




事故背景:
物理機(192.168.200.10)安裝了KVM虛擬化,虛擬化的機器無法正常啓動,進入vnc界面查看到linux系統在讀取硬盤的時候需要30s-60s左右,正常啓動的話幾秒鐘即可。懷疑是和硬盤有關係。解決思路:
1、 查看當前系統硬盤負載情況
2、 查看哪個進程佔用了硬盤IO
步驟1、使用iostat –x 1 iostat還有一個比較常用的選項-x,該選項將用於顯示和io相關的擴展數據。如圖
rrqm/s:每秒這個設備相關的讀取請求有多少被Merge了(當系統調用需要讀取數據的時候,VFS將請求發到各個FS,如果FS發現不同的讀取請求讀取的是相同Block的數據,FS會將這個請求合併Merge);wrqm/s:每秒這個設備相關的寫入請求有多少被Merge了。
rsec/s:每秒讀取的扇區數;
wsec/:每秒寫入的扇區數。
rKB/s:The number of read requests that were issued to the device per second;
wKB/s:The number of write requests that were issued to the device per second;
avgrq-sz 平均請求扇區的大小
avgqu-sz 是平均請求隊列的長度。毫無疑問,隊列長度越短越好。
await: 每一個IO請求的處理的平均時間(單位是微秒毫秒)。這裏可以理解爲IO的響應時間,一般地系統IO響應時間應該低於5ms,如果大於10ms就比較大了。
這個時間包括了隊列時間和服務時間,也就是說,一般情況下,await大於svctm,它們的差值越小,則說明隊列時間越短,反之差值越大,隊列時間越長,說明系統出了問題。
svctm 表示平均每次設備I/O操作的服務時間(以毫秒爲單位)。如果svctm的值與await很接近,表示幾乎沒有I/O等待,磁盤性能很好,如果await的值遠高於svctm的值,則表示I/O隊列等待太長, 系統上運行的應用程序將變慢。
%util: 在統計時間內所有處理IO時間,除以總共統計時間。例如,如果統計間隔1秒,該設備有0.8秒在處理IO,而0.2秒閒置,那麼該設備的%util = 0.8/1 = 80%,所以該參數暗示了設備的繁忙程度
。一般地,如果該參數是100%表示設備已經接近滿負荷運行了(當然如果是多磁盤,即使%util是100%,因爲磁盤的併發能力,所以磁盤使用未必就到了瓶頸)。
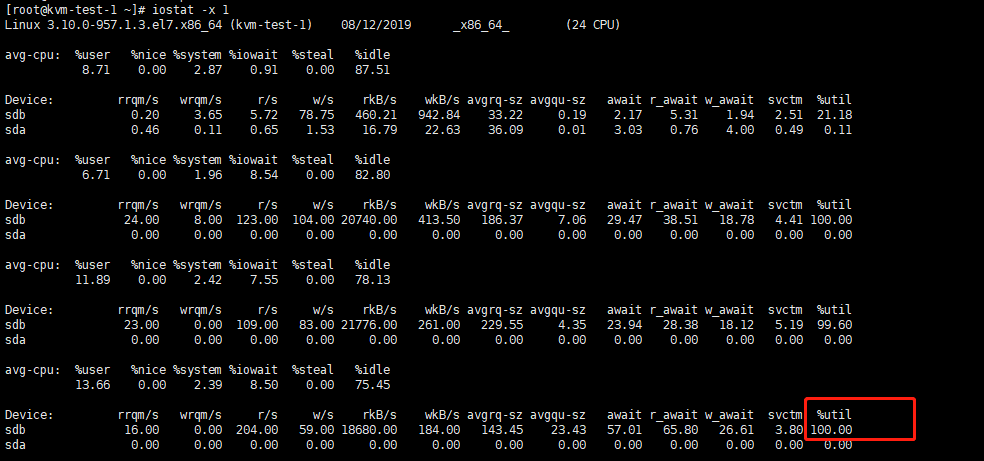
由此得出:硬盤的負載已達到瓶頸;
步驟2、使用iotop,類似top命令。查看哪個進程佔用了硬盤IO,如圖:
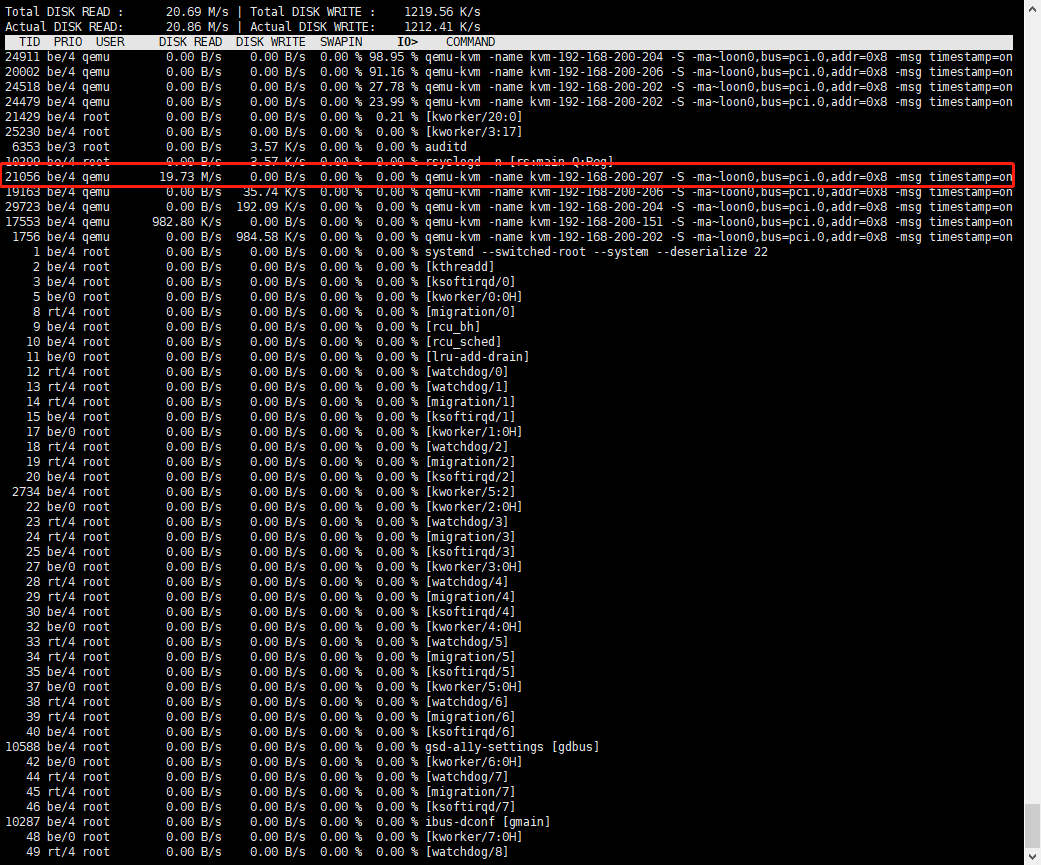
得出結論,有臺虛擬機(192.168.200.207)佔用了硬盤IO,將該機器關機之後得到解決