




隨着互聯網+時代的到來,京東金融業務規模不斷擴大,業務場景也不斷創新。但是,業務變化之快超乎想象,相應的 SOA 及微服務架構日趨深入,服務數量不斷膨脹,線上環境日益複雜,服務依賴關係每天都在變化。
● 如何實時看清系統的容量水位,爲容量評估和系統擴容提供客觀依據?
● 當故障發生時,如何精確判斷影響範圍?
● 如何確定每一次交易過程中,每個系統處理耗時分別是多少?
● 每個系統在處理一筆交易時,分別在數據庫、NoSQL、緩存、日誌、RPC、業務邏輯上耗時多少?
● 如何快速確定系統的真正瓶頸點?
面對上述難題,本文將從智能容量評估與智能告警切入,爲大家分享京東金融的運維實踐。
智能容量評
應用的容量評估是一個老大難問題,目前也沒有一種簡單而有效的方式,主要是通過壓測手段直接得到應用單機最高 QPS 的相關數據。
線下壓測
爲了測試數據的相對真實性,在容量評估的線下壓測中一般通過 tcpcopy 等工具,將線上的流量直接複製到測試服務器,在測試服務器出現瓶頸時得到應用最高的 QPS,再通過線上線下的換算係數推算出線上的應用能承載的容量。

注:本圖片轉自tcpcopy官網
線上壓測
通過線下壓測的方式進行容量評估的優點是壓測過程對線上的環境幾乎沒有影響,但是過程比較繁瑣,耗時也較長。所以以短平快爲主要特色的互聯網公司更鐘愛通過線上的壓測來進行容量評估。
如何進行線上的壓測?
一般來說,不管是通過集中的負載設備(如 F5、Radware 等)或是四七層的軟負載(LVS、Nginx、HAProxy 等)亦或是開源的服務框架(如 Spring Cloud、DUBBO 等)都支持加權輪詢算法(Weighted Round Robin)。簡單的說就是在負載輪詢的時候,不同的服務器可以指定不同的權重。
線上壓測的原理就是逐漸加大某一臺服務器的權重,使這臺服務器的流量遠大於其他服務器,直至該服務器出現性能瓶頸。這個瓶頸可能是 CPU、LOAD、內存、帶寬等物理瓶頸,也可能是 RT、失敗率、QPS 波動等軟瓶頸。
當單機性能出現性能瓶頸時,工程師記下此時的應用 QPS 就是單機容量,然後根據集羣服務器數量很容易得到集羣的容量。
如下 Nginx 的配置,使得服務器 192.168.0.2 的流量是其他服務器的 5 倍,假設此時服務器 192.168.0.2 出現瓶頸,QPS 爲 1000,那麼集羣容量爲 3000。(假設負載沒有瓶頸)
http {
upstream cluster {
server 192.168.0.2 weight= 5;
server 192.168.0.3 weight= 1;
server 192.168.0.4 weight= 1;
}
}容量計算
不管是線上還是線下的壓測,反映的都是壓測時的應用容量。在互聯網快速發展的今天,程序版本迭代的速度驚人,針對每次版本的迭代、環境的變化都進行一次線上的壓測是不現實的,也是不具備可操作性的。
那麼換一種思路去思考,我們通過壓測去評估應用的容量其實是因爲我們無法知道具體的一個方法的耗時到底在哪裏?也就是說被壓測的對象對我們是一個黑盒子,如果我們想辦法打開了這個黑盒子,理論上我們就有辦法計算應用的容量,而且可以做到實時的應用容量評估。
因此,迫切需要尋求另外一種解決問題的思路:QPS 的瓶頸到底是什麼?如果弄清楚了這個問題,應用的 QPS 就可以通過計算得到。
再結合下圖的耗時明細和應用所處的運行環境,我們就可以找到具體的瓶頸點。
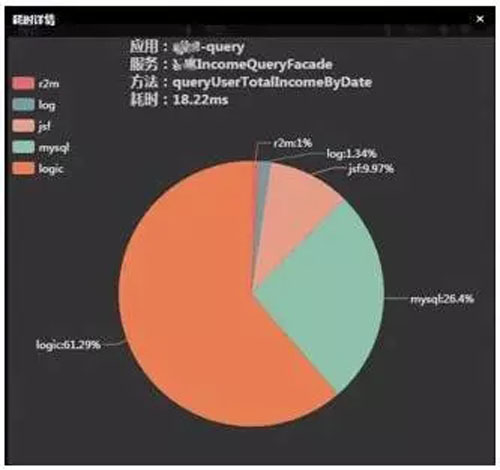
舉一個簡單的例子:
如果一個方法在一定採樣時間內,平均 QPS 爲 200,平均耗時爲 100ms,耗時明細分析發現平均訪問數據庫 6 次,每次耗時 10ms,也就是數據庫總耗時 60ms,其他均爲業務邏輯耗時 40ms。如何確定應用的容量呢?
假如數據庫連接池的最大連接數爲 30,執行此方法的線程池最大爲 50(簡單起見暫時不考慮線程的切換成本),那麼理論上數據庫的單機最高 QPS 爲 30*1000/60=500。
同理業務邏輯的單機最高 QPS 爲 50*1000/40=1250,顯然這個方法的瓶頸點在數據庫上,也就是這個方法的單機最高 QPS 爲 500。
然後,針對這個方法進行優化,數據庫每次訪問的耗時降到了 5ms,平均訪問次數變成了 4 次,也就是數據庫總耗時爲 20ms,業務邏輯耗時依然是 40ms,此時數據庫的單機最高 QPS 爲 30*1000/20=1500。顯然此時的瓶頸點在業務邏輯上,也就是這個方法的單機最高 QPS 爲 1250。
上例爲一個方法的單機最高 QPS 推斷,結合其他方法做同理分析,依據計算出這個方法在整個應用中對資源的佔用比例就可以推算出整個應用的單機最高 QPS。
進一步分析,業務邏輯耗時也就是總耗時去除了 IO 的耗時(如 RPC 遠程調用、訪問數據庫、讀寫磁盤耗時等等),業務邏輯耗時主要分爲兩大部分:
● 線程運行耗時(RUNNABLE)
● 線程等待耗時(BLOCKED、WAITING、TIMED_WAITING)
通過對業務邏輯耗時的分類得知,真正消耗 CPU 資源的是線程運行耗時,那麼問題就變成了我們怎麼拿到運行時間與等待時間的耗時比例了。
CPU 使用率(進程、線程)可以通過 proc 虛擬文件系統得到,此處不是本文重點,不展開討論。不同環境還可以通過不同的特性快速得到這些數據。以 Java 應用爲例,我們可以從 JMX 中拿到線程執行的統計情況,大致推算出上述的比例,如下圖所示:
繼續分析上面的例子,假設我們通過分析線程的運行情況得知,運行時間與等待時間爲 1:1,此時進程 CPU 的使用率爲 20%,那麼 CPU 指標能支撐的單機最高 QPS 爲 200 * 100% / 20% = 1000,也就是這個方法的單機最高 QPS 爲 1000。同理可以推斷網絡帶寬等物理資源的瓶頸點。
一般來說,業務邏輯耗時中,對於計算密集型的應用,CPU 計算耗時的比例比較大,而 IO 密集型的應用反之。
通過以上的數據,我們就可以實時評估系統的容量,如下圖:

