




作者 | 唐華敏(華敏) 阿里雲容器平臺技術專家
本文整理自《CNCF x Alibaba 雲原生技術公開課》第 15 講。
關注“阿里巴巴雲原生”公衆號,回覆關鍵詞“入門”,即可下載從零入門 K8s 系列文章 PPT。
導讀:Linux 容器是一種輕量級的虛擬化技術,在共享內核的基礎上,基於 namespace 和 cgroup 技術做到進程的資源隔離和限制。本文將會以 docker 爲例,介紹容器鏡像和容器引擎的基本知識。
容器
容器是一種輕量級的虛擬化技術,因爲它跟虛擬機比起來,它少了一層 hypervisor 層。先看一下下面這張圖,這張圖簡單描述了一個容器的啓動過程。
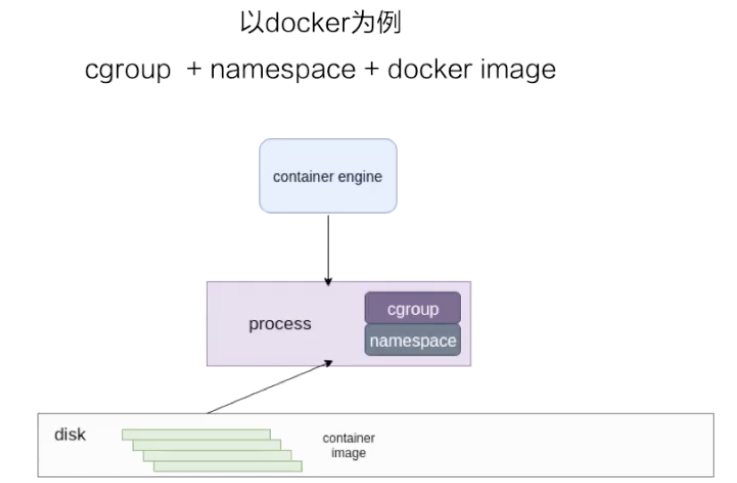
最下面是一個磁盤,容器的鏡像是存儲在磁盤上面的。上層是一個容器引擎,容器引擎可以是 docker,也可以是其它的容器引擎。引擎向下發一個請求,比如說創建容器,這時候它就把磁盤上面的容器鏡像運行成在宿主機上的一個進程。
對於容器來說,最重要的是怎麼保證這個進程所用到的資源是被隔離和被限制住的,在 Linux 內核上面是由 cgroup 和 namespace 這兩個技術來保證的。接下來以 docker 爲例,詳細介紹一下資源隔離和容器鏡像兩部分的內容。
一、資源隔離和限制
namespace
namespace 是用來做資源隔離的,在 Linux 內核上有七種 namespace,docker 中用到了前六種。第七種 cgroup namespace 在 docker 本身並沒有用到,但是在 runC 實現中實現了 cgroup namespace。

我們先從頭看一下:
- 第一個是 mout namespace。mout namespace 就是保證容器看到的文件系統的視圖,是容器鏡像提供的一個文件系統,也就是說它看不見宿主機上的其他文件,除了通過 -v 參數 bound 的那種模式,是可以把宿主機上面的一些目錄和文件,讓它在容器裏面可見的;
- 第二個是 uts namespace,這個 namespace 主要是隔離了 hostname 和 domain;
- 第三個是 pid namespace,這個 namespace 是保證了容器的 init 進程是以 1 號進程來啓動的;
- 第四個是網絡 namespace,除了容器用 host 網絡這種模式之外,其他所有的網絡模式都有一個自己的 network namespace 的文件;
- 第五個是 user namespace,這個 namespace 是控制用戶 UID 和 GID 在容器內部和宿主機上的一個映射,不過這個 namespace 用的比較少;
- 第六個是 IPC namespace,這個 namespace 是控制了進程兼通信的一些東西,比方說信號量;
