




前言
首先我們在瞭解java內存模型之前先看一下計算機內存模型,理解了計算機內存模型的話後面在看JMM就會簡單的多。

計算機內存
計算機是由CPU、主存、磁盤等組成的(簡單引出問題熬)我們都知道計算機執行程序的指令都是由CPU來執行的,執行的時候是要處理數據的,這些數據通常存儲在主存中。
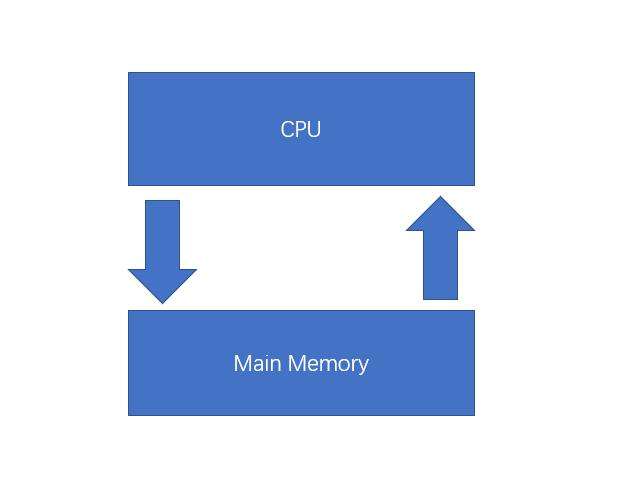
如圖所示,這時候問題來了,CPU的執行速度越來越快,然後內存倒是沒什麼進展,這樣的話CPU的讀寫操作就會非常耗時,效率不就很低了?
所以這個時候就出現了高速緩存(Cache)來解決這個問題,那麼緩存是什麼呢?緩存其實就是保存的數據備存,特點是快。所以這個時候程序的執行過程就變成了這個樣子:首先在運行的時候會把數據從主存中賦值一份放在緩存中,然後CPU在運算的時候就直接去緩存中讀寫數據,等執行結束後在把數據刷新到主存中。這樣一來就大大的提高了執行的速度。我們來看一下流程圖:
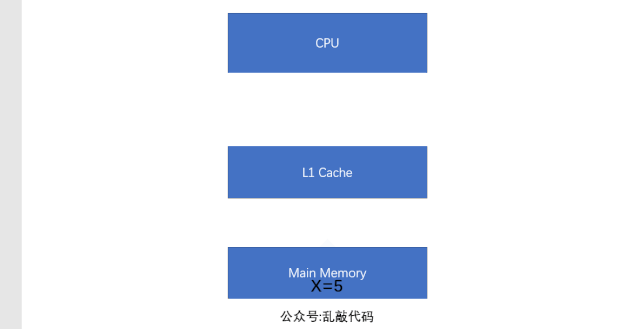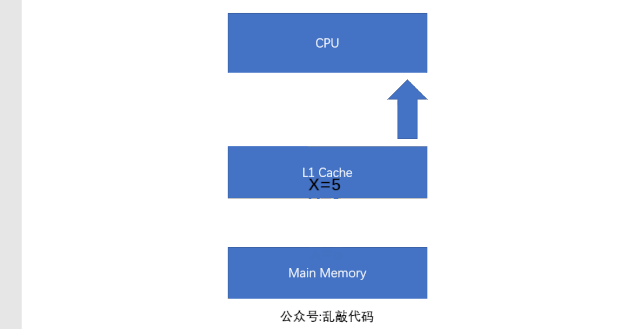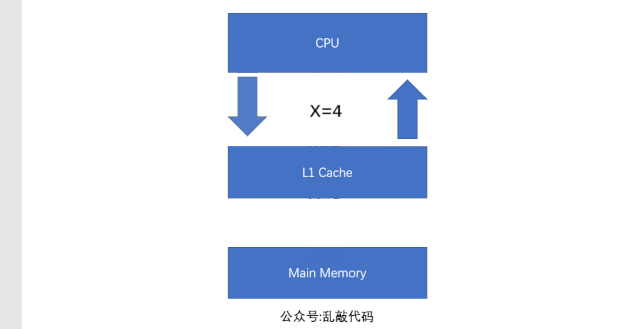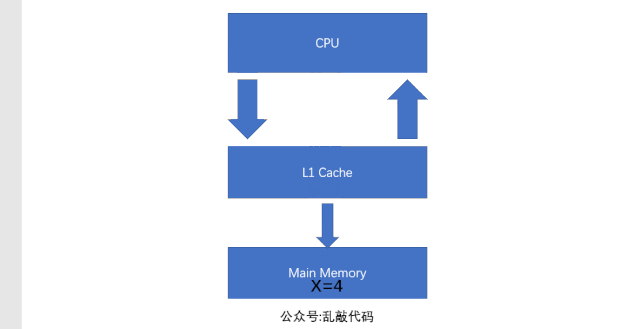
可以看出,運行的時候L1緩存先把數據從主存中讀取出來,然後CPU操作的數據是從緩存中讀取,當數據執行完畢,在從緩存中刷新到主存中。隨着CPU的執行能力越來越強,一層緩存已經滿足不了需求了,這時候就出現了2級緩存(L2Cache)3級緩存(L3Cache),每級緩存都存儲的是下一級緩存的一部分數據。
