




一、簡介
Spark 於 2009 年誕生於加州大學伯克利分校 AMPLab,2013 年被捐贈給 Apache 軟件基金會,2014 年 2 月成爲 Apache 的頂級項目。相對於 MapReduce 的批處理計算,Spark 可以帶來上百倍的性能提升,因此它成爲繼 MapReduce 之後,最爲廣泛使用的分佈式計算框架。
二、特點
Apache Spark 具有以下特點:
- 使用先進的 DAG 調度程序,查詢優化器和物理執行引擎,以實現性能上的保證;
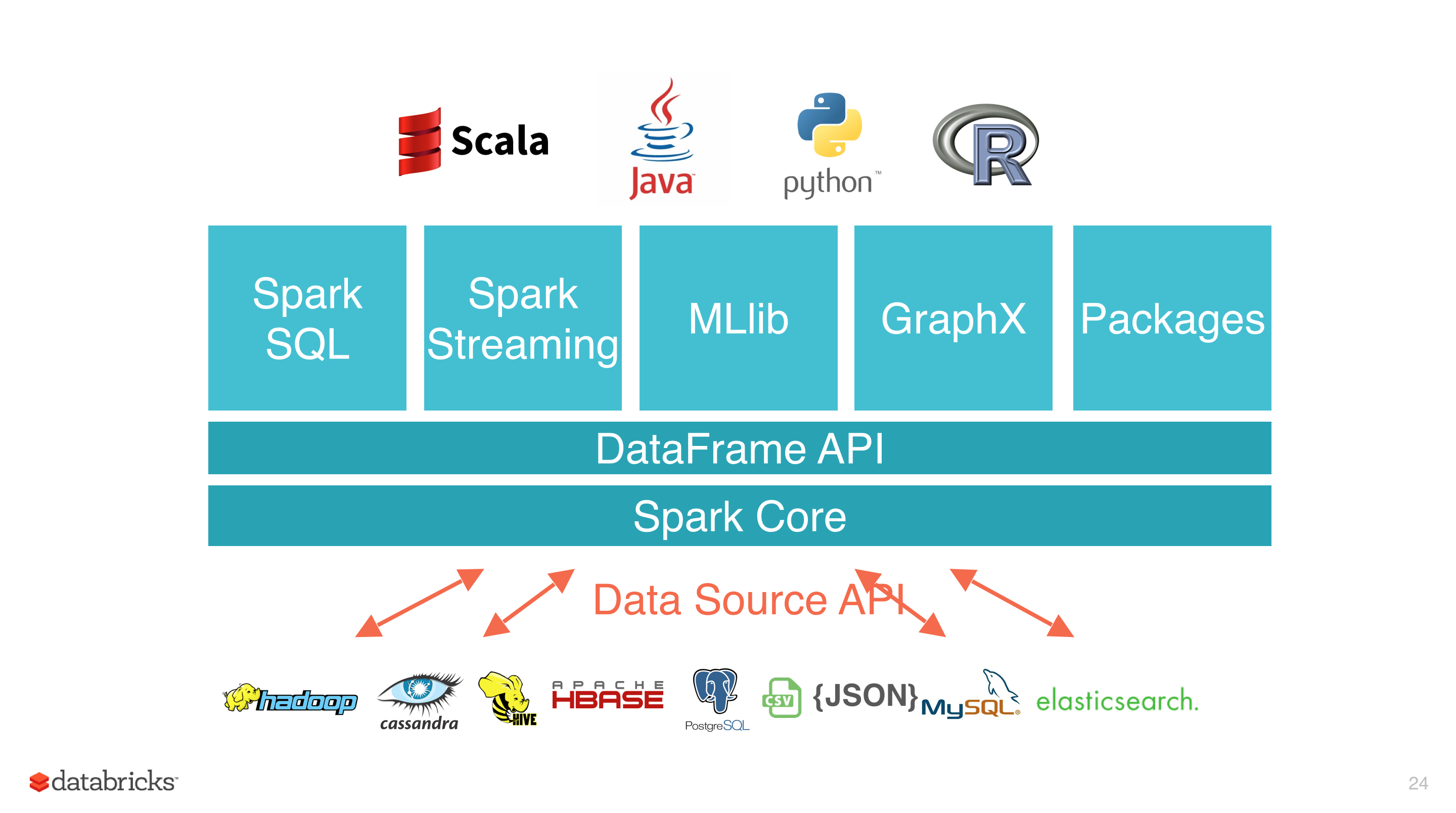
- 多語言支持,目前支持的有 Java,Scala,Python 和 R;
- 提供了 80 多個高級 API,可以輕鬆地構建應用程序;
- 支持批處理,流處理和複雜的業務分析;
- 豐富的類庫支持:包括 SQL,MLlib,GraphX 和 Spark Streaming 等庫,並且可以將它們無縫地進行組合;
- 豐富的部署模式:支持本地模式和自帶的集羣模式,也支持在 Hadoop,Mesos,Kubernetes 上運行;
- 多數據源支持:支持訪問 HDFS,Alluxio,Cassandra,HBase,Hive 以及數百個其他數據源中的數據。
三、集羣架構
| Term(術語) | Meaning(含義) |
|---|---|
| Application | Spark 應用程序,由集羣上的一個 Driver 節點和多個 Executor 節點組成。 |
| Driver program | 主運用程序,該進程運行應用的 main() 方法並且創建 SparkContext |
| Cluster manager | 集羣資源管理器(例如,Standlone Manager,Mesos,YARN) |
| Worker node | 執行計算任務的工作節點 |
| Executor | 位於工作節點上的應用進程,負責執行計算任務並且將輸出數據保存到內存或者磁盤中 |
| Task | 被髮送到 Executor 中的工作單元 |