- 第七個是 cgroup namespace,上圖右邊有兩張示意圖,分別是表示開啓和關閉 cgroup namespace。用 cgroup namespace 帶來的一個好處是容器中看到的 cgroup 視圖是以根的形式來呈現的,這樣的話就和宿主機上面進程看到的 cgroup namespace 的一個視圖方式是相同的;另外一個好處是讓容器內部使用 cgroup 會變得更安全。
這裏我們簡單用 unshare 示例一下 namespace 創立的過程。容器中 namespace 的創建其實都是用 unshare 這個系統調用來創建的。
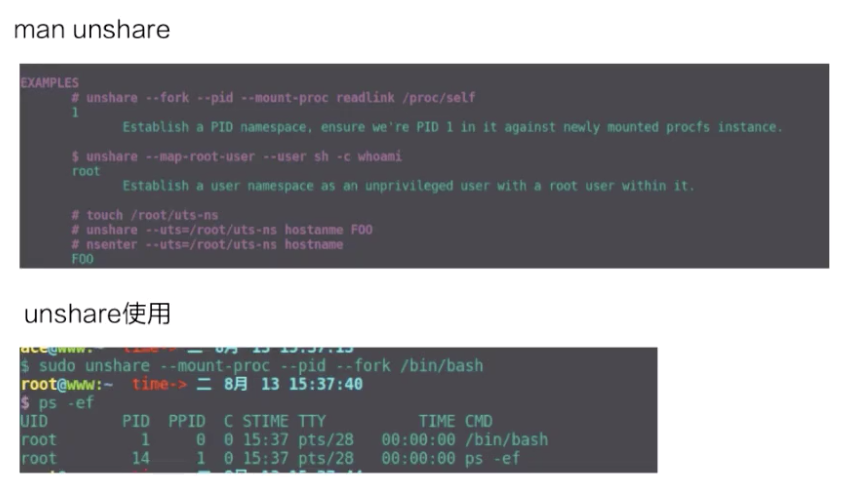
上圖上半部分是 unshare 使用的一個例子,下半部分是我實際用 unshare 這個命令去創建的一個 pid namespace。可以看到這個 bash 進程已經是在一個新的 pid namespace 裏面,然後 ps 看到這個 bash 的 pid 現在是 1,說明它是一個新的 pid namespace。
cgroup
兩種 cgroup 驅動
cgroup 主要是做資源限制的,docker 容器有兩種 cgroup 驅動:一種是 systemd 的,另外一種是 cgroupfs 的。

-
cgroupfs 比較好理解。比如說要限制內存是多少、要用 CPU share 爲多少?其實直接把 pid 寫入對應的一個 cgroup 文件,然後把對應需要限制的資源也寫入相應的 memory cgroup 文件和 CPU 的 cgroup 文件就可以了;
- 另外一個是 systemd 的一個 cgroup 驅動。這個驅動是因爲 systemd 本身可以提供一個 cgroup 管理方式。所以如果用 systemd 做 cgroup 驅動的話,所有的寫 cgroup 操作都必須通過 systemd 的接口來完成,不能手動更改 cgroup 的文件。
容器中常用的 cgroup
接下來看一下容器中常用的 cgroup。Linux 內核本身是提供了很多種 cgroup,但是 docker 容器用到的大概只有下面六種:

- 第一個是 CPU,CPU 一般會去設置 cpu share 和 cupset,控制 CPU 的使用率;
- 第二個是 memory,是控制進程內存的使用量;
- 第三個 device ,device 控制了你可以在容器中看到的 device 設備;
- 第四個 freezer。它和第三個 cgroup(device)都是爲了安全的。當你停止容器的時候,freezer 會把當前的進程全部都寫入 cgroup,然後把所有的進程都凍結掉,這樣做的目的是:防止你在停止的時候,有進程會去做 fork。這樣的話就相當於防止進程逃逸到宿主機上面去,是爲安全考慮;
- 第五個是 blkio,blkio 主要是限制容器用到的磁盤的一些 IOPS 還有 bps 的速率限制。因爲 cgroup 不唯一的話,blkio 只能限制同步 io,docker io 是沒辦法限制的;
- 第六個是 pid cgroup,pid cgroup 限制的是容器裏面可以用到的最大進程數量。
不常用的 cgroup
