- 一:storm 簡介
- 二:storm 的原理與架構
- 三:storm 的 安裝配置
- 四:storm 的啓動腳本
一: storm 的簡介:
1.1 storm 是什麼:
1. Storm是Twitter開源的分佈式實時大數據處理框架,被業界稱爲實時版Hadoop。隨着越來越多的場景對Hadoop的MapReduce高延遲無法容忍,比如網站統計、推薦系統、預警系統、金融系統(高頻交易、股票)等等,大數據實時處理解決方案(流計算)的應用日趨廣泛,目前已是分佈式技術領域最新爆發點,而Storm更是流計算技術中的佼佼者和主流。
2. 按照storm作者的說法,Storm對於實時計算的意義類似於Hadoop對於批處理的意義。Hadoop提供了map、reduce原語,使我們的批處理程序變得簡單和高效。同樣,Storm也爲實時計算提供了一些簡單高效的原語,而且Storm的Trident是基於Storm原語更高級的抽象框架,類似於基於Hadoop的Pig框架,讓開發更加便利和高效。本課程會深入、全面的講解Storm,並穿插企業場景實戰講述Storm的運用。
1.2 實時計算的設計缺點:
數據源務必實時,所以採用Message Queue作爲數據源,消息處理Comsumer實時從MQ獲取數據進行處理,返回結果到Web或寫DB。
這種方式有以下幾個缺陷:
1、單機模式,能處理的數據量有限
2、不健壯,服務器掛掉即結束。而Storm集羣節點掛掉後,任務會重新分配給其他節點,作業不受影響。
3、失敗重試、事務等,你需要在代碼上進行控制,過多精力放在業務開發之外。
4、伸縮性差: 當一個消息處理者的消息量達到閥值,你需要對這些數據進行分流, 你需要配置這些新的處理者以讓他們處理分流的消息。
1.3 storm 的特點:
1. 適用場景廣泛: storm可以實時處理消息和更新DB,對一個數據量進行持續的查詢並返回客戶端(持續計算),對一個耗資源的查詢作實時並行化的處理(分佈式方法調用,即DRPC),storm的這些基礎API可以滿足大量的場景。
2. 可伸縮性高: Storm的可伸縮性可以讓storm每秒可以處理的消息量達到很高。擴展一個實時計算任務,你所需要做的就是加機器並且提高這個計算任務的並行度 。Storm使用ZooKeeper來協調集羣內的各種配置使得Storm的集羣可以很容易的擴展。
3. 保證無數據丟失: 實時系統必須保證所有的數據被成功的處理。 那些會丟失數據的系統的適用場景非常窄, 而storm保證每一條消息都會被處理, 這一點和S4相比有巨大的反差。
4. 異常健壯: storm集羣非常容易管理,輪流重啓節點不影響應用。
5. 容錯性好:在消息處理過程中出現異常, storm會進行重試
6. 語言無關性: Storm的topology和消息處理組件(Bolt)可以用任何語言來定義, 這一點使得任何人都可以使用storm.
二:storm 的原理與架構
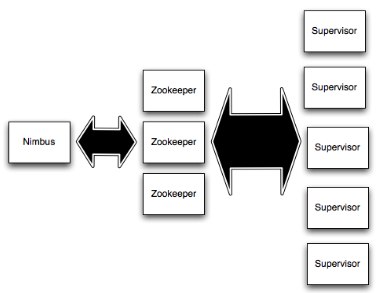
2.1 Storm集羣結構
![image_1al8vbhr315061ik51kic18mcevh9.png-10.5kB]()
