




今天跟一個測試同事聊天:
我:最近忙什麼項目呢?
他:在測大數據血緣
我:啥?
他:血緣啊
我:啥血緣?
他:大數據血緣啊
我:血緣是啥?
他:就是數據血緣啊
我:...
看看,天就是這麼被聊死的,我忍不住內心OS(怪不得你禿頂還沒女朋友)
我趕緊回來問問 google,分析了各路答案之後,可以總結成兩句話:
通常我們會對原始數據進行多個步驟的各種加工,最後產生出新的數據,在這個過程中會產生很多表,這些數據表之間的鏈路關係就可稱爲大數據血緣。
大數據血緣測試,就是測試數據流轉過程中的每個環節的數據質量。
同時,數據血緣還有幾個同義詞:
Data Lineage 數據血緣(數據血統) = Data Provenance 數據起源 = Data Pedigree 數據譜系
在現實世界中,我們每個個體都是祖先通過生育關係一代×××育而來,這樣就形成了我們人類的各種血緣關係。
在數據信息時代,每時每刻都會產生龐大的數據,即我們通常說的大數據,對這些數據進行各種加工組合、轉換,又會產生新的數據,這些數據之間就存在着天然的聯繫,我們把這些聯繫稱爲數據血緣關係。
直白點說,數據血緣就是指數據產生的鏈路關係,就是這個數據是怎麼來的,經過了哪些過程和階段。
下面舉個通俗點的例子:
比如在淘寶網中,客戶在淘寶網頁中購買物品後,數據就被存到後臺數據庫表A中。我們希望查看某個月賣的最火的是哪些物品時,就需要對數據庫中的原始數據進行加工彙總,形成一張中間表B來存儲階段處理的數據,若邏輯較複雜時,還要繼續加工繼續形成中間表。。。直到最後處理成我們前臺展現使用的最終表,假設爲C表。
那麼A表是C表數據最初的來源,是C表數據的祖先。從A表數據到B表數據再到C表數據,這條鏈路就是C表的數據血緣。
在數據的處理過程中,從數據源頭到最終的數據生成,每個環節都可能會導致我們出現數據質量的問題。比如我們數據源本身數據質量不高,在後續的處理環節中如果沒有進行數據質量的檢測和處理,那麼這個數據信息最終流轉到我們的目標表,它的數據質量也是不高的。也有可能在某個環節的數據處理中,我們對數據進行了一些不恰當的處理,導致後續環節的數據質量變得糟糕。
因此,對於數據的血緣關係,我們要確保每個環節都要注意數據質量的檢測和處理,那麼我們後續數據纔會有優良的基因,即有很高的數據質量。
數據血緣的常見分析過程:
現在假設你是一名數據開發工程師,爲了滿足某個業務需求,需要生成最終表 X。
可能是出於程序邏輯清晰或者性能優化的考慮,你爲了生成這張表,通過 MR、Spark 或者 Hive 來生成很多中間表。
如下圖,是你將花費時間來實現的整個數據流,其中:
Table X 是最終給到業務側的表
藍色的 Table A-E,是原始數據
×××的 Table F-I ,是你計算出來的中間表,這些都是你自己寫程序要處理的表
Table J ,是別人處理過的結果表,因爲本着不重複開發的原則,你很可能要用到同事小夥伴處理的表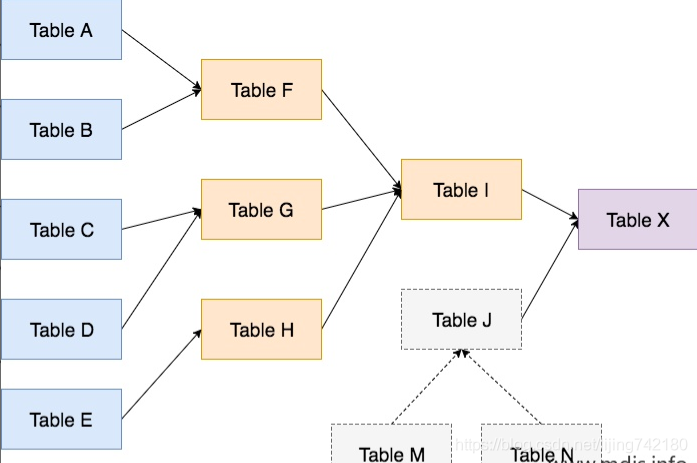
過了一段時間後,業務側的感覺你提供的數據中有個字段總是不太對勁,其實就是懷疑你的數據出問題!需要你來追蹤一下這個字段的來源。
首先你從 Table X 中找到了異常的字段,然後定位到了它來源於 Table I,再從 Table I 定位到了它來源於 Table G, 再從 Table G 追溯到了 Table D,最終發現是某幾天的來源數據有異常。或者說,你從 Table X 定位到了異常的字段原來來自於其它小夥伴處理的表 Table J,然後繼續向前回溯,找到了這張表在處理過程中的某一個步出現了問題。
上面的過程是數據血緣分析的過程。
到此,相信你已經大概明白血緣是啥了。
再囉嗦兩句,其實數據血緣並不難,只是概念比較高大上而已,實際我們測試的時候跟普通的 sql 操作差不多,只是用到的語法是 hive、sqoop、pig 等組件相對應的語法,不是常見的 sql 語法而已。