




spaCy是最流行的開源NLP開發包之一,它有極快的處理速度,並且預置了詞性標註、句法依存分析、命名實體識別等多個自然語言處理的必備模型,因此受到社區的熱烈歡迎。中文版預訓練模型包括詞性標註、依存分析和命名實體識別,由匯智網提供,下載地址:spaCy2.1中文模型包 。
1、模型下載安裝與使用
下載後解壓到一個目錄即可,例如假設解壓到目錄 /models/zh_spacy,目錄結構如下:
/spacy/zh_model
| - meta.json # 模型描述信息
| - tokenizer
| - vocab # 詞庫目錄
| - tagger # 詞性標註模型
| - parser # 依存分析模型
| - ner # 命名實體識別模型使用spaCy載入該模型目錄即可。例如:
import spacy
nlp = spacy.load('/spacy/zh_model')
doc = nlp('西門子將努力參與中國的三峽工程建設。')
for token in doc:
print(token.text)spaCy2.1中文預訓練模型下載地址:http://sc.hubwiz.com/codebag/zh-spacy-model/
2、使用詞向量
spaCy中文模型採用了中文維基語料預訓練的300維詞向量,共352217個詞條。
例如,查看詞向量表大小及維度:
import spacy
nlp = spacy.load('/spacy/zh_model')
print(nlp.vocab.vectors.shape)
print(nlp.vocab['北京'].vector)結果如下:
(352217, 300)
[-0.136166 -0.339835 0.528109 0.417842 -0.093321 -0.42306 -0.475931
-0.125459 0.137432 -0.567229 0.242339 0.245993 -0.377495 -0.274273
...
0.238025 0.309567 -0.692431 -0.078103 -0.26816 0.051805 0.075192
-0.052902 0.376131 -0.221235 0.23855 -0.11685 0.40507 ]3、使用詞性標註
spaCy中文詞性標註模型採用Universal Dependency的中文語料庫進行訓練。
import spacy
nlp = spacy.load('/spacy/zh_model')
doc = nlp('西門子將努力參與中國的三峽工程建設。')
for token in doc:
print(token.text,token.pos_,token.tag_)將得到如下的詞性標註結果:
西門子 NNP
將 BB
努力 RB
參與 VV
中國 NNP
的 DEC
三峽工程 NN
建設 NN4、使用依存分析
spaCy中文依存分析模型採用Universal Dependency的中文語料庫進行訓練。
例如,下面的代碼輸出各詞條的文本、依賴關係以及其依賴的詞條:
import spacy
nlp = spacy.load('/spacy/zh_model')
doc = nlp('西門子將努力參與中國的三峽工程建設。')
for token in doc:
print(token.text,token.dep_,token.head)輸出結果如下:
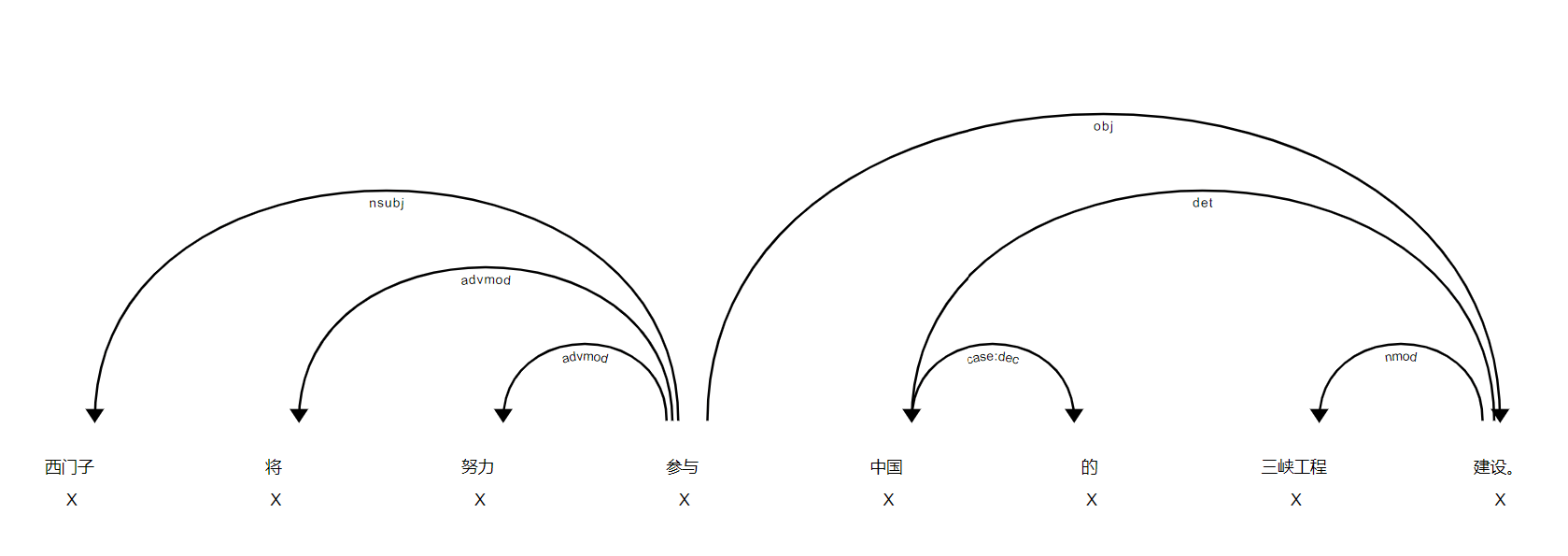
西門子 nsubj 參與
將 advmod 參與
努力 advmod 參與
參與 ROOT 參與
中國 det 建設
的 case:dec 中國
三峽工程 nmod 建設
建設 obj 參與
。 punct 參與也可以使用spaCy內置的可視化工具:
from spacy import displacy
displacy.render(doc,type='dep')結果如下:
5、使用命名實體識別
spaCy中文NER模型採用ontonotes 5.0數據集訓練。
例如:
import spacy
nlp = spacy.load('/spacy/zh_model')
doc = nlp('西門子將努力參與中國的三峽工程建設。')
for ent in doc.ents:
print(ent.text,ent.label_)輸出結果如下:
西門子 ORG
中國 GPE
三峽工程 FAC也可以使用spaCy內置的可視化工具:
from spacy import displacy
displacy.render(doc,type='ent')運行結果如下:

原文鏈接:spaCy2.1中文模型包 — 匯智網