![image_1al8vdhb71coifipkc218o31stlm.png-27.3kB]()
1. Nimbus 和Supervisors 之間所有的協調工作是通過 一個Zookeeper 集羣。
2. Nimbus進程和 Supervisors 進程是無法直接連接和無狀態的; 所有的狀態維持在Zookeeper中或保存在本地磁盤上。
3. 這意味着你可以 kill -9 Nimbus 或Supervisors 進程,而不需要做備份。
這種設計導致storm集羣具有令人難以置信的穩定性,即無耦合。
2.2 storm 的工作原理:
1. Nimbus 負責在集羣分發的代碼,topo只能在nimbus機器上提交,將任務分配給其他機器,和故障監測。
2. Supervisor,監聽分配給它的節點,根據Nimbus 的委派在必要時啓動和關閉工作進程。 每個工作進程執行topology 的一個子集。一個運行中的topology 由很多運行在很多機器上的工作進程組成。
3. 在Storm中有對於流stream的抽象,流是一個不間斷的×××的連續tuple,注意Storm在建模事件流時,把流中的事件抽象爲tuple即元組
![image_1al901o4e1fs91pe2g3r15gg1r4s1g.png-68.6kB]()
4. Storm認爲每個stream都有一個源,也就是原始元組的源頭,叫做Spout(管口)
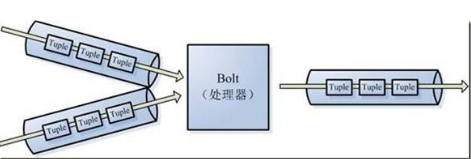
5.處理stream內的tuple,抽象爲Bolt,bolt可以消費任意數量的輸入流,只要將流方向導向該bolt,同時它也可以發送新的流給其他bolt使用,這樣一來,只要打開特定的spout再將spout中流出的tuple導向特定的bolt,又bolt對導入的流做處理後再導向其他bolt或者目的地。
可以認爲spout就是水龍頭,並且每個水龍頭裏流出的水是不同的,我們想拿到哪種水就擰開哪個水龍頭,然後使用管道將水龍頭的水導向到一個水處理器(bolt),水處理器處理後再使用管道導向另一個處理器或者存入容器中。
![image_1al9bqro0104c15k4bk31ttirdl9.png-85.3kB]()
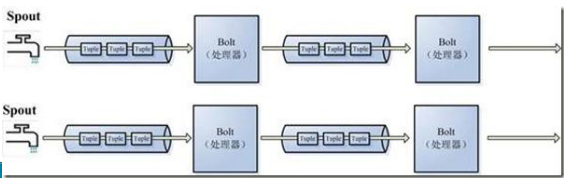
爲了增大水處理效率,我們很自然就想到在同個水源處接上多個水龍頭並使用多個水處理器,這樣就可以提高效率。
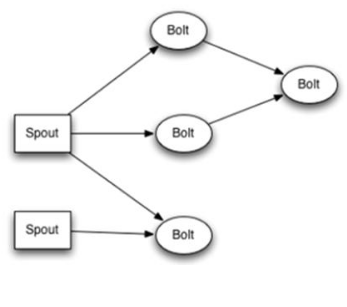
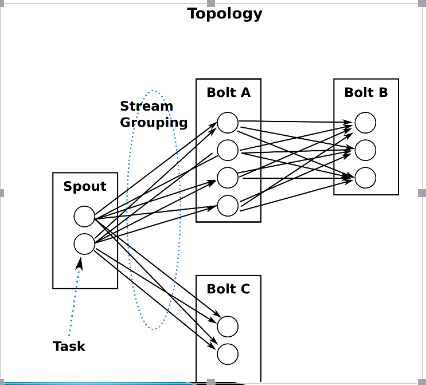
這是一張有向無環圖,Storm將這個圖抽象爲Topology(拓撲),Topo就是storm的Job抽象概念,一個拓撲就是一個流轉換圖
圖中每個節點是一個spout或者bolt,每個spout或者bolt發送元組到下一級組件,廣播方式。
而Spout到單個Bolt有6種grouping方式
![image_1al9cm4v51c2h1dpf001ici1ntam.png-32.4kB]()