也有一部分是 docker 容器沒有用到的 cgroup。容器中常用的和不常用的,這個區別是對 docker 來說的,因爲對於 runC 來說,除了最下面的 rdma,所有的 cgroup 其實都是在 runC 裏面支持的,但是 docker 並沒有開啓這部分支持,所以說 docker 容器是不支持下圖這些 cgroup 的。

二、容器鏡像
docker images
接下來我們講一下容器鏡像,以 docker 鏡像爲例去講一下容器鏡像的構成。
docker 鏡像是基於聯合文件系統的。簡單描述一下聯合文件系統,大概的意思就是說:它允許文件是存放在不同的層級上面的,但是最終是可以通過一個統一的視圖,看到這些層級上面的所有文件。
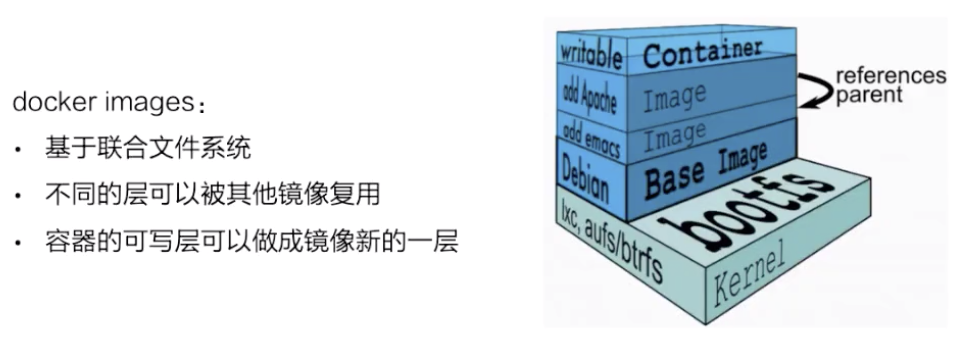
如上圖所示,右邊是從 docker 官網拿過來的容器存儲的一個結構圖。
這張圖非常形象地表明瞭 docker 的存儲,docker 存儲也就是基於聯合文件系統,是分層的。每一層是一個 Layer,這些 Layer 由不同的文件組成,它是可以被其他鏡像所複用的。可以看一下,當鏡像被運行成一個容器的時候,最上層就會是一個容器的讀寫層。這個容器的讀寫層也可以通過 commit 把它變成一個鏡像頂層最新的一層。
docker 鏡像的存儲,它的底層是基於不同的文件系統的,所以它的存儲驅動也是針對不同的文件系統作爲定製的,比如 AUFS、btrfs、devicemapper 還有 overlay。docker 對這些文件系統做了一些相對應的 graph driver 的驅動,通過這些驅動把鏡像存在磁盤上面。
以 overlay 爲例
存儲流程
接下來我們以 overlay 這個文件系統爲例,看一下 docker 鏡像是怎麼在磁盤上進行存儲的。
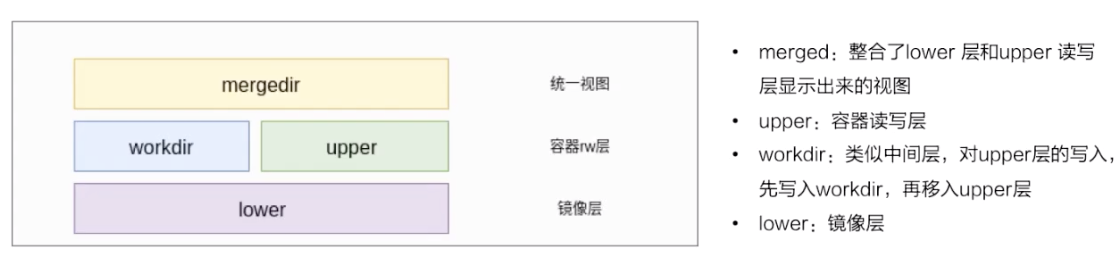
先看一下下面這張圖,簡單地描述了 overlay 文件系統的工作原理。
-
最下層是一個 lower 層,也就是鏡像層,它是一個只讀層;
-
右上層是一個 upper 層,upper 是容器的讀寫層,upper 層採用了寫實複製的機制,也就是說只有對某些文件需要進行修改的時候纔會從 lower 層把這個文件拷貝上來,之後所有的修改操作都會對 upper 層的副本進行修改;
-
upper 並列的有一個 workdir,它的作用是充當一箇中間層的作用。也就是說,當對 upper 層裏面的副本進行修改時,會先放到 workdir,然後再從 workdir 移到 upper 裏面去,這個是 overlay 的工作機制;
- 最上面的是 mergedir,是一個統一視圖層。從 mergedir 裏面可以看到 upper 和 lower 中所有數據的整合,然後我們 docker exec 到容器裏面,看到一個文件系統其實就是 mergedir 統一視圖層。
文件操作
接下來我們講一下基於 overlay 這種存儲,怎麼對容器裏面的文件進行操作?

