




第二部分 進階(Advanced)
3. 流(Streaming)
Calcite擴展了SQL和關係代數以支持流式查詢。
3.1 簡介
流是收集到持續不斷流動的記錄,永遠不停止。與表不同,它們通常不存儲在磁盤上,而流是通過網絡,並在內存中保存很短的時間。
數據流是對錶格的補充,因爲它們代表了企業現在和將來發生的事情,而表格代表了過去。一個流被存檔到一個表中是很常見的。
與表一樣,您經常希望根據關係代數以高級語言查詢流,根據模式(schema)進行驗證,並優化以充分利用可用的資源和算法。
Calcite的SQL是對標準SQL的擴展,而不是另一種“類SQL”的語言。區別很重要,原因如下:
- 對於任何知道常規SQL的人來說,流式SQL都很容易學習。
- 語義清晰,因爲我們的目標是在一個流上產生相同的結果,就好像表中的數據是一樣的。
- 可以編寫結合了流和表(或者流的歷史,基本上是內存表)的查詢。
- 許多現有的工具可以生成標準的SQL。
如果不使用STREAM關鍵字,則返回常規標準SQL。
3.2 schema示例
流式SQL使用以下schema:
- Orders (rowtime, productId, orderId, units):一個流和一個表
- Products (rowtime, productId, name) :一個表
- Shipments (rowtime, orderId) :一個流
3.3 簡單查詢
最簡單的流式查詢:
SELECT STREAM *
FROM Orders;
rowtime | productId | orderId | units
----------+-----------+---------+-------
10:17:00 | 30 | 5 | 4
10:17:05 | 10 | 6 | 1
10:18:05 | 20 | 7 | 2
10:18:07 | 30 | 8 | 20
11:02:00 | 10 | 9 | 6
11:04:00 | 10 | 10 | 1
11:09:30 | 40 | 11 | 12
11:24:11 | 10 | 12 | 4 該查詢讀取Orders流中的所有列和行。與任何流式查詢一樣,它永遠不會終止。只要記錄到達,它就會輸出一條記錄Orders。
輸入Control-C以終止查詢。
STREAM關鍵字是SQL流的主要擴展。它告訴系統你對訂單有興趣,而不是現有訂單。
查詢:
SELECT *
FROM Orders;
rowtime | productId | orderId | units
----------+-----------+---------+-------
08:30:00 | 10 | 1 | 3
08:45:10 | 20 | 2 | 1
09:12:21 | 10 | 3 | 10
09:27:44 | 30 | 4 | 2
4 records returned. 也是有效的,但會打印出現有的所有訂單,然後終止。我們把它稱爲關係查詢,而不是流式處理。它具有傳統的SQL語義。
Orders很特殊,因爲它有一個流和一個表。如果您嘗試在表上運行流式查詢或在流上運行關係式查詢,則Calcite會拋出一個錯誤:
SELECT * FROM Shipments;
ERROR: Cannot convert stream 'SHIPMENTS' to a table
SELECT STREAM * FROM Products;
ERROR: Cannot convert table 'PRODUCTS' to a stream3.4 過濾行
與常規的SQL中一樣,使用一個WHERE子句來過濾行:
SELECT STREAM *
FROM Orders
WHERE units > 3;
rowtime | productId | orderId | units
----------+-----------+---------+-------
10:17:00 | 30 | 5 | 4
10:18:07 | 30 | 8 | 20
11:02:00 | 10 | 9 | 6
11:09:30 | 40 | 11 | 12
11:24:11 | 10 | 12 | 43.5 表達式投影
在SELECT子句中使用表達式來選擇要返回或計算表達式的列:
SELECT STREAM rowtime,
'An order for ' || units || ' '
|| CASE units WHEN 1 THEN 'unit' ELSE 'units' END
|| ' of product #' || productId AS description
FROM Orders;
rowtime | description
----------+---------------------------------------
10:17:00 | An order for 4 units of product #30
10:17:05 | An order for 1 unit of product #10
10:18:05 | An order for 2 units of product #20
10:18:07 | An order for 20 units of product #30
11:02:00 | An order by 6 units of product #10
11:04:00 | An order by 1 unit of product #10
11:09:30 | An order for 12 units of product #40
11:24:11 | An order by 4 units of product #10我們建議您始終在SELECT 條款中包含rowtime列。在每個流和流式查詢中有一個有序的時間戳,可以在稍後進行高級計算,例如GROUP BY和JOIN。
3.6 滾動窗口
有幾種方法可以計算流上的聚合函數。差異是:
- How many rows come out for each row in?