2.3 Topology 作業
Storm將流中元素抽象爲tuple,一個tuple就是一個值列表value list,list中的每個value都有一個name,並且該value可以是任意可序列化的類型。拓撲的每個節點都要說明它所發射出的元組的字段的name,其他節點只需要訂閱該name就可以接收處理。
![image_1al9cpn568iieva1gvtt9g1tno13.png-44.6kB]()
2.4 storm 中的角色與概念:
Streams:消息流
消息流是一個沒有邊界的tuple序列,而這些tuples會被以一種分佈式的方式並行創建和處理。 每個tuple可以包含多列,字段類型可以是: integer, long, short, byte, string, double, float, boolean和byte array。 你還可以自定義類型 — 只要你實現對應的序列化器。
Spouts:消息源
Spouts是topology消息生產者。Spout從一個外部源(消息隊列)讀取數據向topology發出tuple。 消息源Spouts可以是可靠的也可以是不可靠的。一個可靠的消息源可以重新發射一個處理失敗的tuple, 一個不可靠的消息源Spouts不會。
Spout類的方法nextTuple不斷髮射tuple到topology,storm在檢測到一個tuple被整個topology成功處理的時候調用ack, 否則調用fail。
storm只對可靠的spout調用ack和fail。
![image_1al9dilk012vs14eg1bf31sd61bsn1t.png-8.5kB]()
Bolts:消息處理者
消息處理邏輯被封裝在bolts裏面,Bolts可以做很多事情: 過濾, 聚合, 查詢數據庫等。
Bolts可以簡單的做消息流的傳遞。複雜的消息流處理往往需要很多步驟, 從而也就需要經過很多Bolts。第一級Bolt的輸出可以作爲下一級Bolt的輸入。而Spout不能有一級。
Bolts的主要方法是execute(死循環)連續處理傳入的tuple,成功處理完每一個tuple調用OutputCollector的ack方法,以通知storm這個tuple被處理完成了。當處理失敗時,可以調fail方法通知Spout端可以重新發送該tuple。
流程是: Bolts處理一個輸入tuple, 然後調用ack通知storm自己已經處理過這個tuple了。storm提供了一個IBasicBolt會自動調用ack。
Bolts使用OutputCollector來發射tuple到下一級Blot。
三:storm 的 安裝配置
3.1 安裝storm環境準備
3.1.1 安裝zookeeper服務:
tar -zxvf zookeeper-3.4.5.tar.gz
mv zookeeper-3.4.5 /usr/local/zookeeper
---
cd /usr/local/zookeeper
mkdir data
cd data
echo "1" > myid
--
cd /usr/local/zookeeper/conf