先看一下讀操作,容器剛創建出來的時候,upper 其實是空的。這個時候如果去讀的話,所有數據都是從 lower 層讀來的。
寫操作如剛纔所提到的,overlay 的 upper 層有一個寫實數據的機制,對一些文件需要進行操作的時候,overlay 會去做一個 copy up 的動作,然後會把文件從 lower 層拷貝上來,之後的一些寫修改都會對這個部分進行操作。
然後看一下刪除操作,overlay 裏面其實是沒有真正的刪除操作的。它所謂的刪除其實是通過對文件進行標記,然後從最上層的統一視圖層去看,看到這個文件如果做標記,就會讓這個文件顯示出來,然後就認爲這個文件是被刪掉的。這個標記有兩種方式:
- 一種是 whiteout 的方式;
- 第二個就是通過設置目錄的一個擴展權限,通過設置擴展參數來做到目錄的刪除。
操作步驟
接下來看一下實際用 docker run 去啓動 busybox 的容器,它的 overlay 的掛載點是什麼樣子的?

第二張圖是 mount,可以看到這個容器 rootfs 的一個掛載,它是一個 overlay 的 type 作爲掛載的。裏面包括了 upper、lower 還有 workdir 這三個層級。
然後看一下容器裏面新文件的寫入。docker exec 去創建一個新文件,diff 這個從上面可以看到,是它的一個 upperdir。再看 upperdir 裏面有這個文件,文件裏面的內容也是 docker exec 寫入的。
最後看一下最下面的是 mergedir,mergedir 裏面整合的 upperdir 和 lowerdir 的內容,也可以看到我們寫入的數據。
三、容器引擎
containerd 容器架構詳解
接下來我們基於 CNCF 的一個容器引擎上的 containerd,來講一下容器引擎大致的構成。下圖是從 containerd 官網拿過來的一張架構圖,基於這張架構圖先簡單介紹一下 containerd 的架構。

上圖如果把它分成左右兩邊的話,可以認爲 containerd 提供了兩大功能。
第一個是對於 runtime,也就是對於容器生命週期的管理,左邊 storage 的部分其實是對一個鏡像存儲的管理。containerd 會負責進行的拉取、鏡像的存儲。
按照水平層次來看的話:
-
第一層是 GRPC,containerd 對於上層來說是通過 GRPC serve 的形式來對上層提供服務的。Metrics 這個部分主要是提供 cgroup Metrics 的一些內容;
-
下面這層的左邊是容器鏡像的一個存儲,中線 images、containers 下面是 Metadata,這部分 Matadata 是通過 bootfs 存儲在磁盤上面的。右邊的 Tasks 是管理容器的容器結構,Events 是對容器的一些操作都會有一個 Event 向上層發出,然後上層可以去訂閱這個 Event,由此知道容器狀態發生什麼變化;
