




來源:https://groups.google.com/forum/#!topic/mongodb-user/BpgEaRqrKsA
【摘要】
Mongodb 的 BSON 存儲格式靈活多樣,有助於 MongoDB 的入門學習。有集算器 SPL 語言支持後,Mongodb 能實現像數據 SQL 那樣的方便查詢。
複製摘要
MongoDB文檔的存儲格式是BSON,一種類JSON的二進制形式的存儲格式。如果熟悉JSON格式,將非常有助於MongoDB的入門學習,不過和JSON一樣, BSON結構靈活,組織形式多樣,在提供了強大的數據表達能力的同時,要實現類似數據SQL那樣的方便查詢卻變成了一件非常不容易的事。
針對這個問題,集算器SPL語言內置了豐富的接口,能夠極大地方便用戶使用Mongodb。 下面就用合併內嵌子文檔結構的例子來舉例說明。
Collection C1的部分數據如下:
| { "_id" : ObjectId("55014006e4b0333c9531043e"),, "acls" : { "append" : { "users" : [ObjectId("54f5bfb0336a15084785c393") ], "groups" : [ ] }, "edit" : { "groups" : [ ], "users" : [ ObjectId("54f5bfb0336a15084785c392") ] }, "fullControl" : { "users" : [ ], "groups" : [ ] }, "read" : { "users" : [ ObjectId("54f5bfb0336a15084785c392"), ObjectId("54f5bfb0336a15084785c398")], "groups" : [ ] } }, name: "ABC" } { "_id" : ObjectId("55014006e4b0333c9531043f"), "acls" : { "append" : { "users" : [ObjectId("54f5bfb0336a15084785c365") ], "groups" : [ ] }, "edit" : { "groups" : [ ], "users" : [ ObjectId("54f5bfb0336a15084785c392") ] }, "fullControl" : { "users" : [ ], "groups" : [ ] }, "read" : { "users" : [ObjectId("54f5bfb0336a15084785c392"), ObjectId("54f5bfb0336a15084785c370")], "groups" : [ ] } }, name: "ABC" } |
要求按name分組,每組數據是相同的name對應的子文檔中的users字段,且數據不能重複。最後的計算結果類似下面這樣:
| { result : [ { _id: "ABC", readUsers : [ ObjectId("54f5bfb0336a15084785c393"), ObjectId("54f5bfb0336a15084785c392"), ObjectId("54f5bfb0336a15084785c398"), ObjectId("54f5bfb0336a15084785c365"), ObjectId("54f5bfb0336a15084785c370") ] } ] } |
使用集算器SPL的代碼如下:
| A | B | ||
| 1 | =mongo_open("mongodb://localhost:27017/local?user=test&password=test") | ||
| 2 | =mongo_shell(A1,"c1.find(,{_id:0};{name:1})") | ||
| 3 | for A2;name | =A3.(acls.read.users|acls.append.users|acls.edit.users|acls.fullControl.users) | |
| 4 | =B3.new(A3.name:_id,B3.union().id():readUsers) | ||
| 5 | =@|B4.group@1(~._id,~.readUsers) | ||
| 6 | =mongo_close(A1) | ||
A1:連接MongoDB,連接字格式爲mongo://ip:port/db?arg=value&…
A2: 使用find函數從MongoDB中取數並排序,形成遊標:collectoin是c1,過濾條件是空,取出_id之外的所有字段,並按name排序。
A3: 循環從遊標讀數,每次取name字段相同的一組文檔。A3循環的作用範圍是縮進的B3到B5,在這個作用範圍內可以用A3來引用循環變量。
B3:取出本組文檔的所有users字段,如下:
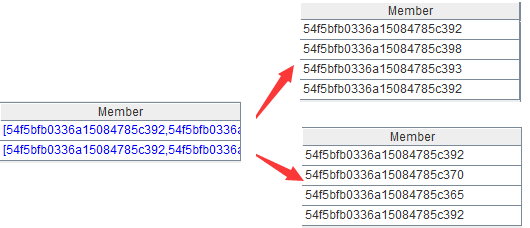
B4:合併本組各文檔的users。
B5:將B4去除重複記錄後不斷地追加到B5中,其中group@1實現去重處理。B5如下:
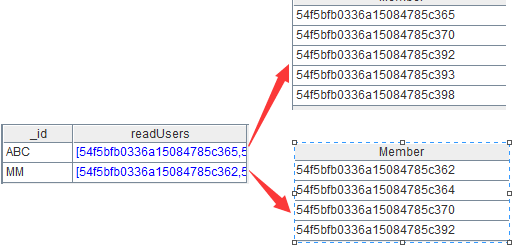
B5就是本案例的計算目標。如果計算結果太多導致內存放不下,可以在B5中用函數export@j將B4轉爲json串,不斷地追加到文本文件中。
A6:關閉mongodb。
MongoDB豐富靈活的存儲結構輕量化、高效性,讓人印象深刻,而集算器能與它天然融合,提高使用效率,擴展了應用空間。