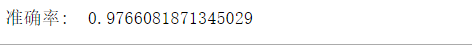如何在 sklearn 中使用 SVM
SVM 既可以做迴歸,也可以做分類器。
當用 SVM 做迴歸的時候,我們可以使用 SVR 或 LinearSVR,即support vector regression
LinearSVR用來處理線性可分的數據,也就是說,使用的線性核函數
如果是針對非線性的數據,需要用到 SVC。在 SVC 中,我們既可以使用到線性核函數(進行線性劃分),也可以使用高緯的核函數進行非線性劃分。
如何創建一個 SVM 分類器呢?
我們首先使用 SVC 的構造函數:model = svm.SVC(kernel=‘rbf’, C=1.0, gamma=‘auto’),這裏有三個重要的參數 kernel、C 和 gamma。
kernel 代表核函數的選擇,它有四種選擇,只不過默認是 rbf,即高斯核函數。

線性核函數優點:是在數據線性可分的情況下使用的,運算速度快,效果好。 缺點:不能處理線性不可分的數據。
多項式核函數:可以將數據從低維空間映射到高維空間, 缺點是參數比較多,計算量大
高斯核函數:可以將數據從低維空間映射到高維空間,但相比於多項式核函數來說所需的參數比較少,通常性能也不錯。
瞭解深度學習的同學應該知道 sigmoid 經常用在神經網絡的映射中,因此當選用 sigmoid 核函數時,SVM 實現的是多層神經網絡。
參數 C 代表目標函數的懲罰係數,懲罰係數指的是分錯樣本時的懲罰程度,默認情況下爲 1.0。當 C 越大的時候,分類器的準確性越高,但同樣容錯率會越低,泛化能力會變差。
參數 gamma 代表核函數的係數,默認爲樣本特徵數的倒數,即 gamma = 1 / n_features。
我們使用 model.fit(train_X,train_y),傳入訓練集中的特徵值矩陣 train_X 和分類標識 train_y。特徵值矩陣就是我們在特徵選擇後抽取的特徵值矩陣(當然你也可以用全部數據作爲特徵值矩陣)。分類標識就是人工事先針對每個樣本標識的分類結果。
我們可以使用 prediction=model.predict(test_X) 來對結果進行預測,傳入測試集中的樣本特徵矩陣 test_X,可以得到測試集的預測分類結果 prediction。
同樣我們也可以創建線性 SVM 分類器,使用 model=svm.LinearSVC()。由於 LinearSVC 對線性分類做了優化,對於數據量大的線性可分問題,使用 LinearSVC 的效率要高於 SVC。
如果你不知道數據集是否爲線性,可以直接使用 SVC 類創建 SVM 分類器。
如何用 SVM 進行乳腺癌檢測
選用的數據集:點擊下載
數據集來自美國威斯康星州的乳腺癌診斷數據集
數據集截圖展示:

涉及的字段名解釋如下:

在 569 個患者中,一共有 357 個是良性,212 個是惡性。其中有30個字段,由於按找平均數,最大值,便準差維度描述,所以,實質只有10個特徵值。
處理步驟:
1、首先我們需要加載數據源;
2、可視化描述數據,用“完全合一”原則處理數據,根據需要選擇特徵值(或特徵工程)
3、在訓練集中訓練模型,在測試集中檢測模型
# encoding=utf-8
import pandas as pd
import numpy as np
data = pd.read_csv("C://Users//baihua//Desktop//data.csv",encoding='utf-8') #這裏要注意,如果文件中有中文,本地文件一定要轉換成 UTF-8的編碼格式
# 數據探索
# 因爲數據集中列比較多,我們需要把 dataframe 中的列全部顯示出來
pd.set_option('display.max_columns', None)
print(data.columns)
print(data.head(5))
print(data.describe())
# 將 B 良性替換爲 0,M 惡性替換爲 1
data['diagnosis']=data['diagnosis'].map({'M':1,'B':0})