cp -p zoo_sample.cfg zoo.cfg
vim zoo.cfg
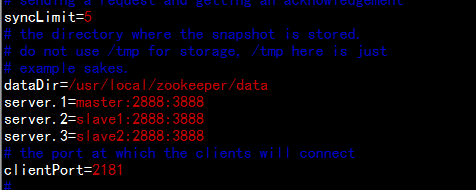
dataDir=/usr/local/zookeeper/data
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
---
cd /usr/local/
tar -zcvf zookeeper.tar.gz zookeeper
--- 同步到slave1 與slave2 節點----
scp zookeeper.tar.gz root@slave1:/usr/local/
scp zookeeper.tar.gz root@slave2:/usr/local/
------------------slave1 節點---------------------
cd /usr/local/
tar -zxvf zookeeepr.tar.gz
cd zookeeper/data
echo '2' > myid
------------------slave2 節點--------------------
cd /usr/local/
tar -zxvf zookeeepr.tar.gz
cd zookeeper/data
echo '3' > myid
![image_1aled2trm1hvsft61t2ope0uto9.png-14.1kB]()
3.1.2 zookeeper 的啓動腳本範例:
#!/bin/bash
if [ $# -ne 1 ]; then
echo "Usage: sh start_zookeeper.sh [start|status|stop]"
exit 2
fi
for node in master slave1 slave2 # ---這個地方有多少個主機就加多少
do
echo "$1 in $node"
ssh $node "source /etc/profile && /opt/modules/zookeeper-3.4.5/bin/zkServer.sh $1"
done
3.1.3 安裝依賴包:
1. CentOS6.4 安裝相關編譯工具包
yum install -y gcc gcc++* gcc-c++ uuid-devel libuuid-devel libtool git
2. 安裝 ZeroMQ
wget http://download.zeromq.org/zeromq-2.1.7.tar.gz
tar -xzvf zeromq-2.1.7.tar.gz
cd zeromq-2.1.7
./configure
make
make install
3. JZMQ安裝
git clone https://github.com/nathanmarz/jzmq.git
cd jzmq
./autogen.sh
./configure
make
make install
3.1.4 storm 安裝:
上傳文件apache-storm-0.9.0.6.tar.gz 到/home/hadoop下面