那麼當CPU需要數據的時候就會這樣執行:首先去一級緩存(L1Cache)查找,如果一級緩存沒有就去二級緩存(L2Cache)查找,二級緩存沒有就去三級緩存(L3Cache)查找,如果緩存中沒有,就去主存中查找。 那麼問題來了。
緩存一致性
現代計算機已經不是單個CPU,有多個CPU每個CPU還可能會有多核,單核CPU只有一套緩存分別就是上面所說的L1、L2、L3如圖所示:

如果CPU有多個核心的話,就是每個核心都有L1緩存或者有L2緩存,而共享L3緩存或者L2緩存。
我們來看一下結構圖:
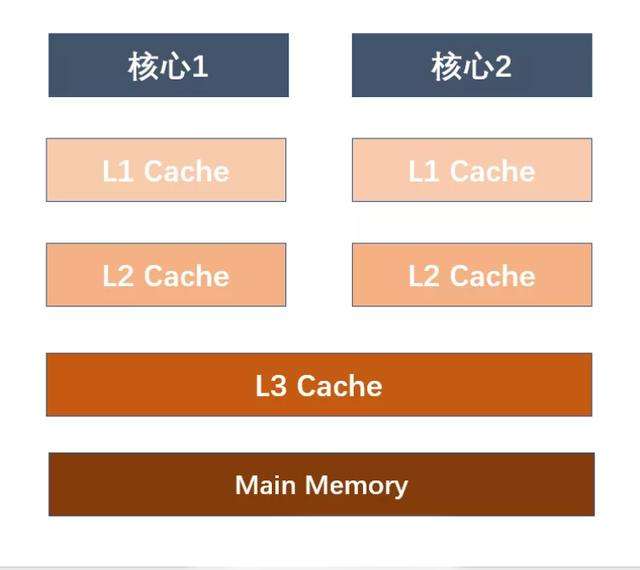
這個時候每個核心都有自己的高速緩存,它們又共享同一主存,就會造成緩存一致性的問題,在多線程同時訪問同一共享數據的情況下,每個線程都是操作自己緩存的數據副本,這個時候就會出現每個緩存中的共享數據存在不一致的情況。多個處理器運算任務都涉及同一塊主存,需要一種協議可以保障數據的一致性,這類協議有MSI、MESI、MOSI及Dragon Protocol等。
處理器優化
上面瞭解到提高CPU的效率就是在CPU和主存直接增加高速緩存,增加高速緩存會造成緩存不一致的問題,除了緩存不一致的問題,還有一種問題就是爲了能讓處理器內部的運算單元能夠儘量的被充分利用處理器可能會對輸入代碼進行亂序執行,並且處理器會在計算之後將亂序的代碼進行結果重組來保證結果的一致性。在Java虛擬機中也有類似的指令重排序。
思考
這篇文章其實是講述java內存模型的,爲什麼會和計算機硬件扯上關係呢?注意到上面有說到多線程的情況下會造成緩存不一致的問題,提到多線程就離不開併發,想到併發的話就離不開三大問題,可見性,原子性,有序性的問題。那這三種特性不就是上面所說到的緩存不一致,處理器優化和指令重排序問題嗎。這這樣看來緩存不一致不就是可見性的問題,而原子性不就是處理器優化所導致的原子性問題,指令重排序就是導致有序性的問題。那麼Java內存模型又是什麼呢?