- 每個輸入值總共出現一次還是多次?
- 什麼定義了“窗口”,一組貢獻給輸出行的行?
- 結果是流還是關係?
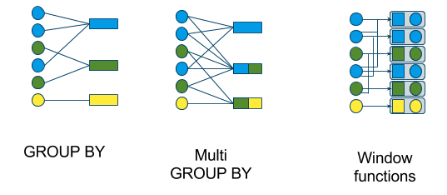
窗口類型:
- 滾動窗口(GROUP BY)
- 跳轉窗口(多GROUP BY)(hopping)
- 滑動窗口(窗口函數)
- 級聯窗口(窗口函數)
下圖顯示了使用它們的查詢類型:![Apache Calcite官方文檔中文版- 進階-3. 流(Streaming)]()
首先,看一個滾動窗口,它是由一個流GROUP BY定義的 。這裏是一個例子:
SELECT STREAM CEIL(rowtime TO HOUR) AS rowtime,
productId,
COUNT(*) AS c,
SUM(units) AS units
FROM Orders
GROUP BY CEIL(rowtime TO HOUR), productId;
rowtime | productId | c | units
------------+---------------+------------+-------
11:00:00 | 30 | 2 | 24
11:00:00 | 10 | 1 | 1
11:00:00 | 20 | 1 | 7
12:00:00 | 10 | 3 | 11
12:00:00 | 40 | 1 | 12 結果是流。在11點整,Calcite發出自10點以來一直到11點有下訂單的 productId的小計。12點,它會發出11:00至12:00之間的訂單。每個輸入行只貢獻到一個輸出行。
Calcite是如何知道10:00:00的小計在11:00:00完成的,這樣就可以發出它們了?它知道rowtime是在增加,而且它也知道CEIL(rowtime TO HOUR)在增加。所以,一旦在11:00:00時間點或之後看到一行,它將永遠不會看到貢獻到上午10:00:00的一行。
增加或減少的列以及表達式是單調的。(單調遞增或單調遞減)
如果列或表達式的值具有輕微的失序,並且流具有用於聲明特定值將不會再被看到的機制(例如標點符號或水印),則該列或表達式被稱爲準單調。
在GROUP BY子句中沒有單調或準單調表達式的情況下,Calcite無法取得進展,並且不允許查詢:
SELECT STREAM productId,
COUNT(*) AS c,
SUM(units) AS units
FROM Orders
GROUP BY productId;
ERROR: Streaming aggregation requires at least one monotonic expression 單調和準單調的列需要在模式中聲明。當記錄輸入流並且由從該流中讀取數據的假定查詢時,單調性被強制執行。我們建議爲每個流指定一個時間戳列rowtime,但也可以聲明其他列是單調的,例如orderId。
我們將在下面的內容討論標點符號,水印,並取得進展的其他方法 。
3.7 滾動窗口,改進
前面的滾動窗口的例子很容易寫,因爲窗口是一個小時。對於不是整個時間單位的時間間隔,例如2小時或2小時17分鐘,則不能使用CEIL,表達式將變得更復雜。
Calcite支持滾動窗口的替代語法:
SELECT STREAM TUMBLE_END(rowtime, INTERVAL '1' HOUR) AS rowtime,
productId,
COUNT(*) AS c,
SUM(units) AS units
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), productId;
rowtime | productId | c | units
----------+-----------+---------+-------
11:00:00 | 30 | 2 | 24
11:00:00 | 10 | 1 | 1
11:00:00 | 20 | 1 | 7
12:00:00 | 10 | 3 | 11
12:00:00 | 40 | 1 | 12 正如你所看到的,它返回與前一個查詢相同的結果。TUMBLE 函數返回一個分組鍵,這個分組鍵在給定的彙總行中將會以相同的方式結束; TUMBLE_END函數採用相同的參數並返回該窗口的結束時間; 當然還有一個TUMBLE_START函數。
TUMBLE有一個可選參數來對齊窗口。在以下示例中,我們使用30分鐘間隔和0:12作爲對齊時間,因此查詢在每小時過去12分鐘和42分鐘時發出彙總:
SELECT STREAM
TUMBLE_END(rowtime, INTERVAL '30' MINUTE, TIME '0:12') AS rowtime,
productId,
COUNT(*) AS c,
SUM(units) AS units
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '30' MINUTE, TIME '0:12'),
productId;
rowtime | productId | c | units
----------+-----------+---------+-------
10:42:00 | 30 | 2 | 24
10:42:00 | 10 | 1 | 1
10:42:00 | 20 | 1 | 7
11:12:00 | 10 | 2 | 7
11:12:00 | 40 | 1 | 12
11:42:00 | 10 | 1 | 43.8 跳轉窗口
跳轉窗口是滾動窗口的泛化(概括),它允許數據在窗口中保持比發出間隔更長的時間。
查詢發出的行的時間戳11:00,包含數據從08:00至11:00(或10:59.9);以及行的時間戳12:00,包含數據從09:00至12:00。
SELECT STREAM
HOP_END(rowtime, INTERVAL '1' HOUR, INTERVAL '3' HOUR) AS rowtime,
COUNT(*) AS c,
SUM(units) AS units
FROM Orders
GROUP BY HOP(rowtime, INTERVAL '1' HOUR, INTERVAL '3' HOUR);
rowtime | c | units
----------+----------+-------
11:00:00 | 4 | 27
12:00:00 | 8 | 50 在這個查詢中,因爲保留期是發出期的3倍,所以每個輸入行都貢獻到3個輸出行。想象一下,HOP函數爲傳入行生成一組Group Keys,並將其值存儲在每個Group Key的累加器中。例如,HOP(10:18:00, INTERVAL '1' HOUR, INTERVAL '3')產生3個時間間隔週期:
[08:00, 09:00)
[09:00, 10:00)
[10:00, 11:00)
這就提出了允許不滿意內置函數HOP和TUMBLE的用戶來自定義的分區函數的可能性。
我們可以建立複雜的複雜表達式,如指數衰減的移動平均線:
SELECT STREAM HOP_END(rowtime),
productId,
SUM(unitPrice * EXP((rowtime - HOP_START(rowtime)) SECOND / INTERVAL '1' HOUR))
/ SUM(EXP((rowtime - HOP_START(rowtime)) SECOND / INTERVAL '1' HOUR))發出:
- 1:00:00包含[10:00:00, 11:00:00)的行;
- 1:00:01包含[10:00:01, 11:00:01)的行。
這個表達最近的訂單比舊訂單權重更高。將窗口從1小時擴展到2小時或1年對結果的準確性幾乎沒有影響(但會使用更多的內存和計算資源)。
請注意,我們在一個聚合函數(SUM)中使用HOP_START,因爲它是一個子彙總(sub-total)內所有行的常量值。對於典型的集合函數( SUM,COUNT等等),這是不允許的。
如果您熟悉GROUPING SETS,可能會注意到,分區函數可以看作是泛化的GROUPING SETS,因爲它們允許一個輸入行對多個子彙總做出貢獻。用於GROUPING SETS的輔助函數諸如如GROUPING()和GROUP_ID可以在聚合函數內部使用,所以並不奇怪, HOP_START和HOP_END可以以相同的方式使用。3.9 分組集合
GROUPING SETS對於流式查詢是有效的,只要每個分組集合包含單調或準單調表達式。
CUBE和ROLLUP不適用於流式查詢,因爲它們將生成至少一個聚合所有內容(如GROUP BY ())的分組集合 。3.10 聚合後Consideration
與標準SQL一樣,可以使用HAVING子句來過濾由流GROUP BY發出的行:
SELECT STREAM TUMBLE_END(rowtime, INTERVAL '1' HOUR) AS rowtime,
productId