cd /usr/local/storm
mkdir data
cd conf
---
vim storm.yaml
########### These MUST be filled in for a storm configuration
storm.zookeeper.servers:
- "master"
- "slave1"
- "slave2"
#
nimbus.host: "master"
#
---
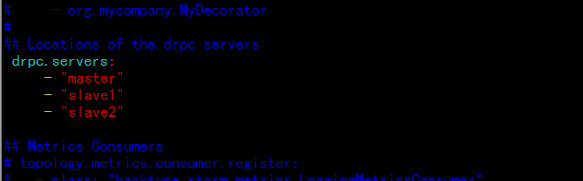
## Locations of the drpc servers
drpc.servers:
- "master"
- "slave1"
- "slave2"
---
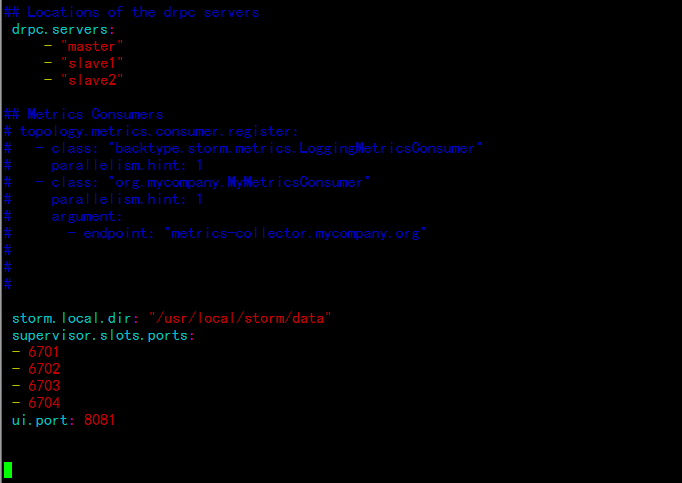
增加storm 任務的目錄與端口:
---
storm.local.dir: "/usr/local/storm/data"
supervisor.slots.ports:
- 6701
- 6702
- 6703
- 6704
ui.port: 8081
------同步所有節點----------
cd /usr/local/
tar -zcvf storm.tar.gz storm
scp storm.tar.gz root@slave1:/usr/local/
scp storm.tar.gz root@slave2:/usr/local/
---------------slave1節點----------
tar -zxvf storm.tar.gz
---------------slave2節點----------
tar -zxvf storm.tar.gz
![image_1aled42gdh591i606uhk88js5m.png-10.3kB]()
![image_1aled4leitf0nflvdjl9h8t313.png-25.9kB]()
3.1.4 啓動服務與瀏覽器訪問
1. 啓動zookeeper 服務
master:
cd /usr/local/zookeeper/
bin/zkServer.sh start
--------------------------------------
slave1:
cd /usr/local/zookeeper/
bin/zkServer.sh start
--------------------------------------
slave2:
cd /usr/local/zookeeper/
bin/zkServer.sh start
--------------------------------------
2. 啓動storm的相關服務
master:
cd /usr/local/storm/
bin/storm nimbus &
bin/storm ui &
------------------------------
slave1
cd /usr/local/storm/