執行過程:
- 用戶程序創建 SparkContext 後,它會連接到集羣資源管理器,集羣資源管理器會爲用戶程序分配計算資源,並啓動 Executor;
- Dirver 將計算程序劃分爲不同的執行階段和多個 Task,之後將 Task 發送給 Executor;
- Executor 負責執行 Task,並將執行狀態彙報給 Driver,同時也會將當前節點資源的使用情況彙報給集羣資源管理器。
四、核心組件
Spark 基於 Spark Core 擴展了四個核心組件,分別用於滿足不同領域的計算需求。
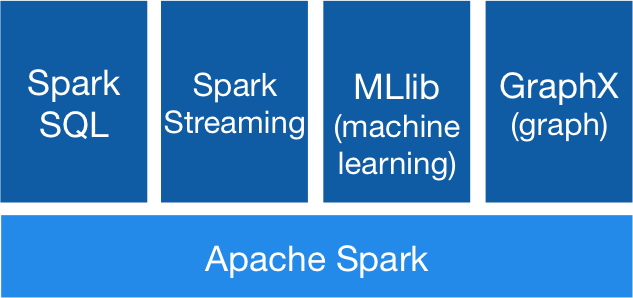
3.1 Spark SQL
Spark SQL 主要用於結構化數據的處理。其具有以下特點:
- 能夠將 SQL 查詢與 Spark 程序無縫混合,允許您使用 SQL 或 DataFrame API 對結構化數據進行查詢;
- 支持多種數據源,包括 Hive,Avro,Parquet,ORC,JSON 和 JDBC;
- 支持 HiveQL 語法以及用戶自定義函數 (UDF),允許你訪問現有的 Hive 倉庫;
- 支持標準的 JDBC 和 ODBC 連接;
- 支持優化器,列式存儲和代碼生成等特性,以提高查詢效率。
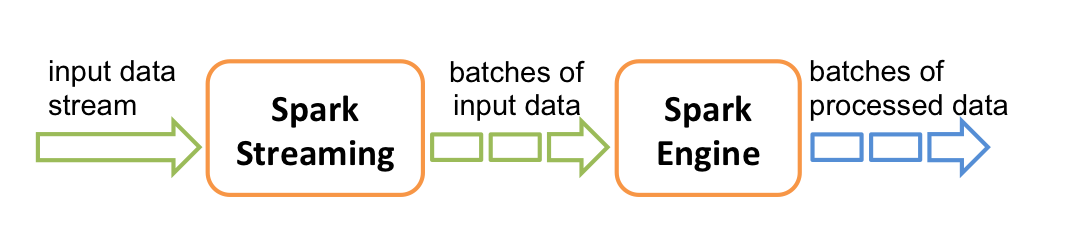
3.2 Spark Streaming
Spark Streaming 主要用於快速構建可擴展,高吞吐量,高容錯的流處理程序。支持從 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 讀取數據,並進行處理。

Spark Streaming 的本質是微批處理,它將數據流進行極小粒度的拆分,拆分爲多個批處理,從而達到接近於流處理的效果。
3.3 MLlib
MLlib 是 Spark 的機器學習庫。其設計目標是使得機器學習變得簡單且可擴展。它提供了以下工具:
- 常見的機器學習算法:如分類,迴歸,聚類和協同過濾;
- 特徵化:特徵提取,轉換,降維和選擇;
- 管道:用於構建,評估和調整 ML 管道的工具;
- 持久性:保存和加載算法,模型,管道數據;
- 實用工具:線性代數,統計,數據處理等。
3.4 Graphx
GraphX 是 Spark 中用於圖形計算和圖形並行計算的新組件。在高層次上,GraphX 通過引入一個新的圖形抽象來擴展 RDD(一種具有附加到每個頂點和邊緣的屬性的定向多重圖形)。爲了支持圖計算,GraphX 提供了一組基本運算符(如: subgraph,joinVertices 和 aggregateMessages)以及優化後的 Pregel API。此外,GraphX 還包括越來越多的圖形算法和構建器,以簡化圖形分析任務。
更多大數據系列文章可以參見 GitHub 開源項目: 大數據入門指南