- 最下層是 Runtimes 層,這個 Runtimes 可以從類型區分,比如說 runC 或者是安全容器之類的。
shim v1/v2 是什麼
接下來講一下 containerd 在 runtime 這邊的大致架構。下面這張圖是從 kata 官網拿過來的,上半部分是原圖,下半部分加了一些擴展示例,基於這張圖我們來看一下 containerd 在 runtime 這層的架構。
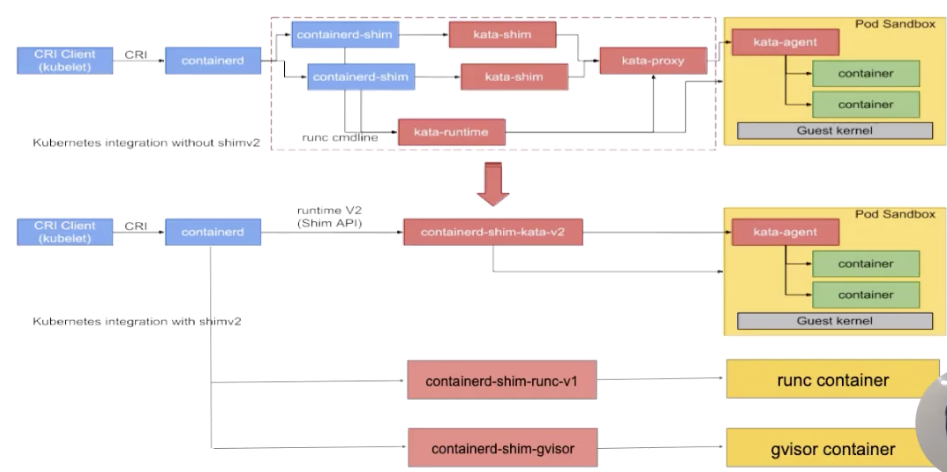
如圖所示:按照從左往右的一個順序,從上層到最終 runtime 運行起來的一個流程。
我們先看一下最左邊,最左邊是一個 CRI Client。一般就是 kubelet 通過 CRI 請求,向 containerd 發送請求。containerd 接收到容器的請求之後,會經過一個 containerd shim。containerd shim 是管理容器生命週期的,它主要負責兩方面:
- 第一個是它會對 io 進行轉發;
- 第二是它會對信號進行傳遞。
圖的上半部分畫的是安全容器,也就是 kata 的一個流程,這個就不具體展開了。下半部分,可以看到有各種各樣不同的 shim。下面介紹一下 containerd shim 的架構。
一開始在 containerd 中只有一個 shim,也就是藍色框框起來的 containerd-shim。這個進程的意思是,不管是 kata 容器也好、runc 容器也好、gvisor 容器也好,上面用的 shim 都是 containerd。
後面針對不同類型的 runtime,containerd 去做了一個擴展。這個擴展是通過 shim-v2 這個 interface 去做的,也就是說只要去實現了這個 shim-v2 的 interface,不同的 runtime 就可以定製不同的 shim。比如:runC 可以自己做一個 shim,叫 shim-runc;gvisor 可以自己做一個 shim 叫 shim-gvisor;像上面 kata 也可以自己去做一個 shim-kata 的 shim。這些 shim 可以替換掉上面藍色框的 containerd-shim。
這樣做的好處有很多,舉一個比較形象的例子。可以看一下 kata 這張圖,它上面原先如果用 shim-v1 的話其實有三個組件,之所以有三個組件的原因是因爲 kata 自身的一個限制,但是用了 shim-v2 這個架構後,三個組件可以做成一個二進制,也就是原先三個組件,現在可以變成一個 shim-kata 組件,這個可以體現出 shim-v2 的一個好處。
containerd 容器架構詳解 - 容器流程示例
接下來我們以兩個示例來詳細解釋一下容器的流程是怎麼工作的,下面的兩張圖是基於 containerd 的架構畫的一個容器的工作流程。