應用實時水位圖
智能告警
根源告警分析是基於網絡拓撲,結合調用鏈,通過時間相關性、權重、機器學習等算法,將告警進行分類篩選,快速找到告警根源的一種方式。它能從大量的告警中找到問題的根源,因此大大縮短了故障排查及恢復時間。
告警處理步驟
● 告警過濾(將告警中不重要的告警以及重複告警過濾掉)
● 生成派生告警(根源關聯關係生成各類派生告警)
● 告警關聯(同一個時間窗內,不同類型派生告警是否存在關聯)
● 權重計算(根據預先設置的各類告警的權重,計算成爲根源告警的可能性)
● 生成根源告警(將權重最大的派生告警標記爲根源告警)
● 根源告警合併(若多類告警計算出的根源告警相同,則將其合併)
● 根據歷史告警處理知識庫,找到類似根源告警的處理方案,智能地給出解決方案。

根源告警原理圖
舉例來說:
假設多個系統通過 RPC 進行服務調用,調用關係如下:D 系統->C 系統-> B 系統-> A 系統。
當 A 系統查詢數據庫出現查詢超時後,告警會層層往前推進,導致 B、C、D 系統均有 N 個超時告警產生。此時,ROOT 分析可以將告警進行收斂,直接分析出根源告警爲 A 系統訪問數據庫異常,導致 A、B、C、D 多個系統異常。
這樣,就避免了處理人員和每個系統開發人員溝通,輔助處理人員快速定位問題根源、提高了平均解決時間(MTTR)。如下圖所示:

根源告警調用鏈關係
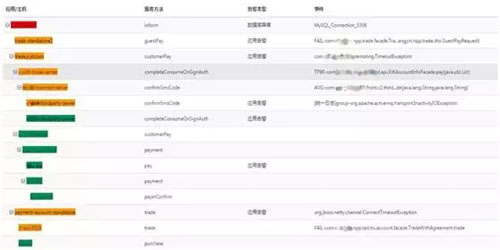
根源告警明細表
根源告警分析主要分爲強關聯分析與機器學習兩類。
a.強關聯數據分析
強關聯指的是已知確定的關聯關係。如:
● 應用之間的調用鏈關係
● 數據庫與應用服務器
● 網絡設備與網絡設備、網絡設備與應用服務器
● 宿主機與虛擬機關係等
若在同一個時間窗內,有多個強關聯的設備或應用服務器同時告警,則大概率認爲告警之間存在關聯關係。
在權重算法中,有一個重要的規則,鏈路上存在連續的告警可能存在關聯,越靠後的應用越可能是根源。現在我們根據例子,分別計算各類根源告警。
繼續使用上面的例子,D 應用->C 應用->B 應用->A 應用->數據庫異常的情況。
● 首先是計算數據庫根源告警。根據數據庫關聯關係,會派生數據庫類型的數據庫告警、A 應用告警。還會派生一條應用類型的 A 應用數據庫異常告警。
根據數據庫派生告警以及數據庫與應用的關聯關係及權重,可以得出數據庫異常導致 A 應用查詢超時。
● 接下來是計算應用根源告警。根據調用關係,我們先計算出連續多個應用告警的鏈路。當前 D->C->B->A 四個應用都有派生告警,滿足此規則。
● 然後,找到最靠後的告警應用,也就是 A 應用。列舉時間窗口內所有 A 應用的派生告警(可能存在多種派生告警,根據權重計算根源),將權重最高的派生告警標記爲根源告警。
比如:A 系統內部有 2 種類型派生告警,分別是數據庫告警、GC 告警。
根據權重計算規則,數據庫告警爲 90,GC 告警 10,也就是說數據庫異常告警權重最高。這時由於數據庫根源告警和調用鏈根源告警一致,會將兩種類型的告警合併。最後得出結論:數據庫異常導致 A、B、C、D 系統告警。
b.機器學習根源分析
強關聯數據分析是對已知告警的關聯關係,直接進行根源告警分析。但是有些時候,關聯關係是未知的。這時就需要通過機器學習算法,找到告警之間的隱含聯繫,再進行根源告警預測。
目前,主要進行了兩類機器學習實踐。
1、關聯規則算法
關聯規則算法主要進行了 Apriori 算法和 FPGrowth 兩類算法的實踐。這兩類功能相似,都可以發現頻繁項集。經過實測,FPGrowth 比 Apriori 更高效一些。
我們按一定的時間間隔劃分時間窗,計算每個時間窗內,各種告警一起出現的頻率,找出各類告警之間的關聯。最終可按分析出的關聯關係,生成根源告警。
關聯規則算法的優點在於理解和實現起來比較簡單。缺點是效率比較低,靈活度也不夠高。
2、神經網絡算法
循環神經網絡(簡稱 RNN)是一個和時間序列有關係的神經網絡,對單張圖片而言,像素信息是靜止的,而對於一段話而言,裏面的詞的組成是有先後的,而且通常情況下,後續的詞和前面的詞有順序關聯。
這時候,卷積神經網絡通常很難處理這種時序關聯信息,而 RNN 卻能有效地進行處理。
隨着時間間隔的增大,RNN 對於後面時間的節點相比前面時間節點的感知力將下降。解決這個問題需要用到 LongShort Term 網絡(簡稱 LSTM),它通過刻意的設計來避免長期依賴問題。LSTM 在實踐中默認可以記住長期的信息,而不需要付出很大代價。
對於某類故障引起的大量告警之間,存在着時間相關性。將歷史派生告警作爲輸入,將根源告警類型作爲輸出。通過 LSTM 提取派生告警特徵,建立告警相關性分析模型。這樣就可以實時將符合特徵的派生告警,劃分到同一類根源告警中,幫助用戶快速定位問題。
需要說明的是金融本身的業務特點決定了對第三方存在依賴性,因此告警本身的隨機性較大,客觀上導致學習樣本的質量不高,需要長期的積累和修正才能達到比較好的效果,因此對於根源告警,如果有條件取到強關聯關係,建議使用強關聯分析,能達到事半功倍的效果。
結語
智能運維是目前運維領域被炒得最火的詞彙之一,但是個人認爲沒有一個智能運維的產品是放之四海而皆準,智能運維需要在真實的環境中不斷的磨合,才能達到我們預期的效果。
隨着人工智能在運維領域的不斷嘗試與探索,未來在運維領域中的異常檢測與智能報警及自動化容量規劃與分配必將得到快速的發展,從而成爲運維的核心競爭力。

沈建林 ● 京東金融集團資深架構師
曾在多家知名第三方支付公司任職系統架構師,致力於基礎中間件與支付核心平臺的研發,主導過 RPC 服務框架、數據庫分庫分表、統一日誌平臺,分佈式服務跟蹤、流程編排等一系列中間件的設計與研發,參與過多家支付公司支付核心系統的建設。現任京東金融集團資深架構師,負責基礎開發部基礎中間件的設計和研發工作。擅長基礎中間件設計與開發,關注大型分佈式系統、JVM 原理及調優、服務治理與監控等領域。
