




隨着公司產品UiBot的影響力在國內外不斷增強,與合作伙伴簽訂的合同也變得越來越多,故此導致業務人員對合同關鍵信息的提取工作,變得日益繁重。
基於此,公司內部關於電子合同信息提取的流程自動化需求應運而生。
以下是關於RPA+OCR提取電子合同信息的流程視圖。
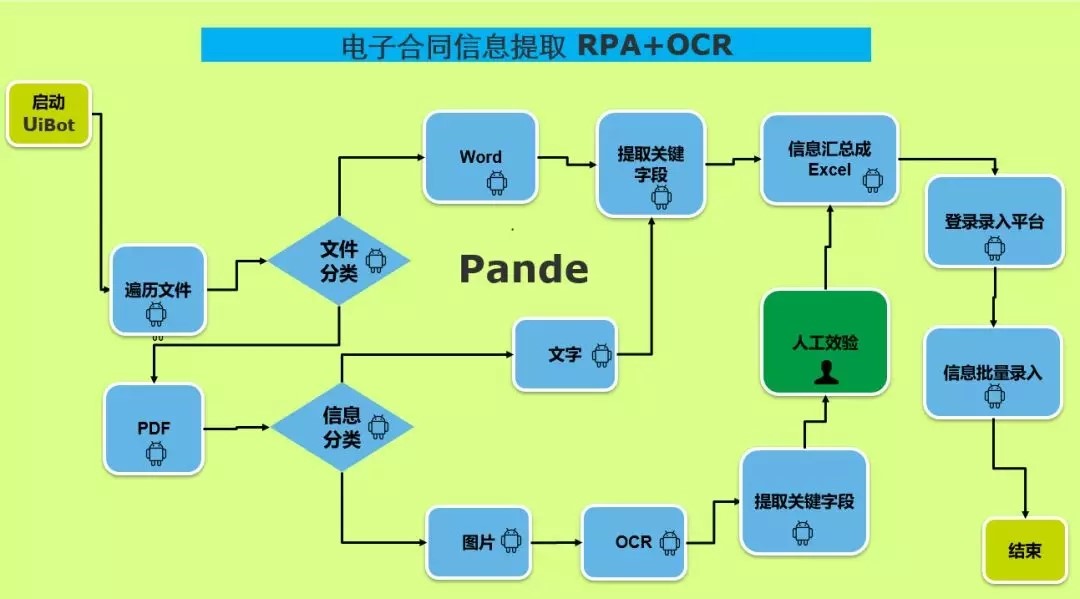
基於電子合同信息的提取,根據文件類型,分爲兩大類:Word和PDF。
1、Word類。Word類的會直接用RPA機器人UiBot從信息裏面根據字符規則提取出關鍵信息,生成結構化數據,當然,也會遇見有些Word文檔是補充協議等,沒有相關要提取的信息,這類會根據業務規則直接在流程裏面,根據模板判斷劃分出來。
2、PDF類。PDF類的會根據裏面信息分爲兩類,一類是文字型,一類是圖片型。
文字的可以使用UiBot的窗口元素中的預製組件獲取元素文本或者文本中的獲取文本來提取關鍵信息。(需要注意的是使用Acrobat的時候,需要在編輯中選擇輔助工具來做如下圖操作)

圖片類的,就必須要使用OCR來進行識別,然後進行信息提取,因爲上面有蓋章等不同因素的影響,正確率並不能保證百分之百,甚至也沒有關鍵性可以迴流驗證的信息,所以生成的結構化數據仍需要人工二次校驗,纔可以錄入系統,所以基於圖片類的電子合同,並沒有爲業務人員節省多少時間,無非是圖片類的電子合同佔比並不高,所以影響不大。
當然此類電子合同都是使用公司固定的統一模板,所以總體業務並不複雜,但如果合同模板不能統一,各有特色,可能就需要根據各個模板的類型來做歸類劃分和業務異常處理。
另一方面,就技術上來說,也可以直接用源碼模式來引用Office(Word,PDF文字類)的對象直接後臺處理,相比較而言,處理速度會比較快一些。