Java內存模型
Java內存模型的作用就是用來屏蔽掉不同操作系統中的內存差異性來保持併發的一致性。同時JMM也規範了JVM如何與計算機內存進行交互。簡單的來說java內存模型就是Java自己的一套協議來屏蔽掉各種硬件和操作系統的內存訪問差異,實現平臺一致性達到最終的"一次編寫,到處運行"。看到這裏就知道了Jmm是用來做什麼的。同時Java內存模型可以理解爲java併發內存模型。然後JMM
通信
Java內存模型(以下簡稱JMM)規定了,所有變量都存儲在主內存中,每個線程都有自己的本地緩存,所以線程中對變量的操作都必須在本地緩存中進行並不是直接操作主內存,線程之間的無法訪問對方線程的變量,想要通信的話就只能通過主內存進行通信。
JMM抽象示意圖:
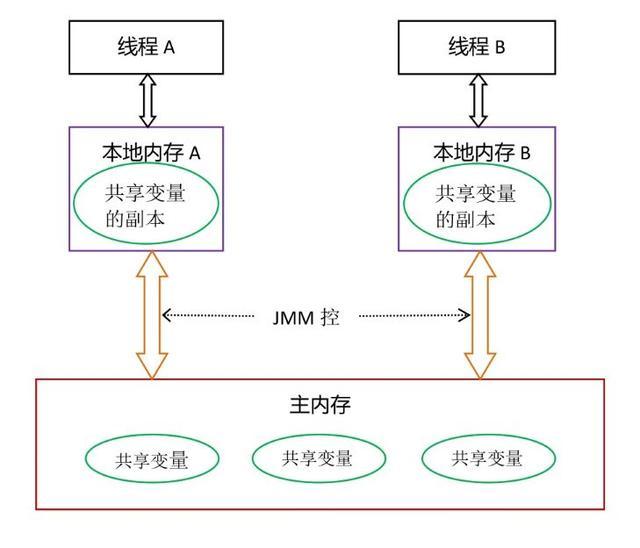
從上圖可以看出每個線程都有一個本地內存,如果線程想要通信的話要執行一下步驟:
A線程先把本地內存的值寫入主內存
B線程從主內存中去讀取出A線程寫的值
到這裏就對JMM有個清晰的理解了。JMM其實是一種規範,其主要目的就是爲了解決多線程通過共享內存進行通信時所產生的本地內存數據不一致,編譯器會對代碼指令重排序、處理器會對代碼亂序執行等帶來的問題。歡迎大家關注我的公種浩【程序員追風】,文章都會在裏面更新,整理的資料也會放在裏面。
解決的問題
JMM所解決的問題離不開我們上面所說的三大特性:可見性、原子性、有序性.
原子性:在java中使用synchronized關鍵字保證代碼的原子性。
可見性:volatile關鍵字保證了多線程操控變量的可見性,同時synchronized和final也可以保證變量的可見性,注意:volatile並不保證原子性,所以什麼時候用volatile一定要注意。
有序性:volatile可以禁用指令重排,synchronized關鍵字保證同一時刻只允許一條線程操作所以我們可以發現synchronized可以解決三種問題,所以使用synchronized關鍵字比較多,但是synchronized只允許一個線程進行操作,會造成上下文切換的效率問題。
最後
歡迎大家一起交流,喜歡文章記得點個贊喲,感謝支持!