




大數據學習路線分享Hadoop階段的高可用配置,什麼是Hadoop的HA機制
Ha機制即Hadoop的高可用(7*24小時不中斷服務)
正式引入HA機制是從hadoop2.0開始,之前的版本中沒有HA機制
hadoop-ha嚴格來說應該分成各個組件的HA機制——HDFS的HA、YARN的HA
HDFS的HA機制詳解
HDFS 的HA主要是通過雙namenode協調工作實現
雙namenode協調工作的要點:
A、元數據管理方式需要改變:
內存中各自保存一份元數據
Edits日誌只能有一份,只有Active狀態的namenode節點可以做寫操作
兩個namenode都可以讀取edits
共享的edits放在一個共享存儲中管理(qjournal和NFS兩個主流實現)
B、需要一個狀態管理功能模塊
實現了一個zkfailover,常駐在每一個namenode所在的節點
每一個zkfailover負責監控自己所在namenode節點,利用zk進行狀態標識
當需要進行狀態切換時,由zkfailover來負責切換
切換時需要防止brain split腦裂現象的發生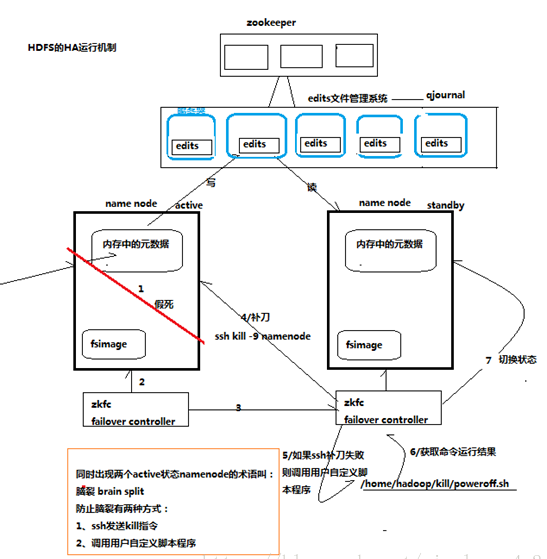
Namenode的運行原理
兩臺服務器上都存在一個namenode ,其中一臺Namenode 處於active狀態,一臺處於standby狀態,兩臺服務器數據共享,兩臺服務器各自存有一份元數據,但是edit數據只有一份,兩臺服務器只有處於active狀態的namenode服務器可以對edit進行寫操作,另一臺服務器只能對edit進行讀操作,而共享的edit放到一個共享存儲中進行管理。共享存儲由文件管理系統qjournal和NFS來實現。
而兩臺服務器的active standby狀態如何管理,則需要一個管理模塊:ZKFC (zookeeper failover controller) 來管理。每一個zkfc負責監控自己所在namenode節點,利用zk進行狀態標識。當需要進行狀態切換時,由zkfailover來負責切換
切換時需要防止brain split腦裂現象的發生。
什麼是腦裂現象
腦裂現象就是兩臺namenode都處於active狀態,產生衝突,這就是腦裂。Hadoop的高可用配置要注意解決腦裂狀態。
腦裂狀態如何產生
當一臺active狀態的namenode服務器處於假死狀態,那麼另一臺namenode服務器的zkfc收到信息,把屬於他的namenode狀態改變爲active狀態,第一臺處於假死狀態的namdenode又醒過來,就會產生腦裂。
腦裂如何解決
第二臺namenode的zkfc此時就會一不做二不休,把第一臺處於假死狀態的namenode殺掉 運用ssh kill -9 namenode ,直接殺掉第一臺服務器的namenode進行補刀,如果補刀不成功的話,zkfc進入第一臺服務器,直接調用用戶的自定義腳本程序 /home/Hadoop/kill/poweroff.sh 殺-掉假-死的namenode。