




彈性式數據集RDDs
一、RDD簡介
RDD 全稱爲 Resilient Distributed Datasets,是 Spark 最基本的數據抽象,它是隻讀的、分區記錄的集合,支持並行操作,可以由外部數據集或其他 RDD 轉換而來,它具有以下特性:
- 一個 RDD 由一個或者多個分區(Partitions)組成。對於 RDD 來說,每個分區會被一個計算任務所處理,用戶可以在創建 RDD 時指定其分區個數,如果沒有指定,則默認採用程序所分配到的 CPU 的核心數;
- RDD 擁有一個用於計算分區的函數 compute;
- RDD 會保存彼此間的依賴關係,RDD 的每次轉換都會生成一個新的依賴關係,這種 RDD 之間的依賴關係就像流水線一樣。在部分分區數據丟失後,可以通過這種依賴關係重新計算丟失的分區數據,而不是對 RDD 的所有分區進行重新計算;
- Key-Value 型的 RDD 還擁有 Partitioner(分區器),用於決定數據被存儲在哪個分區中,目前 Spark 中支持 HashPartitioner(按照哈希分區) 和 RangeParationer(按照範圍進行分區);
- 一個優先位置列表 (可選),用於存儲每個分區的優先位置 (prefered location)。對於一個 HDFS 文件來說,這個列表保存的就是每個分區所在的塊的位置,按照“移動數據不如移動計算“的理念,Spark 在進行任務調度的時候,會儘可能的將計算任務分配到其所要處理數據塊的存儲位置。
RDD[T] 抽象類的部分相關代碼如下:
// 由子類實現以計算給定分區
def compute(split: Partition, context: TaskContext): Iterator[T]
// 獲取所有分區
protected def getPartitions: Array[Partition]
// 獲取所有依賴關係
protected def getDependencies: Seq[Dependency[_]] = deps
// 獲取優先位置列表
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
// 分區器 由子類重寫以指定它們的分區方式
@transient val partitioner: Option[Partitioner] = None二、創建RDD
RDD 有兩種創建方式,分別介紹如下:
2.1 由現有集合創建
這裏使用 spark-shell 進行測試,啓動命令如下:
spark-shell --master local[4]啓動 spark-shell 後,程序會自動創建應用上下文,相當於執行了下面的 Scala 語句:
val conf = new SparkConf().setAppName("Spark shell").setMaster("local[4]")
val sc = new SparkContext(conf)由現有集合創建 RDD,你可以在創建時指定其分區個數,如果沒有指定,則採用程序所分配到的 CPU 的核心數:
val data = Array(1, 2, 3, 4, 5)
// 由現有集合創建 RDD,默認分區數爲程序所分配到的 CPU 的核心數
val dataRDD = sc.parallelize(data)
// 查看分區數
dataRDD.getNumPartitions
// 明確指定分區數
val dataRDD = sc.parallelize(data,2)執行結果如下:

2.2 引用外部存儲系統中的數據集
引用外部存儲系統中的數據集,例如本地文件系統,HDFS,HBase 或支持 Hadoop InputFormat 的任何數據源。
val fileRDD = sc.textFile("/usr/file/emp.txt")
// 獲取第一行文本
fileRDD.take(1)使用外部存儲系統時需要注意以下兩點:
- 如果在集羣環境下從本地文件系統讀取數據,則要求該文件必須在集羣中所有機器上都存在,且路徑相同;
- 支持目錄路徑,支持壓縮文件,支持使用通配符。
2.3 textFile & wholeTextFiles
兩者都可以用來讀取外部文件,但是返回格式是不同的:
- textFile:其返回格式是
RDD[String],返回的是就是文件內容,RDD 中每一個元素對應一行數據; - wholeTextFiles:其返回格式是
RDD[(String, String)],元組中第一個參數是文件路徑,第二個參數是文件內容; - 兩者都提供第二個參數來控制最小分區數;
- 從 HDFS 上讀取文件時,Spark 會爲每個塊創建一個分區。
def textFile(path: String,minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {...}
def wholeTextFiles(path: String,minPartitions: Int = defaultMinPartitions): RDD[(String, String)]={..}三、操作RDD
RDD 支持兩種類型的操作:transformations(轉換,從現有數據集創建新數據集)和 actions(在數據集上運行計算後將值返回到驅動程序)。RDD 中的所有轉換操作都是惰性的,它們只是記住這些轉換操作,但不會立即執行,只有遇到 action 操作後纔會真正的進行計算,這類似於函數式編程中的惰性求值。
val list = List(1, 2, 3)
// map 是一個 transformations 操作,而 foreach 是一個 actions 操作
sc.parallelize(list).map(_ * 10).foreach(println)
// 輸出: 10 20 30四、緩存RDD
4.1 緩存級別
Spark 速度非常快的一個原因是 RDD 支持緩存。成功緩存後,如果之後的操作使用到了該數據集,則直接從緩存中獲取。雖然緩存也有丟失的風險,但是由於 RDD 之間的依賴關係,如果某個分區的緩存數據丟失,只需要重新計算該分區即可。
Spark 支持多種緩存級別 :