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), productId
HAVING COUNT(*) > 2 OR SUM(units) > 10;
rowtime | productId
----------+-----------
10:00:00 | 30
11:00:00 | 103.11 子查詢,視圖和SQL閉包屬性
前述的HAVING查詢可以使用WHERE子查詢中的子句來表示:
SELECT STREAM rowtime, productId
FROM (
SELECT TUMBLE_END(rowtime, INTERVAL '1' HOUR) AS rowtime,
productId,
COUNT(*) AS c,
SUM(units) AS su
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), productId)
WHERE c > 2 OR su > 10;
rowtime | productId
----------+-----------
10:00:00 | 30
11:00:00 | 10
11:00:00 | 40 HAVING子句是在SQL早期引入的,當需要在聚合之後執行過濾器時,(回想一下,WHERE在輸入到達GROUP BY子句之前過濾行)。
從那時起,SQL已經成爲一種數學封閉的語言,這意味着您可以在一個表上執行的任何操作也可以在查詢上執行。
SQL 的閉包屬性非常強大。它不僅使 HAVING陳舊過時(或至少減少到語法糖),它使視圖成爲可能:
CREATE VIEW HourlyOrderTotals (rowtime, productId, c, su) AS
SELECT TUMBLE_END(rowtime, INTERVAL '1' HOUR),
productId,
COUNT(*),
SUM(units)
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), productId;
SELECT STREAM rowtime, productId
FROM HourlyOrderTotals
WHERE c > 2 OR su > 10;
rowtime | productId
----------+-----------
10:00:00 | 30
11:00:00 | 10
11:00:00 | 40 FROM子句中的子查詢有時被稱爲“內聯視圖”,但實際上它們比視圖更基礎。視圖只是一個方便的方法,通過給出這些分片命名並將它們存儲在元數據存儲庫中,將SQL分割成可管理的塊。
很多人發現嵌套的查詢和視圖在流上比在關係上更有用。流式查詢是連續運行的運算符的管道,而且這些管道通常會很長。嵌套的查詢和視圖有助於表達和管理這些管道。
順便說一下,WITH子句可以完成與子查詢或視圖相同的操作:
WITH HourlyOrderTotals (rowtime, productId, c, su) AS (
SELECT TUMBLE_END(rowtime, INTERVAL '1' HOUR),
productId,
COUNT(*),
SUM(units)
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), productId)
SELECT STREAM rowtime, productId
FROM HourlyOrderTotals
WHERE c > 2 OR su > 10;
rowtime | productId
------------+-----------
10:00:00 | 30
11:00:00 | 10
11:00:00 | 403.12 流和關係之間的轉換
回顧一下HourlyOrderTotals視圖的定義。此視圖是流還是關係?
它不包含STREAM關鍵字,所以它是一個關係。但是,這是一種可以轉換成流的關係。
可以在關係和流式查詢中使用它:
# A relation; will query the historic Orders table.
# Returns the largest number of product #10 ever sold in one hour.
SELECT max(su)
FROM HourlyOrderTotals
WHERE productId = 10;
