




環境說明:
| 主機名 | 操作系統版本 | ip | docker version | kubelet version | 配置 | 備註 |
|---|---|---|---|---|---|---|
| master | Centos 7.6.1810 | 172.27.9.131 | Docker 18.09.6 | V1.14.2 | 2C2G | 備註 |
| node01 | Centos 7.6.1810 | 172.27.9.135 | Docker 18.09.6 | V1.14.2 | 2C2G | 備註 |
| node02 | Centos 7.6.1810 | 172.27.9.136 | Docker 18.09.6 | V1.14.2 | 2C2G | 備註 |
k8s集羣部署詳見:Centos7.6部署k8s(v1.14.2)集羣
k8s學習資料詳見:基本概念、kubectl命令和資料分享
一、爲什麼需要容器探針
如何保持Pod健康
只要將pod調度到某個節點,Kubelet就會運行pod的容器,如果該pod的容器有一個或者所有的都終止運行(容器的主進程崩潰),Kubelet將重啓容器,所以即使應用程序本身沒有做任何特殊的事,在Kubemetes中運行也能自動獲得自我修復的能力。
自動重啓容器以保證應用的正常運行,這是使用Kubernetes的優勢,不過在某些情況,即使進程沒有崩潰,有時應用程序運行也會出錯。默認情況下Kubernetes只是檢查Pod容器是否正常運行,但容器正常運行並不一定代表應用健康,在以下兩種情況下Kubernetes將不會重啓容器:
- 1.訪問Web服務器時顯示500內部錯誤
- 該報錯可能是系統超載,也可能是資源死鎖,不過此時httpd進程依舊運行,重啓容器可能是最直接有效的辦法。
- 2.具有內存泄漏的Java應用程序將開始拋出OutOfMemoryErrors
- 此時JVM進程會一直運行,Kubernetes也不會重啓容器,但此時對應用來講是異常的。
此時可以考慮從外部檢查應用程序的運行狀況:
- Kubemetes可以通過存活探針(liveness probe)檢查容器是否還在運行;
- 通過就緒探針(readiness probe)保證只有準備好了請求的Pod才能接收客戶端請求。
二、LivenessProbe
1. 概念
Kubemetes可以通過存活探針(liveness probe)檢查容器是否還在運行。可以爲pod中的每個容器單獨指定存活探針。如果探測失敗,Kubemetes將定期執行探針並重新啓動容器。
Kubernetes 支持三種方式來執行探針:
- exec:在容器中執行一個命令,如果命令退出碼返回0則表示探測成功,否則表示失敗
- tcpSocket:對指定的容IP及端口執行一個TCP檢查,如果端口是開放的則表示探測成功,否則表示失敗
- httpGet:對指定的容器IP、端口及路徑執行一個HTTP Get請求,如果返回的狀態碼在 [200,400)之間則表示探測成功,否則表示失敗
2. exec探針
exec類型的探針通過在目標容器中執行由用戶自定義的命令來判斷容器的監控狀態,若命令狀態返回值爲0則表示“成功”通過檢測,其他值則均爲“失敗”狀態。
2.1 創建liveness-exec.yaml
[root@master ~]# more liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness-exec
name: liveness-exec