| Storage Level<br/>(存儲級別) | Meaning(含義) |
|---|---|
MEMORY_ONLY |
默認的緩存級別,將 RDD 以反序列化的 Java 對象的形式存儲在 JVM 中。如果內存空間不夠,則部分分區數據將不再緩存。 |
MEMORY_AND_DISK |
將 RDD 以反序列化的 Java 對象的形式存儲 JVM 中。如果內存空間不夠,將未緩存的分區數據存儲到磁盤,在需要使用這些分區時從磁盤讀取。 |
MEMORY_ONLY_SER<br/> |
將 RDD 以序列化的 Java 對象的形式進行存儲(每個分區爲一個 byte 數組)。這種方式比反序列化對象節省存儲空間,但在讀取時會增加 CPU 的計算負擔。僅支持 Java 和 Scala 。 |
MEMORY_AND_DISK_SER<br/> |
類似於 MEMORY_ONLY_SER,但是溢出的分區數據會存儲到磁盤,而不是在用到它們時重新計算。僅支持 Java 和 Scala。 |
DISK_ONLY |
只在磁盤上緩存 RDD |
MEMORY_ONLY_2, <br/>MEMORY_AND_DISK_2, etc |
與上面的對應級別功能相同,但是會爲每個分區在集羣中的兩個節點上建立副本。 |
OFF_HEAP |
與 MEMORY_ONLY_SER 類似,但將數據存儲在堆外內存中。這需要啓用堆外內存。 |
啓動堆外內存需要配置兩個參數:
- spark.memory.offHeap.enabled :是否開啓堆外內存,默認值爲 false,需要設置爲 true;
- spark.memory.offHeap.size : 堆外內存空間的大小,默認值爲 0,需要設置爲正值。
4.2 使用緩存
緩存數據的方法有兩個:persist 和 cache 。cache 內部調用的也是 persist,它是 persist 的特殊化形式,等價於 persist(StorageLevel.MEMORY_ONLY)。示例如下:
// 所有存儲級別均定義在 StorageLevel 對象中
fileRDD.persist(StorageLevel.MEMORY_AND_DISK)
fileRDD.cache()4.3 移除緩存
Spark 會自動監視每個節點上的緩存使用情況,並按照最近最少使用(LRU)的規則刪除舊數據分區。當然,你也可以使用 RDD.unpersist() 方法進行手動刪除。
五、理解shuffle
5.1 shuffle介紹
在 Spark 中,一個任務對應一個分區,通常不會跨分區操作數據。但如果遇到 reduceByKey 等操作,Spark 必須從所有分區讀取數據,並查找所有鍵的所有值,然後彙總在一起以計算每個鍵的最終結果 ,這稱爲 Shuffle。
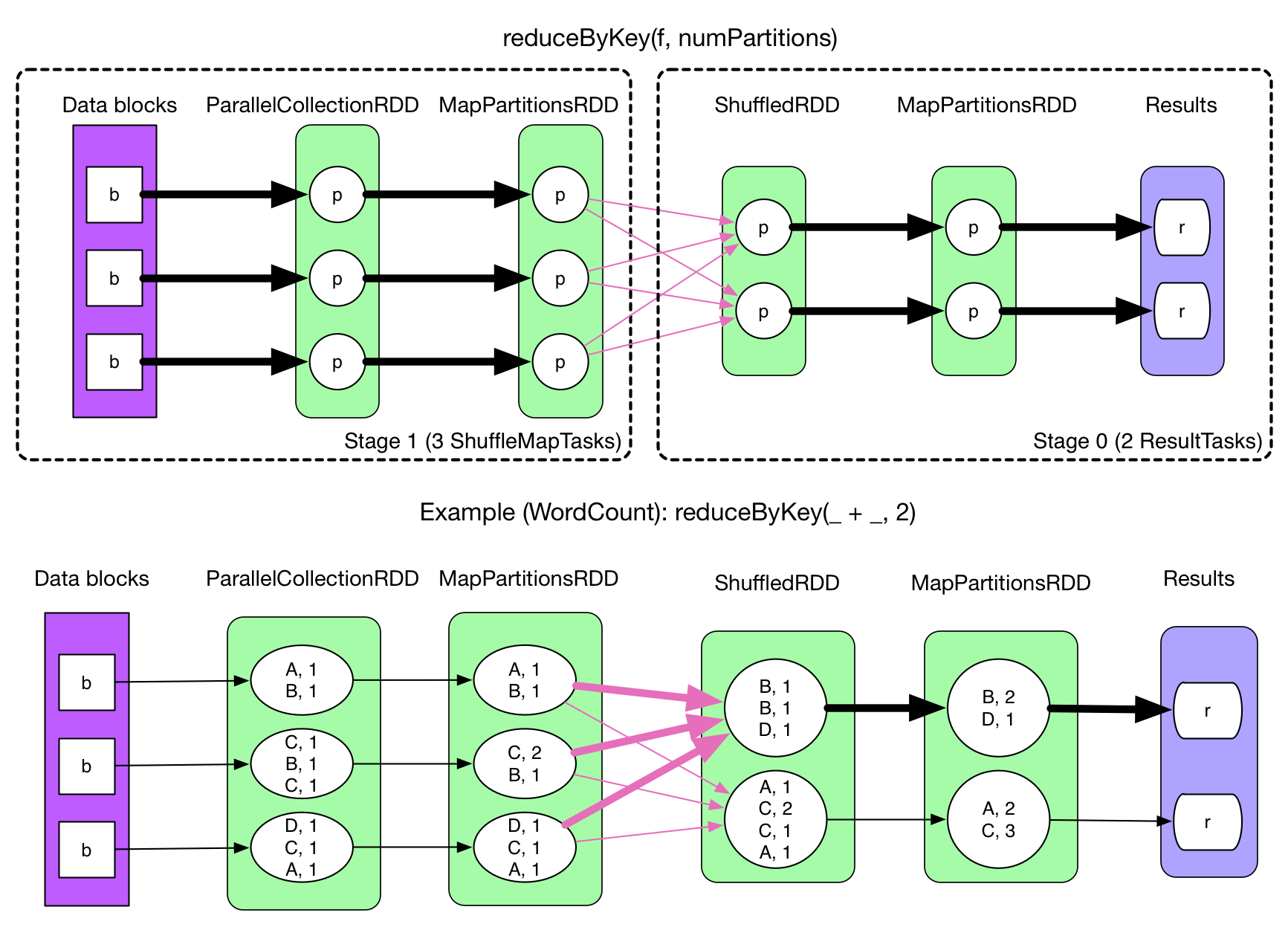
5.2 Shuffle的影響