start 流程
先看一下容器 start 的流程:
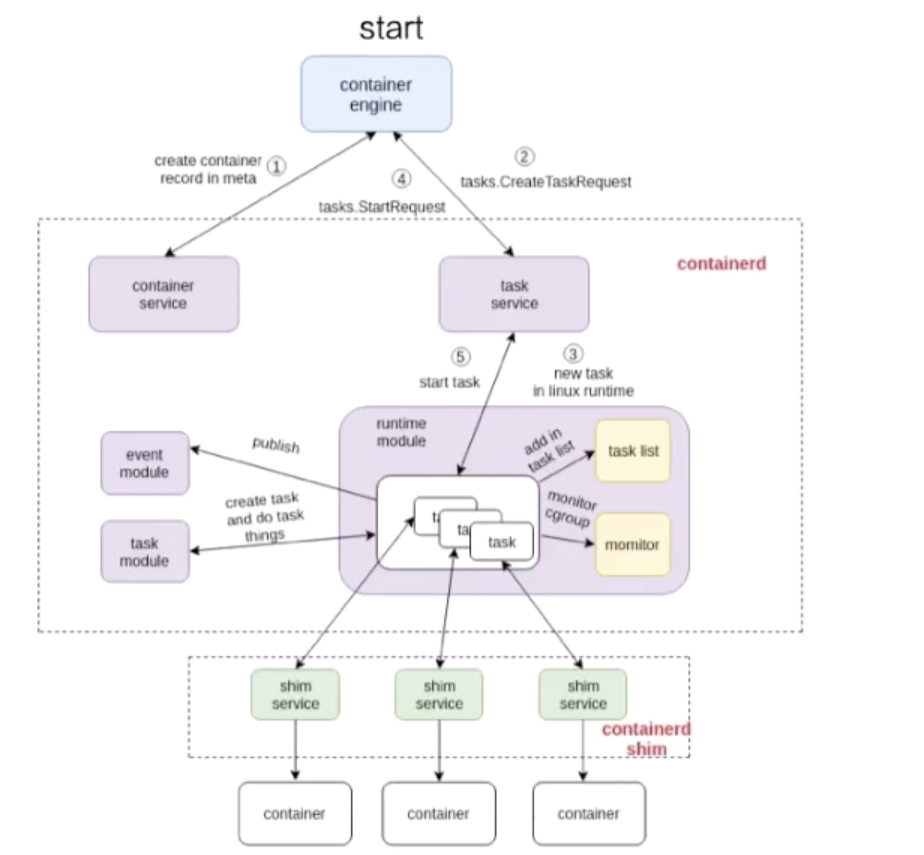
這張圖由三個部分組成:
- 第一個部分是容器引擎部分,容器引擎可以是 docker,也可以是其它的;
- 兩個虛線框框起來的 containerd 和 containerd-shim,它們兩個是屬於 containerd 架構的部分;
- 最下面就是 container 的部分,這個部分是通過一個 runtime 去拉起的,可以認爲是 shim 去操作 runC 命令創建的一個容器。
先看一下這個流程是怎麼工作的,圖裏面也標明瞭 1、2、3、4。這個 1、2、3、4 就是 containerd 怎麼去創建一個容器的流程。
首先它會去創建一個 matadata,然後會去發請求給 task service 說要去創建容器。通過中間一系列的組件,最終把請求下發到一個 shim。containerd 和 shim 的交互其實也是通過 GRPC 來做交互的,containerd 把創建請求發給 shim 之後,shim 會去調用 runtime 創建一個容器出來,以上就是容器 start 的一個示例。
exec 流程
接下來看下面這張圖是怎麼去 exec 一個容器的。
和 start 流程非常相似,結構也大概相同,不同的部分其實就是 containerd 怎麼去處理這部分流程。和上面的圖一樣,我也在圖中標明瞭 1、2、3、4,這些步驟就代表了 containerd 去做 exec 的一個先後順序。
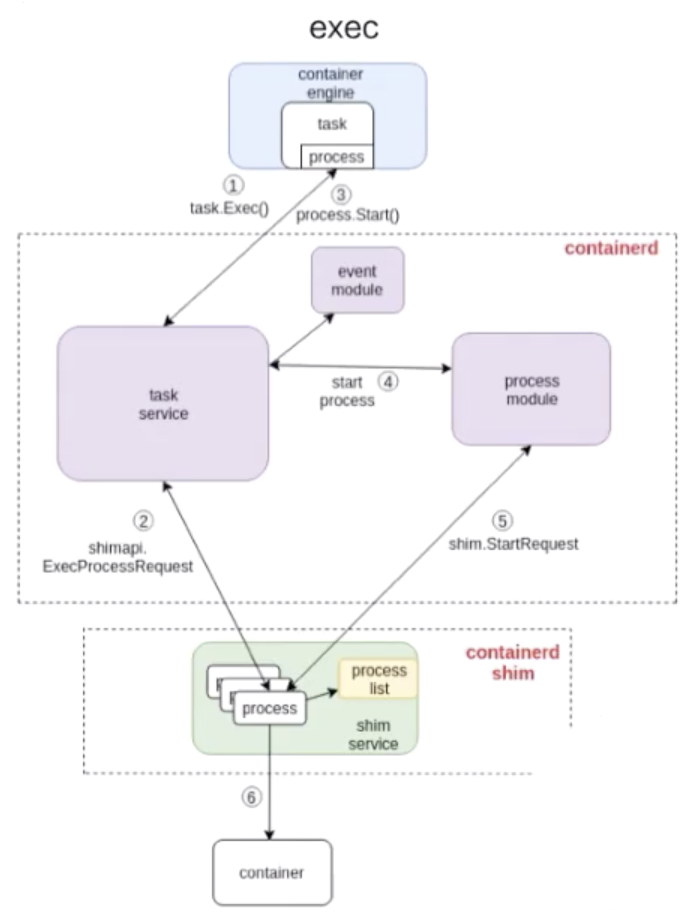
由上圖可以看到:exec 的操作還是發給 containerd-shim 的。對容器來說,去 start 一個容器和去 exec 一個容器,其實並沒有本質的區別。
最終的一個區別無非就是:是否對容器中跑的進程做一個 namespace 的創建。
- exec 的時候,需要把這個進程加入到一個已有的 namespace 裏面;
- start 的時候,容器進程的 namespace 是需要去專門創建。
本文總結
最後希望各位同學看完本文後,能夠對 Linux 容器有更深刻的瞭解。這裏爲大家簡單總結一下本文的內容:
- 容器如何用 namespace 做資源隔離以及 cgroup 做資源限制;
- 簡單介紹了基於 overlay 文件系統的容器鏡像存儲;
- 以 docker+containerd 爲例介紹了容器引擎如何工作的。
“ 阿里巴巴雲原生微信公衆號(ID:Alicloudnative)關注微服務、Serverless、容器、Service Mesh等技術領域、聚焦雲原生流行技術趨勢、雲原生大規模的落地實踐,做最懂雲原生開發者的技術公衆號。”
更多相關內容,請關注“阿里巴巴雲原生”。