spec:
restartPolicy: OnFailure
containers:
- name: liveness-exec
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 10; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command: ["test","-e","/tmp/healthy"]
initialDelaySeconds: 5 #探測延時時長,第一次探測前等待5秒,默認爲0
periodSeconds: 5 #每5秒執行一次liveness探測,默認值10秒,最小1秒
timeoutSeconds: 2 #超長時長,默認爲1s,最小值也爲1s
failureThreshold: 3 #處於成功狀態時,探測操作至少連續多少次的失敗才被視爲檢測不通過,默認爲3,最小爲1
[root@master ~]# kubectl apply -f liveness-exec.yaml
pod/liveness-exec created2.2 查看Pod
[root@master ~]# kubectl get po -o wide
[root@master ~]# kubectl describe po liveness-exec
pod運行正常,10秒內文件/tmp/healthy還存在,probe檢測正常。
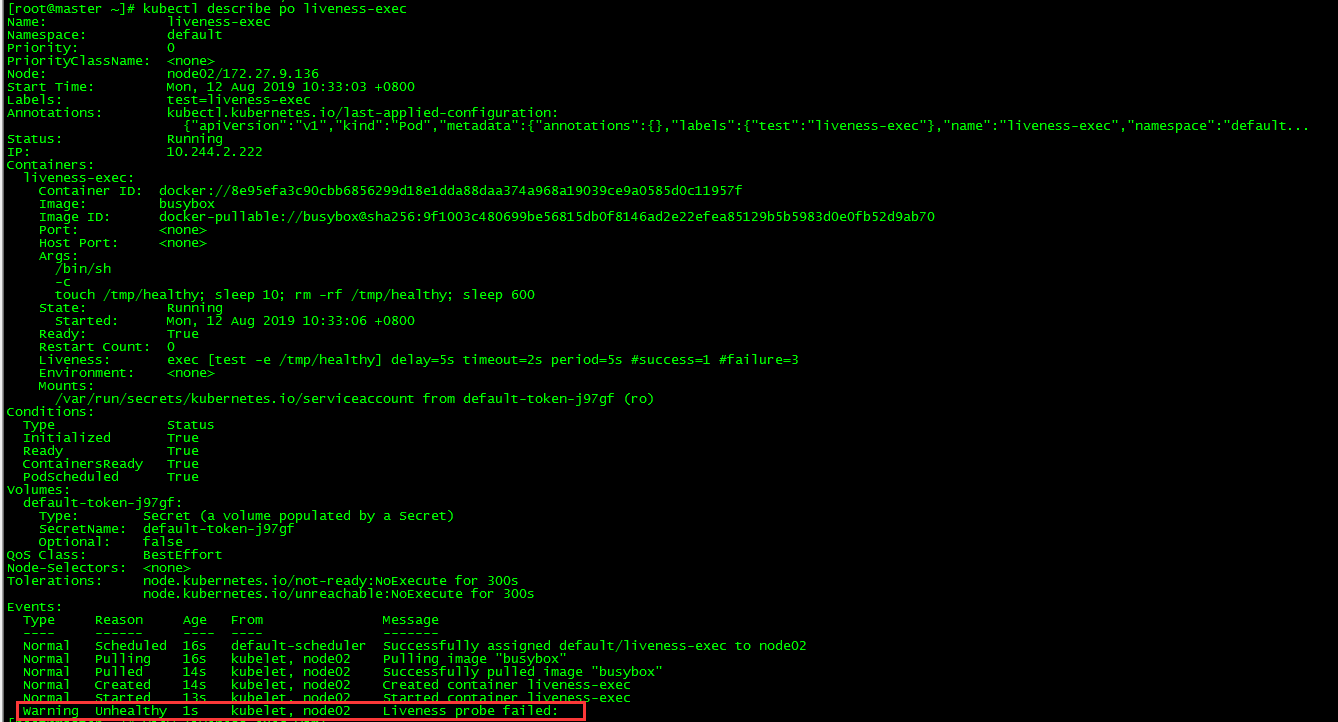
第15秒,probe再次檢測,由於文件被刪,檢測失敗,此後容器會進行多次重啓操作。

3. HTTP探針
基於HTTP的探測(HTTPGetAction)向目標容器發起一個HTTP請求,根據其相應碼進行結果判定,響應碼如2xx或3xx時表示檢測通過。
3.1 創建liveness-http.yaml
[root@master ~]# more liveness-http.yaml
apiVersion : v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness-http
image: nginx
ports:
- name: http
containerPort: 80
lifecycle:
postStart:
exec:
command: ["/bin/sh" ,"-c","echo liveness-http test > /usr/share/nginx/html/health"]
livenessProbe:
httpGet:
path: /health
port: http
scheme: HTTP
[root@master ~]# kubectl apply -f liveness-http.yaml
pod/liveness-http created3.2 查看Pod
[root@master ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
liveness-http 1/1 Running 0 5s 10.244.2.206 node02 <none> <none>
[root@master ~]# curl 10.244.2.206/health
liveness-http test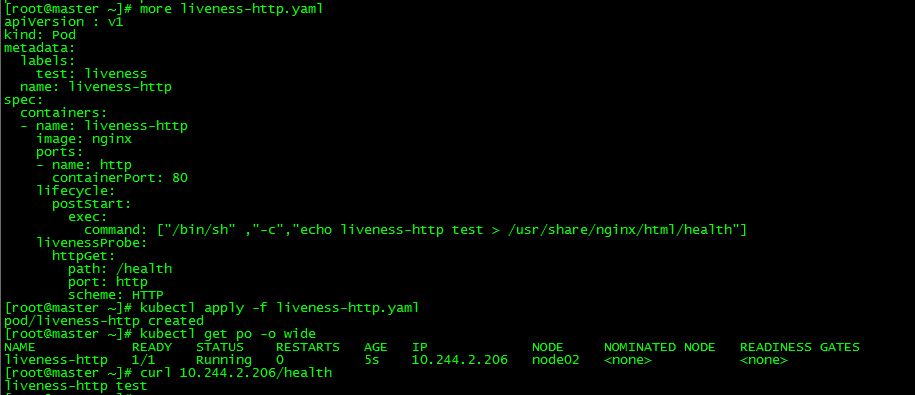
3.3 刪除測試頁面health