# A stream; will query the Orders stream.
# Returns every hour in which at least one product #10 was sold.
SELECT STREAM rowtime
FROM HourlyOrderTotals
WHERE productId = 10; 這種方法不限於視圖和子查詢。遵循CQL [ 1 ]中規定的方法,流式SQL中的每個查詢都被定義爲關係查詢,並最上面的SELECT使用STREAM關鍵字轉換爲流。
如果STREAM關鍵字存在於子查詢或視圖定義中,則不起作用。
在查詢準備時間,Calcite計算查詢中引用的關係是否可以轉換爲流或歷史的關係。
有時候,一個流可以提供它的一些歷史記錄(比如Apache Kafka [ 2 ]主題中最後24小時的數據),但不是全部。在運行時,Calcite計算出是否有足夠的歷史記錄來運行查詢,如果沒有,則會給出錯誤。
3.13 “餅圖”問題:流上的關係查詢
一個特定的情況下,需要將流轉換爲關係時會發生我所說的“餅圖問題”。想象一下,你需要寫一個帶有圖表的網頁,如下所示,它總結了每個產品在過去一小時內的訂單數量。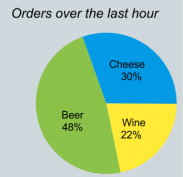
但是這個Orders流只包含幾條記錄,而不是一個小時的彙總。我們需要對流的歷史記錄運行一個關係查詢:
SELECT productId, count(*)
FROM Orders
WHERE rowtime BETWEEN current_timestamp - INTERVAL '1' HOUR
AND current_timestamp;如果Orders流的歷史記錄正在滾動到Orders表中,儘管成本很高,我們可以回答查詢。更好的辦法是,如果我們可以告訴系統將一小時的彙總轉化爲表格,在流式處理過程中不斷維護它,並自動重寫查詢以使用表格。
3.14 排序
ORDER BY的故事類似於GROUP BY。語法看起來像普通的SQL,但是Calcite必須確保它能夠提供及時的結果。因此,它需要在ORDER BY鍵的前沿(leading edge)有一個單調的表達式。
SELECT STREAM CEIL(rowtime TO hour) AS rowtime, productId, orderId, units
FROM Orders
ORDER BY CEIL(rowtime TO hour) ASC, units DESC;
rowtime | productId | orderId | units
----------+-----------+---------+-------
10:00:00 | 30 | 8 | 20
10:00:00 | 30 | 5 | 4
10:00:00 | 20 | 7 | 2
10:00:00 | 10 | 6 | 1
11:00:00 | 40 | 11 | 12
11:00:00 | 10 | 9 | 6
11:00:00 | 10 | 12 | 4
11:00:00 | 10 | 10 | 1大多數查詢將按照插入的順序返回結果,因爲引使用流式算法,但不應該依賴它。例如,考慮一下:
SELECT STREAM *
FROM Orders
WHERE productId = 10
UNION ALL
SELECT STREAM *
FROM Orders
WHERE productId = 30;
rowtime | productId | orderId | units
----------+-----------+---------+-------
10:17:05 | 10 | 6 | 1
10:17:00 | 30 | 5 | 4
10:18:07 | 30 | 8 | 20
11:02:00 | 10 | 9 | 6
11:04:00 | 10 | 10 | 1
11:24:11 | 10 | 12 | 4 productId= 30 的行顯然是不符合order要求的,可能是因爲Orders流以productId分區,分區後的流在不同的時間發送了他們的數據。
如果您需要特定的順序,請添加一個顯式的ORDER BY:
Calcite可能會通過合併使用rowtime實現UNION ALL,這樣只是效率稍微低些。
只需要添加一個ORDER BY到最外層的查詢。如果需要在UNION ALL之後執行GROUP BY,Calcite將會 隱式添加ORDER BY,以便使GROUP BY算法成爲可能。
3.15 表格構造器
VALUES子句創建一個擁有給定行集合的內聯表。
流式傳輸是不允許的。這組行不會發生改變,因此一個流永遠不會返回任何行。
> SELECT STREAM * FROM (VALUES (1, 'abc'));
ERROR: Cannot stream VALUES3.16 滑動窗口
標準SQL的功能特性之一可以在SELECT子句中使用所謂的“分析函數” 。不像GROUP BY,不會摺疊記錄。對於每個進來的記錄,出來一個記錄。但是聚合函數是基於一個多行的窗口。
我們來看一個例子。
SELECT STREAM rowtime,
productId,
units,