Shuffle 是一項昂貴的操作,因爲它通常會跨節點操作數據,這會涉及磁盤 I/O,網絡 I/O,和數據序列化。某些 Shuffle 操作還會消耗大量的堆內存,因爲它們使用堆內存來臨時存儲需要網絡傳輸的數據。Shuffle 還會在磁盤上生成大量中間文件,從 Spark 1.3 開始,這些文件將被保留,直到相應的 RDD 不再使用並進行垃圾回收,這樣做是爲了避免在計算時重複創建 Shuffle 文件。如果應用程序長期保留對這些 RDD 的引用,則垃圾回收可能在很長一段時間後纔會發生,這意味着長時間運行的 Spark 作業可能會佔用大量磁盤空間,通常可以使用 spark.local.dir 參數來指定這些臨時文件的存儲目錄。
5.3 導致Shuffle的操作
由於 Shuffle 操作對性能的影響比較大,所以需要特別注意使用,以下操作都會導致 Shuffle:
- 涉及到重新分區操作: 如
repartition和coalesce; - 所有涉及到 ByKey 的操作:如
groupByKey和reduceByKey,但countByKey除外; - 聯結操作:如
cogroup和join。
五、寬依賴和窄依賴
RDD 和它的父 RDD(s) 之間的依賴關係分爲兩種不同的類型:
- 窄依賴 (narrow dependency):父 RDDs 的一個分區最多被子 RDDs 一個分區所依賴;
- 寬依賴 (wide dependency):父 RDDs 的一個分區可以被子 RDDs 的多個子分區所依賴。
如下圖,每一個方框表示一個 RDD,帶有顏色的矩形表示分區:

區分這兩種依賴是非常有用的:
- 首先,窄依賴允許在一個集羣節點上以流水線的方式(pipeline)對父分區數據進行計算,例如先執行 map 操作,然後執行 filter 操作。而寬依賴則需要計算好所有父分區的數據,然後再在節點之間進行 Shuffle,這與 MapReduce 類似。
- 窄依賴能夠更有效地進行數據恢復,因爲只需重新對丟失分區的父分區進行計算,且不同節點之間可以並行計算;而對於寬依賴而言,如果數據丟失,則需要對所有父分區數據進行計算並再次 Shuffle。
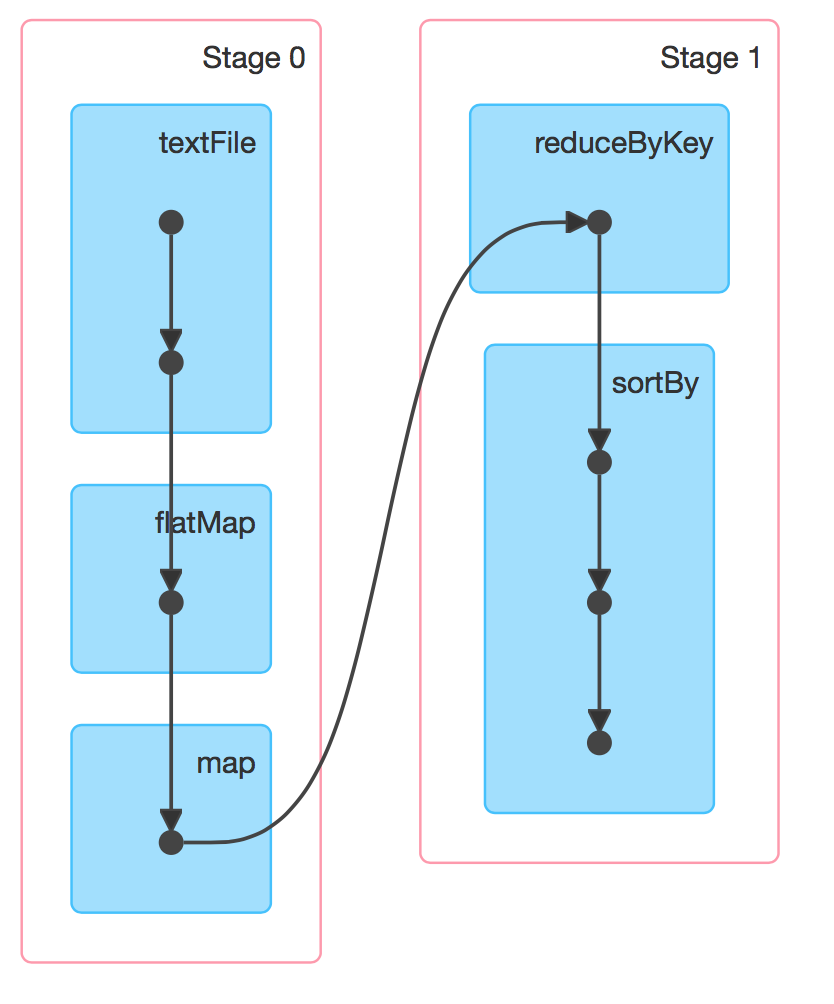
六、DAG的生成
RDD(s) 及其之間的依賴關係組成了 DAG(有向無環圖),DAG 定義了這些 RDD(s) 之間的 Lineage(血統) 關係,通過血統關係,如果一個 RDD 的部分或者全部計算結果丟失了,也可以重新進行計算。那麼 Spark 是如何根據 DAG 來生成計算任務呢?主要是根據依賴關係的不同將 DAG 劃分爲不同的計算階段 (Stage):
- 對於窄依賴,由於分區的依賴關係是確定的,其轉換操作可以在同一個線程執行,所以可以劃分到同一個執行階段;
- 對於寬依賴,由於 Shuffle 的存在,只能在父 RDD(s) 被 Shuffle 處理完成後,才能開始接下來的計算,因此遇到寬依賴就需要重新劃分階段。
參考資料
- 張安站 . Spark 技術內幕:深入解析 Spark 內核架構設計與實現原理[M] . 機械工業出版社 . 2015-09-01
- RDD Programming Guide
- RDD:基於內存的集羣計算容錯抽象
更多大數據系列文章可以參見 GitHub 開源項目: 大數據入門指南