[root@master ~]# kubectl exec -it liveness-http rm /usr/share/nginx/html/health 
探測失敗,返回碼404,重啓容器。
4. TCP探針
基於TCP的存活性探測(TCPSocketAction)用於向容器的特定端口發起TCP請求並嘗試建立連接,連接成功即爲通過檢測。
4.1 創建liveness-tcp.yaml
```bash
[root@master ~]# more liveness-tcp.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-tcp
spec:
containers:
- name: liveness-tcp
image: nginx
ports:
- name: http
containerPort: 80
livenessProbe:
tcpSocket:
port: http
[root@master ~]# kubectl apply -f liveness-tcp.yaml
pod/liveness-tcp created
[root@master ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
liveness-tcp 1/1 Running 0 4s 10.244.2.217 node02 <none> <none>
[root@master ~]# curl 10.244.2.217:80
4.2 修改默認端口
[root@master ~]# kubectl exec -it liveness-tcp -- sed -i 's/^ *listen 80/ listen 81/g' /etc/nginx/conf.d/default.conf如果kubectl exec在容器內執行命令時如果帶參數則需加上'--'
加載nginx
[root@master ~]# kubectl exec -it liveness-tcp -- nginx -s reload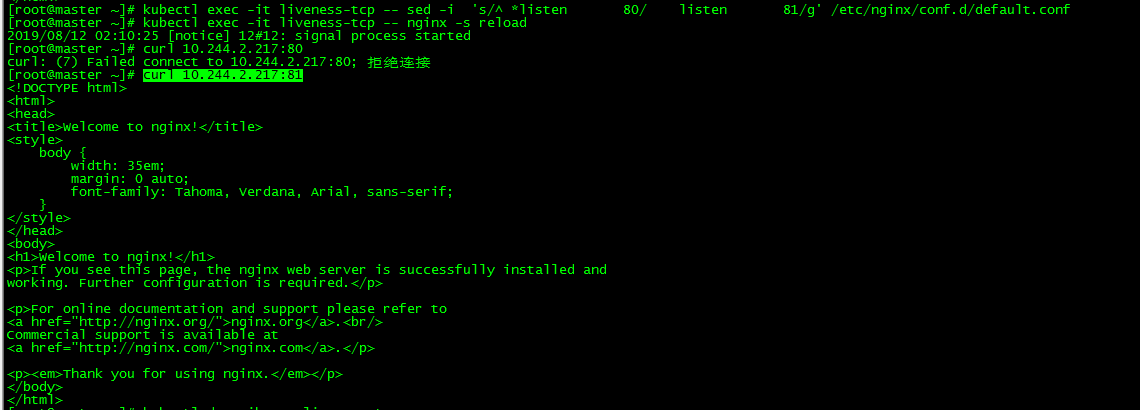
4.3 查看Pod
[root@master ~]# kubectl describe po liveness-tcp 
80是nginx的默認端口,開始發起TCP連接的端口也是80,默認端口改成81後連接報錯,容器重啓。
三、ReadinessProbe
1. 概念
用於容器的自定義準備狀態檢查。如果ReadinessProbe檢查失敗,Kubernetes會將該Pod從服務代理的分發後端去除,不再分發請求給該Pod。
2. readinessprobe使用場景
Pod對象啓動後,容器應用通常需要一段時間才能完成其初始化過程,例如加載配置或數據,甚至有些程序需要運行某類的預熱過程,若在此階段完成之前接入客戶端的請求,勢必會因爲等待太久而影響用戶體驗,這時就需要就緒探針。
如果沒有將就緒探針添加到pod中,它們幾乎會立即成爲服務端點。如果應用程序需要很長時間才能開始監聽傳入連接,則在服務啓動但尚未準備好接收傳入連接時,客戶端請求將被轉發到該pod。因此,客戶端會看到"連接被拒絕"類型的錯誤。
3. 機制
與存活探針機制相同,就緒探針也支持Exec、HTTP GET和TCP Socket三種探測方式,且各自的定義機制相同,將容器定義中的livenessProbe字段名替換爲readinessProbe即可定義出就緒探測的配置,這裏不再贅述。