bin/storm supervisor &
------------------------------
slave2
cd /usr/local/storm/
bin/storm supervisor &
-------------------------------
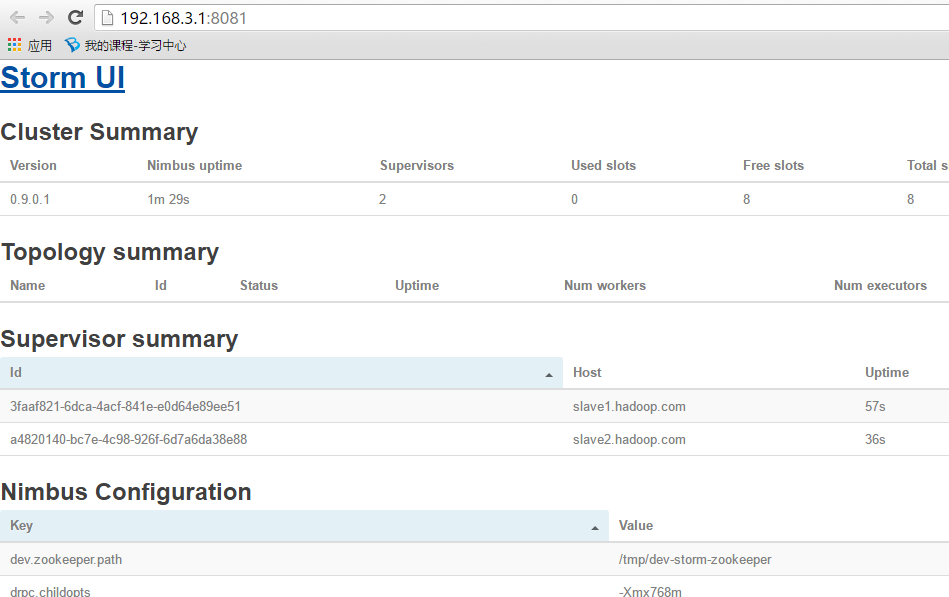
打開瀏覽器訪問:
http://192.168.3.1:8081
![image_1aledqcs19r7cub1jghfsd5a71g.png-66.8kB]()
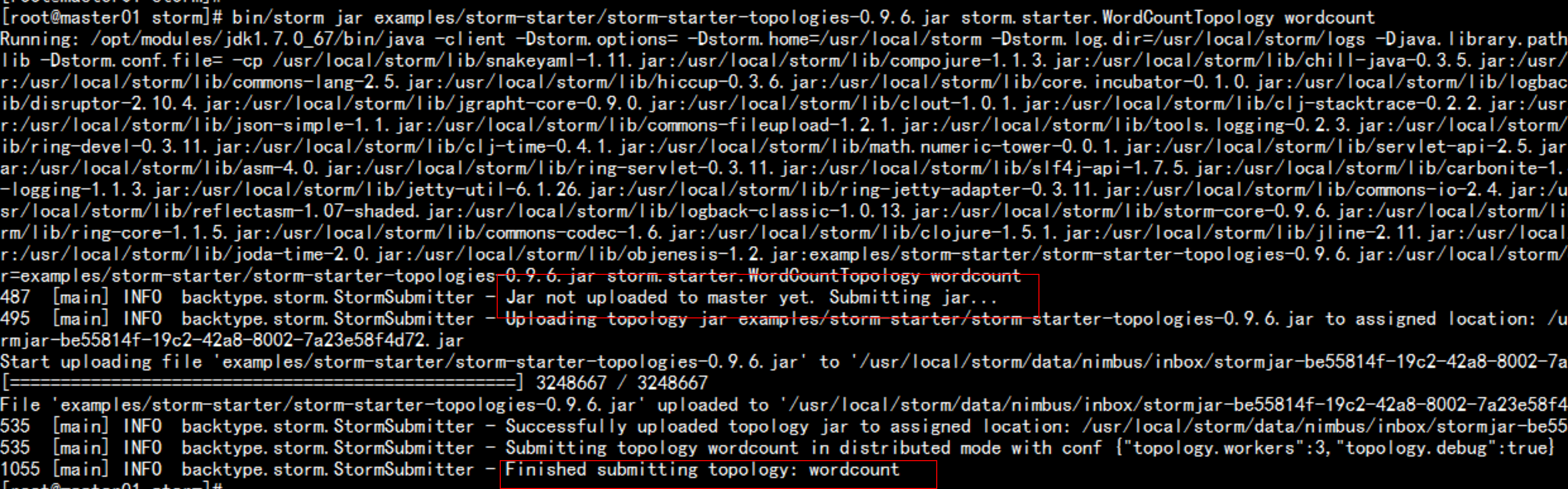
運行wordcount 實例:
bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology wordcount
![image_1b3k1k1us1hck1ad834b15371sdk9.png-718.1kB]()
3.1.5 storm 的參數解析
1. storm.zookeeper.servers:這是一個爲Storm集羣配置的Zookeeper集羣的主機列表
2. storm.local.dir:Nimbus和Supervisor守護程序需要一個本地磁盤目錄存儲小量狀態(像jars,confs,其它),每臺機器都創建這些目錄,賦可寫權限
3. java.library.path:這是Storm使用的本地庫(ZeroMQ和JZMQ)載入路徑。大多數安裝,默認路徑"/usr/local/lib:/opt/local/lib:/usr/lib"就行,所以你可能不需要配置它。
4. supervisor.slots.ports: 每一臺worker機器,你用這個配置來指定多少workers運行在那臺機。每個worker使用單一端口接收消息,並且這個設置定義哪個端口是打開的且可以使用。如果你定義5個端口,那麼Storm將在這臺機分配5個worker運行。
------------------------------------
Storm是一個快速失敗(fail-fast)的系統,這意味着這些進程隨時都可能因發生錯誤而停止。由於Storm的設計,所以它隨時停止都是安全的,當進程重新啓動時正確的恢復。這是爲什麼Storm保持進程無狀態的原因-- 如果Nimbus或supervisors重新啓動,正在運行的topologies是不受影響的。
Nohup掛到後臺執行
1)Nimbus
在master機器的supervision下運行命令”bin/storm nimbus”
2)Supervisor
在每個worker機器的supervision下運行命令”bin/storm supervisor”。Supervisor守護程序負責starting 和 stopping 那臺機上的worker進程
3)UI
運行supervision下的命令”bin/storm ui”來運行Storm UI(你能從瀏覽器訪問一個站點,它提供集羣和topologies的診斷信息)。在你的瀏覽器中輸入” http://{nimbus host}:8081”訪問UI。