SUM(units) OVER (ORDER BY rowtime RANGE INTERVAL '1' HOUR PRECEDING) unitsLastHour 這個功能特性付出很小的努力就包含了很多Power。在SELECT子句中可以有多個函數,基於多個窗口規則定義。
以下示例返回在過去10分鐘內平均訂單數量大於上週平均訂單數量的訂單。
SELECT STREAM *
FROM (
SELECT STREAM rowtime,
productId,
units,
AVG(units) OVER product (RANGE INTERVAL '10' MINUTE PRECEDING) AS m10,
AVG(units) OVER product (RANGE INTERVAL '7' DAY PRECEDING) AS d7
FROM Orders
WINDOW product AS (
ORDER BY rowtime
PARTITION BY productId)) 爲了簡潔起見,在這裏我們使用一種語法,其中使用WINDOW子句部分定義窗口,然後在每個OVER子句中細化窗口。也可以定義WINDOW子句中的所有窗口,或者如果您願意,可以定義所有內聯窗口。
但真正的power超越語法。在幕後,這個查詢維護着兩個表,並且使用FIFO隊列添加和刪除子彙總中的值。但是,無需在查詢中引入聯接,也可以訪問這些表。
窗口化聚合語法的一些其他功能特性:
- 可以根據行數定義窗口。
- 該窗口可以引用尚未到達的行。(流會等到他們到達)。
-
可以計算與順序有關的函數,如RANK中位數。
3.17 級聯窗口
如果我們想要一個返回每個記錄的結果的查詢,比如一個滑動窗口,但是在一個固定的時間段重置總數,就像一個翻滾的窗口?這種模式被稱爲級聯窗口。這裏是一個例子:
SELECT STREAM rowtime, productId, units, SUM(units) OVER (PARTITION BY FLOOR(rowtime TO HOUR)) AS unitsSinceTopOfHour它看起來類似於滑動窗口查詢,但單調表達式出現在PARTITION BY窗口的子句中。由於rowtime從10:59:59到11:00:00,FLOOR(rowtime TO HOUR)從10:00:00到11:00:00發生改變,因此一個新的分區開始。在新的時間到達的第一行將開始新的彙總; 第二行將有一個由兩行組成的彙總,依此類推。
Calcite知道舊分區永遠不會再被使用,因此從內部存儲中刪除該分區的所有子彙總。
使用級聯和滑動窗口的分析函數可以組合在同一個查詢中。3.18 流與表Join
有兩種類型的連接,即stream-to-table join和stream-to-stream join。
如果表的內容沒有改變,則流到表的連接是直接的。這個查詢以每個產品的列出價格豐富了訂單流:SELECT STREAM o.rowtime, o.productId, o.orderId, o.units, p.name, p.unitPrice FROM Orders AS o JOIN Products AS p ON o.productId = p.productId; rowtime | productId | orderId | units | name | unitPrice ----------+-----------+---------+-------+ -------+----------- 10:17:00 | 30 | 5 | 4 | Cheese | 17 10:17:05 | 10 | 6 | 1 | Beer | 0.25 10:18:05 | 20 | 7 | 2 | Wine | 6 10:18:07 | 30 | 8 | 20 | Cheese | 17 11:02:00 | 10 | 9 | 6 | Beer | 0.25 11:04:00 | 10 | 10 | 1 | Beer | 0.25 11:09:30 | 40 | 11 | 12 | Bread | 100 11:24:11 | 10 | 12 | 4 | Beer | 0.25如果表格在改變,會發生什麼?例如,假設product#10的單價在11點增加到0.35。在11:00之前下的訂單應該是舊價格,在11:00之後下的訂單應該反映新價格。
實現此目的的一種方法是創建一個表,使每個版本的開始和結束生效日期保持一致,ProductVersions如下所示:SELECT STREAM * FROM Orders AS o JOIN ProductVersions AS p ON o.productId = p.productId AND o.rowtime BETWEEN p.startDate AND p.endDate rowtime | productId | orderId | units | productId1 | name | unitPrice ----------+-----------+---------+-------+ -----------+--------+----------- 10:17:00 | 30 | 5 | 4 | 30 | Cheese | 17 10:17:05 | 10 | 6 | 1 | 10 | Beer | 0.25 10:18:05 | 20 | 7 | 2 | 20 | Wine | 6 10:18:07 | 30 | 8 | 20 | 30 | Cheese | 17 11:02:00 | 10 | 9 | 6 | 10 | Beer | 0.35 11:04:00 | 10 | 10 | 1 | 10 | Beer | 0.35 11:09:30 | 40 | 11 | 12 | 40 | Bread | 100 11:24:11 | 10 | 12 | 4 | 10 | Beer | 0.35另一種實現方法是使用具有臨時支持的數據庫(能夠像過去的任何時候一樣查找數據庫的內容),並且系統需要知道Orders流的rowtime列對應於Products表的事務時間戳 。
對於許多應用程序而言,暫時支持或版本化表格的成本和努力是不值得的。查詢在重放時給出不同的結果是可以接受的:在這個例子中,在重放時,product#10的所有訂單被分配後來的單價0.35。3.19 流與流Join
如果連接條件以某種方式強迫它們彼此保持有限的距離,那麼流與流的連接就是合理的。在以下查詢中,發貨日期在訂單日期的一小時內:
SELECT STREAM o.rowtime, o.productId, o.orderId, s.rowtime AS shipTime FROM Orders AS o JOIN Shipments AS s ON o.orderId = s.orderId AND s.rowtime BETWEEN o.rowtime AND o.rowtime + INTERVAL '1' HOUR; rowtime | productId | orderId | shipTime ----------+-----------+---------+---------- 10:17:00 | 30 | 5 | 10:55:00 10:17:05 | 10 | 6 | 10:20:00 11:02:00 | 10 | 9 | 11:58:00 11:24:11 | 10 | 12 | 11:44:00請注意,相當多的訂單不會顯示,因爲它們在一個小時內沒有發貨。在系統接收到Order#10時,時間戳爲11:24:11,它已經從其哈希表中刪除了訂單包括Order#8(時間戳10:18:07)。
正如你所看到的,把這兩個流的單調或準單調列聯繫在一起的“鎖定步驟”是系統取得進展所必需的。如果它不能推斷出一個鎖定步驟, 它將拒絕執行一個查詢。3.20 DML
這不僅是查詢對流來說有意義。運行DML語句(INSERT,UPDATE,DELETE,UPSERT和REPLACE)對流來說同樣有意義。
DML非常有用,因爲它允許基於流實現物華流或表格,因此經常使用值可以節省工作量。
考慮到流的應用程序通常由查詢管道組成,每個查詢將輸入流轉換爲輸出流。管道的組件可以是一個視圖:CREATE VIEW LargeOrders AS SELECT STREAM * FROM Orders WHERE units > 1000;或者一個標準的INSERT語句:
INSERT INTO LargeOrders SELECT STREAM * FROM Orders WHERE units > 1000;這些看起來很相似,在這兩種情況下,管道中的下一個步驟都可以讀取LargeOrders,而不用擔心它是如何填充的。效率是有差別的:INSERT無論有多少消費者,做的工作都是相同的。這個視圖的確與消費者的數量成正比,特別是沒有消費者的情況下就沒有工作。
其他形式的DML對於流也是有意義的。例如,以下常設UPSERT語句維護一個表格,以實現最後一小時訂單的彙總:UPSERT INTO OrdersSummary SELECT STREAM productId, COUNT(*) OVER lastHour AS c FROM Orders WINDOW lastHour AS ( PARTITION BY productId ORDER BY rowtime RANGE INTERVAL '1' HOUR PRECEDING)3.21 標點(Punctuation)
Punctuation [ 5 ]允許流式查詢取得進展,即使單調的鍵中沒有足夠的值來推送出結果。
(我更喜歡術語“rowtime bounds”,水印[ 6 ]是一個相關的概念,但爲了這些目的,Punctuation就足夠了。)
如果某個流具有Punctuation,那麼它可能不會被排序,不過仍然可以排序。因此,出於語義的目的,按照排序的流來工作就足夠了。
順便說一下,一個無序的流也是可排序的,如果按t-sorted排序 (即,每個記錄保證在其時間戳的t秒內到達)或k-sorted排序(即每個記錄保證不超過k的位置造成無序)。所以對這些流的查詢可以像帶有Punctuation的流式查詢來進行計劃。
而且,我們經常要聚合不是時間的且是單調的屬性。“一個團隊在獲勝狀態和失敗狀態之間轉移的次數”就是這樣一個單調的屬性。系統需要自己弄清楚聚合這樣一個屬性是否安全; Punctuation不會添加任何額外的信息。
我記得一些計劃器的元數據(成本指標):
- 這個流按給定的一個或多個屬性排序嗎?
