




explain
explain可以對select,update,insert,replace,delete進行sql分析
對評論進行分頁展示

結果(檢查是否正確執行索引)
SQL如何使用索引
關聯查詢的執行順序(mysql優化器根據索引的信息,會自動的調整索引的順序)
查詢掃描的數據行數
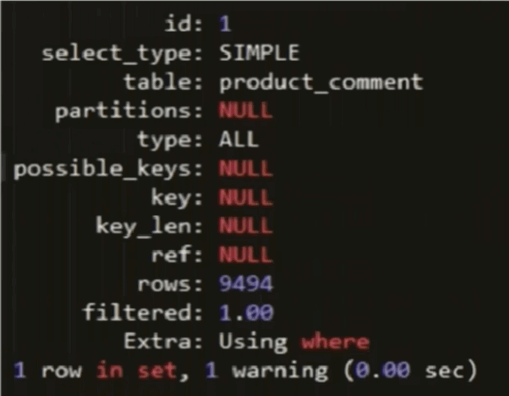
ID列
ID列中的數據爲一組數字,表示執行SELECT語句的順序
ID值相同時,執行順序由上至下
ID值越大優先級越高,越先被執行
查詢一組分類下商品的標題

查詢最小分類的ID對應最大商品ID的一個評論標題(3個select語句)

SELECT_TYPE列
UNION RESULT時,ID值爲null.
DERIVED 衍生表,用來表示包含在FROM字句中的字查詢。myslq遞歸的執行,並將結果放在臨時表中,臨時表就是派生表。

TABLE列,執行計劃中的數據是由哪個表輸出的
輸出數據行所在的表的名稱(如果有別名就顯示別名)
由ID爲M,N查詢union產生的結果集(臨時表)
/由ID爲N的查詢產生的結果(臨時表,衍生表)
PARTITIONS列,查詢分區表
如果不按照分區鍵選擇,就會顯示全部的分區,因爲是跨分區掃描
對於分區表,顯示查詢的分區ID
對於非分區表,顯示爲NULL
TYPE列,查詢中使用的一個類型(mysql訪問數據的方式)

Extra列(擴展列,包含mysql如何執行查詢的一些附加信息)

POSSIBLE_KEYS列
指出MySQL能使用那些索引來優化查詢
查詢列所涉及到的列上的索引都會被列出,但不一定會被使用
KEY列
查詢優化器優化查詢實際所使用的索引
如果沒有可用的索引,則顯示爲NULL
如查詢使用了覆蓋索引,則該索引僅出現在Key列中
KEY_LEN列
表示索引字段的最大可能長度
Key len的長度由字段定義計算而來,並非數據的實際長度
Ref列(當前表在利用key列中的索引進行查詢時,所用到的列或者常量)
表示那些列或常量被用於查找索引列上的值
Rows列
表示MySQL通過索引統計信息,估算的所需讀取的行數
Rows值的大小是個統計抽樣結果,並不十分準確
Filtered列
表示返回結果的行數佔需讀取行數的百分比
Filtered列的值越大越好
Filtered列的值依賴說統計信息
執行計劃的限制
無法展示存儲過程,觸發器,UDF對查詢的影響
無法使用EXPLAIN對存儲過程進行分析
早期版本的MySQL只支持對SELECT語句進行分析。
優化評論分頁查詢(添加索引)
使用情況:中間結果集差距很小的情況,或者數據量很小的情況
首先,我們可以考慮對where條件添加索引,就是audit_status 和 product_id添加一個聯合索引
問題:audit_status 和 product_id哪個放在最左側 ?
根據索引設計規範,先計算一下這兩列在表中的區分度 ,數據越接近1,區分度越高


缺點:越往後翻頁,查詢效率越來越差,時間也越來越長,尤其數據量很大
進一步優化:改寫
數據庫訪問開銷=索引IO+索引全部記錄結果對應表數據的IO
數據庫訪問開銷=索引IO+索引返回15條記錄對應表數據的IO
IO節約很多
在任意位置翻頁的消耗都是相同的
使用情況:中間結果集差距很大的情況,或者ORDER BY,WHERE有對應的覆蓋索引

該SQL使用前提:comment_id是主鍵,而且有覆蓋索引(product_id和audit_status聯合索引)
需求:刪除重複數據
刪除評論表中對同一訂單同一商品的重複評論,只保留最早的一條
步驟一:意看是否存在對於一訂單同一商品的重複評論
步驟二:備份product_comment表
步驟三:刪除同一訂單的重複評論

測試查詢數據

第二步
CREATE TABLE bak_product_comment_161022 LIKE product_comment;
INSERT INTO bak_product_comment_161022 SELECT * FROM product_comment;
或者
CREATE TABLE bak_product_comment_161022 AS SELECT * FROM product_comment;
子查詢:查詢出所有商品中訂單的重複評論的最小評論ID(要保留,最早的) 關聯商品評論表,刪除,相同訂單,相同商品,大的評論ID

需求:分區間統計
根據訂單主表(order_master)查詢出所有用戶消費總金額
關聯登陸日誌表和訂單主表
CASE區間分隔
COUNT 用戶量統計



需求:捕獲有問題的SQL-慢查日誌


快速分析慢查詢日誌-mysqldumpslow

