




一、簡介
在 Spark 中,提供了兩種類型的共享變量:累加器 (accumulator) 與廣播變量 (broadcast variable):
- 累加器:用來對信息進行聚合,主要用於累計計數等場景;
- 廣播變量:主要用於在節點間高效分發大對象。
二、累加器
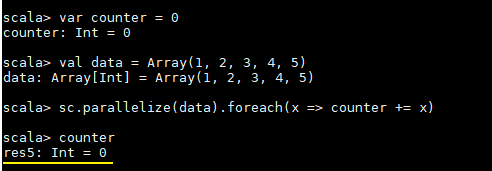
這裏先看一個具體的場景,對於正常的累計求和,如果在集羣模式中使用下面的代碼進行計算,會發現執行結果並非預期:
var counter = 0
val data = Array(1, 2, 3, 4, 5)
sc.parallelize(data).foreach(x => counter += x)
println(counter)counter 最後的結果是 0,導致這個問題的主要原因是閉包。
2.1 理解閉包
1. Scala 中閉包的概念
這裏先介紹一下 Scala 中關於閉包的概念:
var more = 10
val addMore = (x: Int) => x + more如上函數 addMore 中有兩個變量 x 和 more:
- x : 是一個綁定變量 (bound variable),因爲其是該函數的入參,在函數的上下文中有明確的定義;
- more : 是一個自由變量 (free variable),因爲函數字面量本生並沒有給 more 賦予任何含義。
按照定義:在創建函數時,如果需要捕獲自由變量,那麼包含指向被捕獲變量的引用的函數就被稱爲閉包函數。
2. Spark 中的閉包
在實際計算時,Spark 會將對 RDD 操作分解爲 Task,Task 運行在 Worker Node 上。在執行之前,Spark 會對任務進行閉包,如果閉包內涉及到自由變量,則程序會進行拷貝,並將副本變量放在閉包中,之後閉包被序列化併發送給每個執行者。因此,當在 foreach 函數中引用 counter 時,它將不再是 Driver 節點上的 counter,而是閉包中的副本 counter,默認情況下,副本 counter 更新後的值不會回傳到 Driver,所以 counter 的最終值仍然爲零。
需要注意的是:在 Local 模式下,有可能執行 foreach 的 Worker Node 與 Diver 處在相同的 JVM,並引用相同的原始 counter,這時候更新可能是正確的,但是在集羣模式下一定不正確。所以在遇到此類問題時應優先使用累加器。
累加器的原理實際上很簡單:就是將每個副本變量的最終值傳回 Driver,由 Driver 聚合後得到最終值,並更新原始變量。

2.2 使用累加器
SparkContext 中定義了所有創建累加器的方法,需要注意的是:被中橫線劃掉的累加器方法在 Spark 2.0.0 之後被標識爲廢棄。
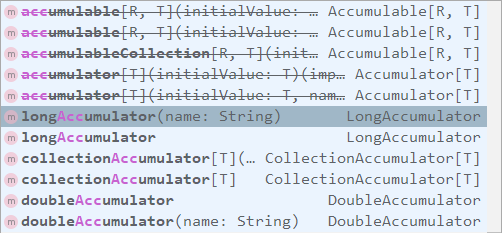
使用示例和執行結果分別如下:
val data = Array(1, 2, 3, 4, 5)
// 定義累加器
val accum = sc.longAccumulator("My Accumulator")
sc.parallelize(data).foreach(x => accum.add(x))
// 獲取累加器的值
accum.value
三、廣播變量
在上面介紹中閉包的過程中我們說道每個 Task 任務的閉包都會持有自由變量的副本,如果變量很大且 Task 任務很多的情況下,這必然會對網絡 IO 造成壓力,爲了解決這個情況,Spark 提供了廣播變量。
廣播變量的做法很簡單:就是不把副本變量分發到每個 Task 中,而是將其分發到每個 Executor,Executor 中的所有 Task 共享一個副本變量。
// 把一個數組定義爲一個廣播變量
val broadcastVar = sc.broadcast(Array(1, 2, 3, 4, 5))
// 之後用到該數組時應優先使用廣播變量,而不是原值
sc.parallelize(broadcastVar.value).map(_ * 10).collect()參考資料
更多大數據系列文章可以參見 GitHub 開源項目: 大數據入門指南