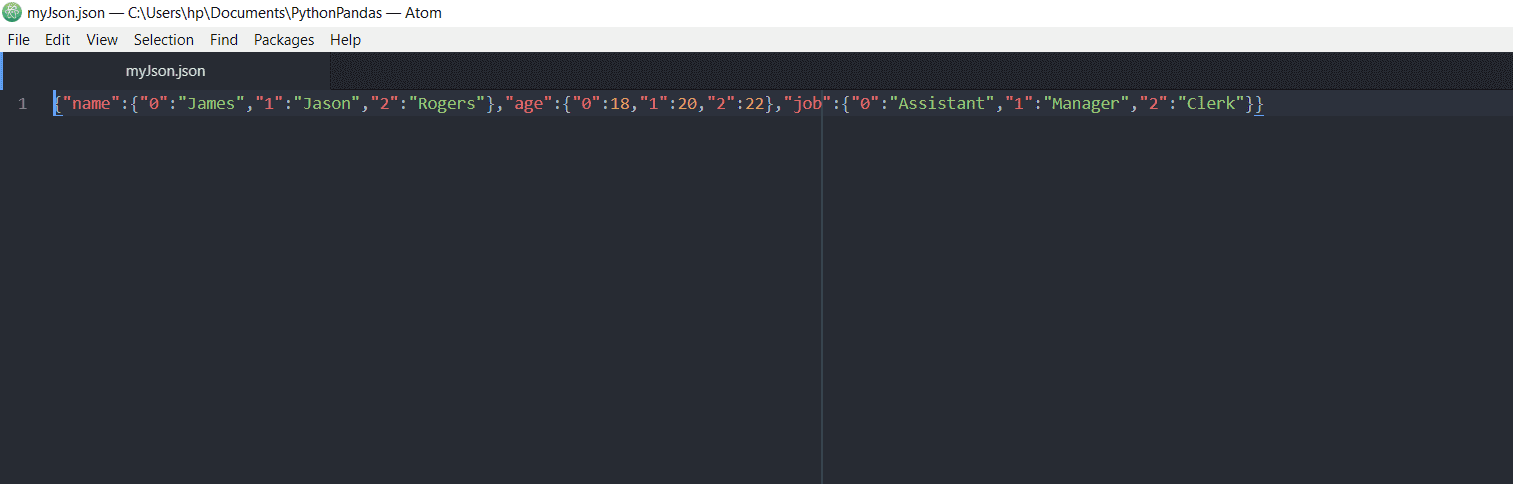
>>> df.to_json("myJson.json")
在這行代碼中,JSON文件的名稱作爲參數傳遞。DataFrame將存儲在JSON文件中。該文件將包含以下內容:
寫入HTML文件
您可以使用to_html() DataFrame 的 方法創建包含DataFrame內容的HTML文件。
請考慮以下示例:
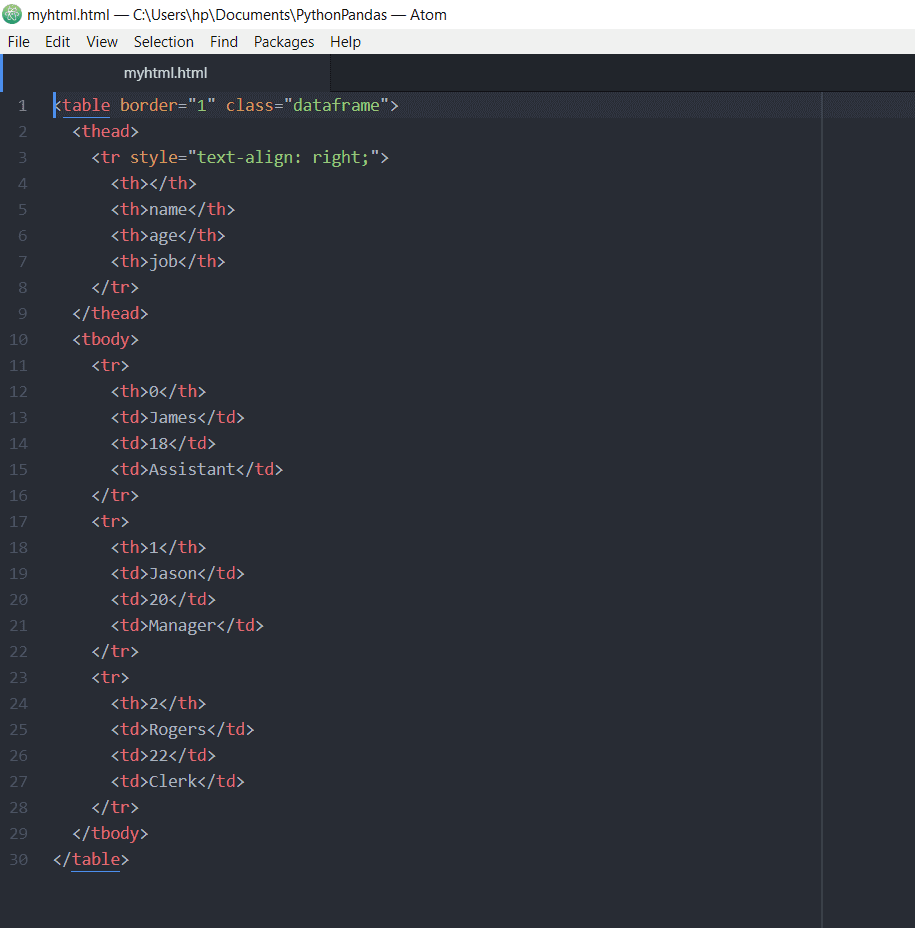
>>> df.to_html("myhtml.html")
結果文件將包含以下內容:
在瀏覽器中打開HTML文件時,它將如下所示:
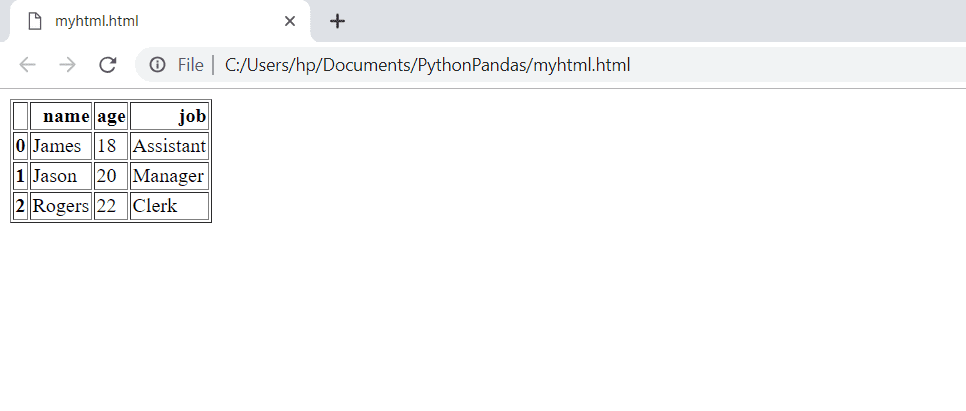
使用大熊貓非常容易。這就像使用Excel工作表一樣!Pandas DataFrame也是一個非常靈活的庫。
我希望你發現這個教程很有用。繼續回來。