3.1.6 strom 的nimbus的主節點特點:
nimbus topology任務提交後,程序是運行在supervisor節點上
Nimbus不參與程序的運行
Nimbus出現故障,不能提交Topology,已經提交了的Topology還是
正常運行在集羣上
已經運行在集羣上Topology,如果這時候某些task出現異常
則無法重現分配節點
-----------------------------------------------------------------
查看Topology運行日誌:
需要啓動一個進程 logviewer
需要在每個supervisor節點上啓動,不用在nimbus節點上啓動
bin/storm logviewer > ./logs/logviewer.out 2>&1 &
nimbus supervisor ui logviewer
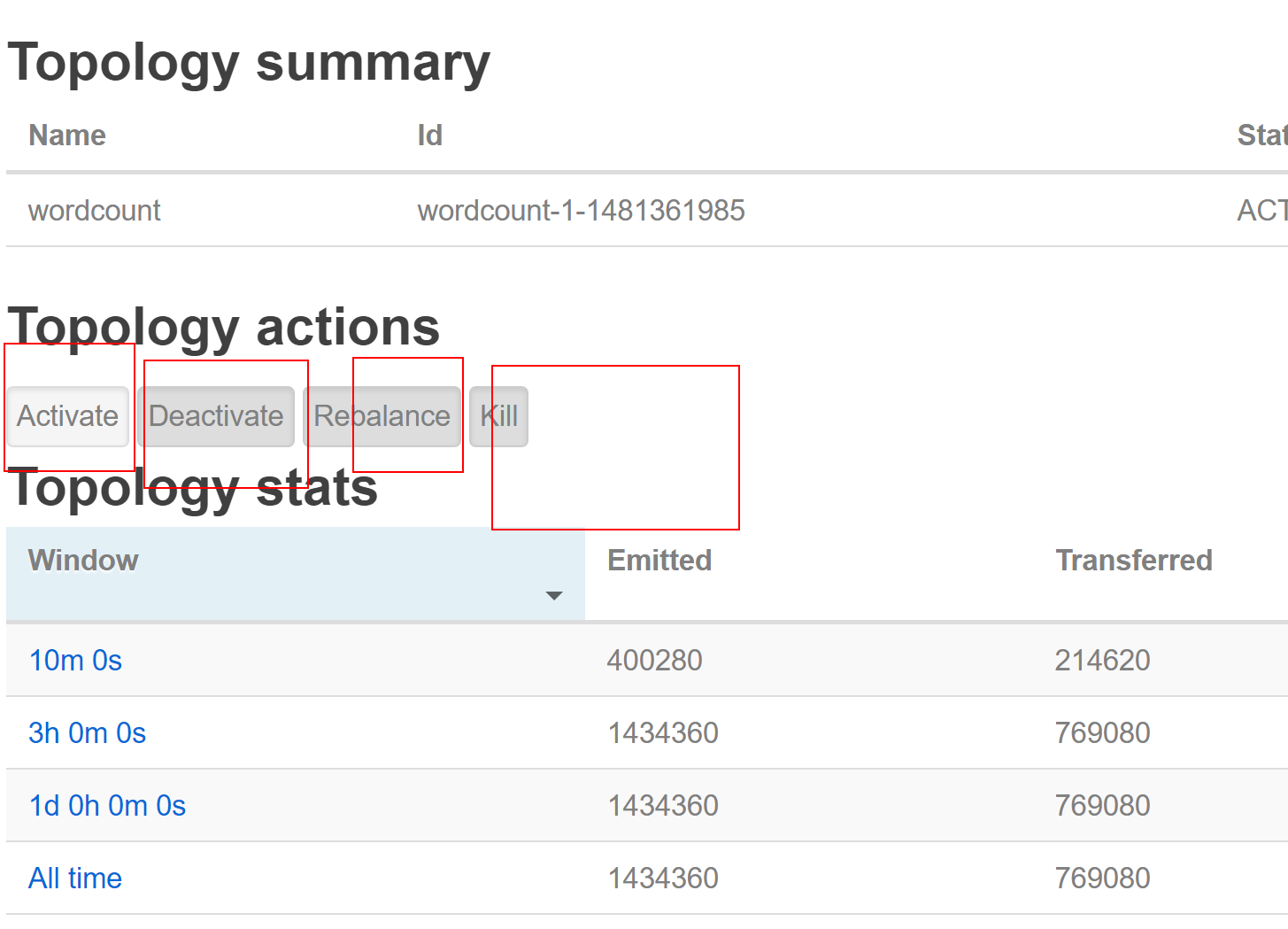
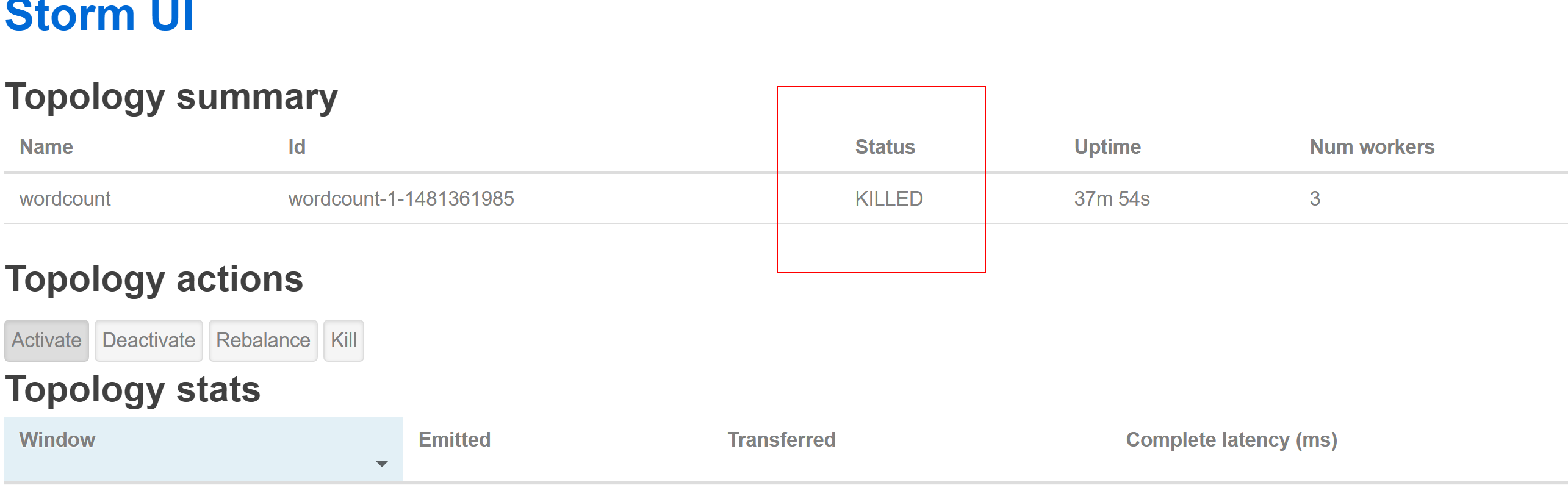
3.1.7 停掉storm 的 worldcount 程序
![image_1b3k2uf1n232sems22ptc1u9nm.png-131kB]()
activate 激活
deactivate 暫停
Repalance 從新分配
kill 殺掉這個 toplogy
![image_1b3k3287o10r87pd1lrt1ji81l5513.png-125.2kB]()
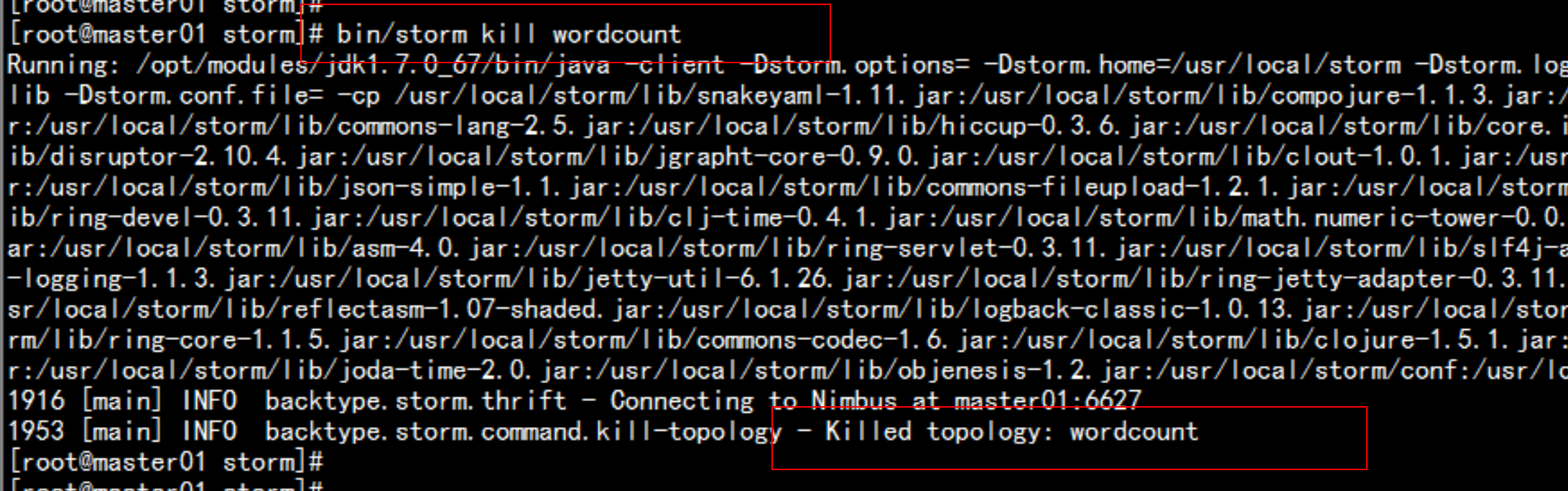
直接通過命令行執行:# bin/storm kill wordcount(提交的時候
指定的Topology名稱)
![image_1b3k39f4rdab1d4i14b4i8j1g1a1g.png-394.6kB]()
3.1.8 先看下Zookeeper怎麼存儲相關狀態信息的
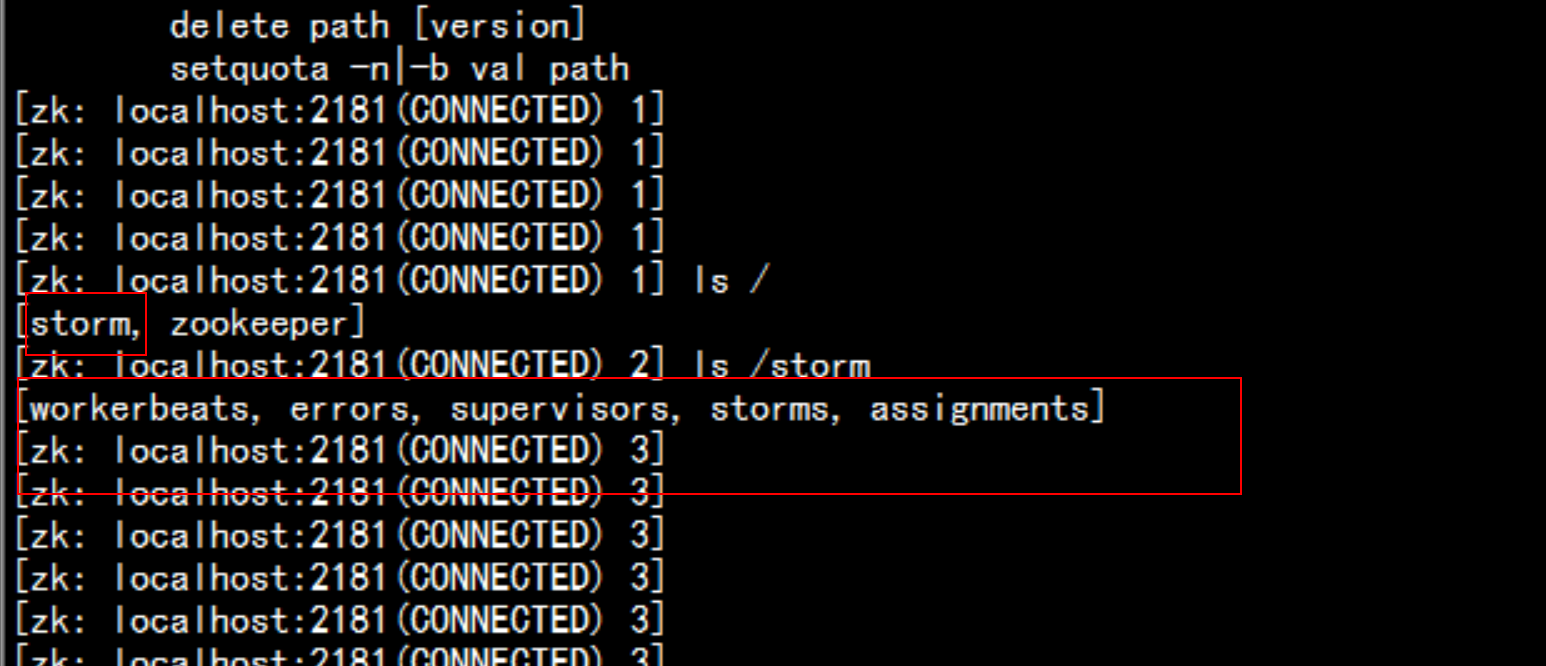
登錄到zookeeper 的裏面去
cd /usr/local/zookeeper/bin
./zkCli.sh
![image_1b3k3nv2n1ps31d9k16jm6ns1am61t.png-297.8kB]()
znode:
/storm
/workerbeats worker心跳信息
/errors topology運行過程中Task運行異常信息
/supervisors 記錄supervisor狀態心跳信息
/storms 記錄的是topology任務信息
/assignments 記錄的是Topology任務的分配信息
3.1.9 nimbus supervisor ui logviewer進程的關閉
kill -9 `ps -ef | grep daemon.nimbus | awk '{print $2}' | head -n 1`
kill -9 `ps -ef | grep ui.core | awk '{print $2}' | head -n 1`