- 是否可以對給定屬性的流進行排序?(對於有限的關係,答案總是“是”;對於流,它依賴於Punctuation的存在,或屬性和排序鍵之間的聯繫)。
- 我們需要引入什麼延遲才能執行此類操作?
- 執行此類操作的成本(CPU,內存等)是多少?
在BuiltInMetadata.Collation中,我們已經有了(1)。對於(2),答案對於有限關係總是“true”。但是我們需要爲流實現(2),(3)和(4)。
3.22 流的狀態
並非本文中的所有概念都已經在Calcite中實現。其他的可能在Calcite中實現,但不能在SamzaSQL [ 3 ] [ 4 ] 等特定的適配器中實現。
已實現
- 流式SELECT,WHERE,GROUP BY,HAVING,UNION ALL,ORDER BY
- FLOOR和CEIL函數
- 單調性
- 流式VALUES是不允許的
未實現
本文檔中提供的以下功能特性,以爲Calcite支持它們,但實際上它還沒有實現。全面支持意味着參考實現支持該功能特性(包括負面情況),TCK則對其進行測試。
- 流與流的 JOIN
- 流與表的 JOIN
- 視圖上的流
- 帶有ORDER BY流UNION ALL(合併)
- 流上的關係查詢
- 流式窗口聚合(滑動和級聯窗口)
- 檢查STREAM在子查詢和視圖是否被忽略
- 檢查流的ORDER BY子句不能有OFFSET或LIMIT
- 歷史有限性; 在運行時,檢查是否有足夠的歷史記錄來運行查詢。
- 準單調
- HOP和TUMBLE(和輔助HOP_START,HOP_END, TUMBLE_START,TUMBLE_END)函數
本文檔做了什麼
- 重新訪問是否可以流式傳輸 VALUES
- OVER 子句來定義窗口上的流
- 考慮在流式查詢中是否允許CUBE和ROLLUP,理解某些級別的聚合將永遠不會完成(因爲它們沒有單調表達式),因此不會被髮出。
- 修復該UPSERT示例以刪除在過去一小時內沒有發生的產品的記錄。
- 輸出到多個流的DML; 也許是標準REPLACE語句的擴展 。
3.23 函數
以下函數在標準SQL中不存在,但在流式SQL中定義。
標量函數:
- FLOOR(dateTime TO intervalType) 將日期,時間或時間戳值取下限爲給定的間隔類型
- CEIL(dateTime TO intervalType) 將日期,時間或時間戳值取上限到給定的間隔類型
分區函數:
- HOP(t, emit, retain) 返回一個集合of group keys for a row作爲跳轉窗口的一部分
- HOP(t, emit, retain, align) 返回一個集合of group keys for a row作爲給定對齊的跳轉窗口的一部分
- TUMBLE(t, emit) 返回一個group key for a row作爲滾動窗口的一部分
- TUMBLE(t, emit, align) 返回一個group key for a row作爲給定對齊滾動窗口的一部分
注:
TUMBLE(t, e)相當於TUMBLE(t, e, TIME '00:00:00')。
TUMBLE(t, e, a)相當於HOP(t, e, e, a)。
HOP(t, e, r)相當於HOP(t, e, r, TIME '00:00:00')