4. 創建readiness-exec.yaml
本文以exec方式爲例實踐
[root@master ~]# more liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness-exec
name: liveness-exec
spec:
restartPolicy: OnFailure
containers:
- name: liveness-exec
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 10; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command: ["test","-e","/tmp/healthy"]
initialDelaySeconds: 5 #探測延時時長,第一次探測前等待5秒,默認爲0
periodSeconds: 5 #每5秒執行一次liveness探測,默認值10秒,最小1秒
timeoutSeconds: 2 #超長時長,默認爲1s,最小值也爲1s
failureThreshold: 3 #處於成功狀態時,探測操作至少連續多少次的失敗才被視爲檢測不通過,默認爲3,最小爲1
[root@master ~]# kubectl apply -f readiness-exec.yaml
pod/readiness-exec created5. 查看Pod
[root@master ~]# kubectl get po readiness-exec -w
NAME READY STATUS RESTARTS AGE
readiness-exec 0/1 ContainerCreating 0 2s
readiness-exec 0/1 Running 0 3s
readiness-exec 1/1 Running 0 9s
readiness-exec 0/1 Running 0 24s'-w'選項可以監視pod資源變動,剛開始儘管pod處於Running狀態,但知道就緒探測命令執行成功後pod資源才ready

剛開始處於'預熱'階段,pod爲running狀態但不可用;當10秒後(initialDelaySeconds + periodSeconds),readinessprobe開始第一次探測,成功後pod處於ready狀態,45秒後(sleep30 + periodSeconds * failureThreshold)探測失敗,pod再次爲running但not ready狀態。
6. 與livenessprobe區別
- 如果容器中的進程能夠在遇到問題或不健康的情況下自行崩潰,則不一定需要存活探針; kubelet 將根據Pod的restartPolicy自動執行正確的操作。
- 如果您希望容器在探測失敗時被殺死並重新啓動,那麼請指定一個存活探針,並指定restartPolicy爲Always或OnFailure。
- 如果要僅在探測成功時纔開始向 Pod 發送流量,請指定就緒探針。在這種情況下,就緒探針可能與存活探針相同,但是spec中的就緒探針的存在意味着Pod將在沒有接收到任何流量的情況下啓動,並且只有在探針探測成功後纔開始接收流量。
- 兩種探測的配置方法完全一樣,支持的配置參數也一樣,既可單獨探測又可結合者一起執行。
本文所有腳本和配置文件已上傳github:https://github.com/loong576/k8s-liveness-and-readiness-probe.git