kill -9 `ps -ef | grep daemon.supervisor | awk '{print $2}' | head -n 1`
kill -9 `ps -ef | grep daemon.logviewer | awk '{print $2}' | head -n 1`
3.2.0 storm 的啓動腳本
#!/bin/bash
source /etc/profile
STORM_HOME=/opt/modules/apache-storm-0.9.6
## 主節點 nimbus ui
${STORM_HOME}/bin/storm nimbus > /dev/null 2>&1 &
${STORM_HOME}/bin/storm ui > /dev/null 2>&1 &
## 從節點 supervisor logviewer
for supervisor in `cat ${STORM_HOME}/bin/stormSupervisorHosts`
do
echo "start supervisor and logviewer in $supervisor"
ssh $supervisor "source /etc/profile && ${STORM_HOME}/bin/storm supervisor > /dev/null 2>&1 &" &
ssh $supervisor "source /etc/profile && ${STORM_HOME}/bin/storm logviewer > /dev/null 2>&1 &" &
done
3.2.1 storm 的停止腳本
#!/bin/bash
source /etc/profile
STORM_HOME=/opt/modules/apache-storm-0.9.6
### 主節點 nimbus ui
kill -9 `ps -ef | grep daemon.nimbus | awk '{print $2}' | head -n 1`
kill -9 `ps -ef | grep ui.core | awk '{print $2}' | head -n 1`
### 從節點 supervisor logviewer
for supervisor in `cat ${STORM_HOME}/bin/stormSupervisorHosts`
do
echo "stop supervisor and logviewer in $supervisor"
ssh $supervisor kill -9 `ssh $supervisor "ps -ef| grep daemon.supervisor| awk '{print $2}' | head -n 1" ` > /dev/null 2>&1 &
ssh $supervisor kill -9 `ssh $supervisor "ps -ef| grep daemon.logviewer| awk '{print $2}' | head -n 1" ` >/dev/null 2>&1 &
done