#數據清洗
# 將特徵字段分成 3 組
import pandas as pd
import numpy as np
features_mean= list(data.columns[2:12])
features_se= list(data.columns[12:22])
features_worst=list(data.columns[22:32])
# 數據清洗
# ID 列沒有用,刪除該列
#ata.drop(columns=['id'],axis=1,inplace=True)
# 將腫瘤診斷結果可視化
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn import metrics
from sklearn.preprocessing import StandardScaler
plt.show()
# 用熱力圖呈現 features_mean 字段之間的相關性
corr = data[features_mean].corr()
plt.figure(figsize=(14,14))
# annot=True 顯示每個方格的數據
sns.heatmap(corr, annot=True)
plt.show()

熱力圖中對角線上的爲單變量自身的相關係數是 1。顏色越淺代表相關性越大。
所以你能看出來 radius_mean、perimeter_mean 和 area_mean 相關性非常大,compactness_mean、concavity_mean、concave_points_mean 這三個字段也是相關的,因此我們可以取其中的一個作爲代表。
那麼如何進行特徵選擇呢?
我們將相關係數較大的特徵中,選擇一個進行代表;比如我們選擇radius_mean 和 compactness_mean。
這樣我們就可以把原來的 10 個屬性縮減爲 6 個屬性,代碼如下:
# 特徵選擇,只選擇了平均值這一維度,並且還去除了相關係數較大的特徵值
features_remain = ['radius_mean','texture_mean', 'smoothness_mean','compactness_mean','symmetry_mean', 'fractal_dimension_mean']
對特徵進行選擇之後,我們就可以準備訓練集和測試集:
在訓練之前,我們需要對數據進行規範化,這樣讓數據同在同一個量級上,避免因爲維度問題造成數據誤差:
# 抽取 30% 的數據作爲測試集,其餘作爲訓練集
train, test = train_test_split(data, test_size = 0.3)# in this our main data is splitted into train and test
# 抽取特徵選擇的數值作爲訓練和測試數據
train_X = train[features_remain]
train_y=train['diagnosis']
test_X= test[features_remain]
test_y =test['diagnosis']
# 採用 Z-Score 規範化數據,保證每個特徵維度的數據均值爲 0,方差爲 1
ss = StandardScaler()
train_X = ss.fit_transform(train_X)
test_X = ss.transform(test_X)
``
最後我們可以讓 SVM 做訓練和預測了:
創建 SVM 分類器
model = svm.SVC()
用訓練集做訓練
model.fit(train_X,train_y)
用測試集做預測
prediction=model.predict(test_X)
print('準確率: ', metrics.accuracy_score(prediction,test_y))
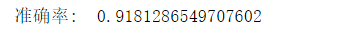
提問:本例中我們使用默認核函數,請你用 LinearSVC,選取全部的特徵(除了 ID 以外)作爲訓練數據,看下你的分類器能得到多少的準確度呢?
上例中,只換核函數:
model = svm.LinearSVC()
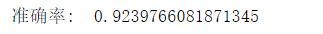
現在,我們將原來平均值特徵,換成所有的特徵值,
特徵選擇
print(data.columns)#去除無用id,和結果指標’diagnosis’,剩下的作爲我們的特徵值
features_remain = [‘radius_mean’, ‘texture_mean’, ‘perimeter_mean’,
‘area_mean’, ‘smoothness_mean’, ‘compactness_mean’, ‘concavity_mean’,
‘concave points_mean’, ‘symmetry_mean’, ‘fractal_dimension_mean’,
‘radius_se’, ‘texture_se’, ‘perimeter_se’, ‘area_se’, ‘smoothness_se’,
‘compactness_se’, ‘concavity_se’, ‘concave points_se’, ‘symmetry_se’,
‘fractal_dimension_se’, ‘radius_worst’, ‘texture_worst’,
‘perimeter_worst’, ‘area_worst’, ‘smoothness_worst’,
‘compactness_worst’, ‘concavity_worst’, ‘concave points_worst’,
‘symmetry_worst’, ‘fractal_dimension_worst’]