




一、mysql組件
1.mysql對外提供的交互接口(connectors):
編程語言通過connectors組件,比如php,pymysql,JDBC來操作sql
2.管理服務和工具組件(Management Service & Utilities):
提供對mysql的集成管理,比如備份,恢復,等
3.連接池組件(Connection Pool):
負責監聽客戶端向server的各種請求,每個成功連接的客戶端都會分配一個線程負責與server通信
4.sql接口組件(SQL Interface):
接收客戶端sql命令,並將結果返回給客戶端
5.查詢分析器(Parser):
解析sql語法是否正確,不合理則報錯
6.優化器組件(Optimizer):
對sql語句按照標準優化分析
7.緩存組件(Caches & Buffers):
緩存緩衝數據
8.插件式存儲引擎(Pluggable Storage Engines):
mysql是關係型數據庫,數據是以表的形式存儲的,對於表的創建,數據的存儲,更新都是由存儲引擎完成的
9.物理文件系統:
真實存儲數據表,數據,日誌的地方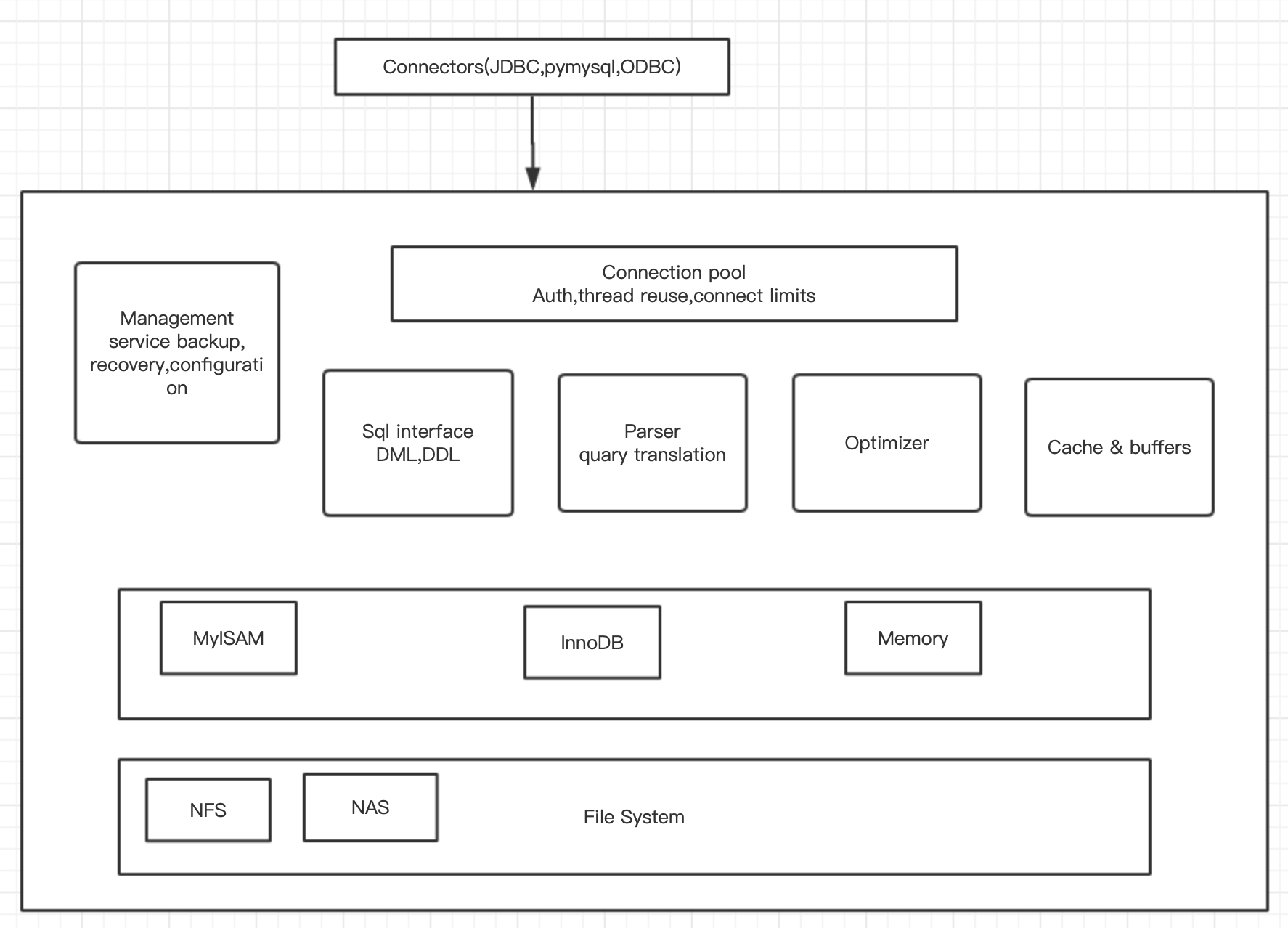
二、查詢流程
1.客戶端服務端通信協議:
在任一時刻,要麼是服務器向客戶端發送數據,要麼是客戶端向服務器發送數據,這兩個動作不能同時發生。一旦一端開始發送消息,另一端要接收完整個消息才能響應它,所以無法也無須將一個消息切成小塊獨立發送,也沒有辦法進行流量控制。客戶端用一個單獨的數據包將查詢請求發送給服務器,所以當查詢語句很長的時候,需要設置 max_allowed_packet參數,如果查詢實在是太大,服務端會拒絕接收更多數據並拋出異常。與之相反的是,服務器響應給用戶的數據通常會很多,由多個數據包組成。但是當服務器響應客戶端請求時,客戶端必須完整的接收整個返回結果,而不能簡單的只取前面幾條結果,然後讓服務器停止發送。因而在實際開發中,儘量保持查詢簡單且只返回必需的數據,減小通信間數據包的大小和數量是一個非常好的習慣,這也是查詢中儘量避免使用 SELECT * 以及加上 LIMIT 限制的原因之
2.查詢緩存
在解析一個查詢語句前,如果查詢緩存是打開的,那麼 MySQL 會檢查這個查詢語句是否命中查詢緩存中的數據。如果當前查詢恰好命中查詢緩存,在檢查一次用戶權限後直接返回緩存中的結果。這種情況下,查詢不會被解析,也不會生成執行計劃,更不會執行。MySQL將緩存存放在一個引用表 (不要理解成table,可以認爲是類似於 HashMap 的數據結構),通過一個哈希值索引,這個哈希值通過查詢本身、當前要查詢的數據庫、客戶端協議版本號等一些可能影響結果的信息計算得來。所以兩個查詢在任何字符上的不同 (例如 : 空格、註釋),都會導致緩存不會命中
MySQL 查詢緩存系統會跟蹤查詢中涉及的每個表,如果這些表 (數據或結構) 發生變化,那麼和這張表相關的所有緩存數據都將失效。正因爲如此,在任何的寫操作時,MySQL必須將對應表的所有緩存都設置爲失效。如果查詢緩存非常大或者碎片很多,這個操作就可能帶來很大的系統消耗,甚至導致系統僵死一會兒,而且查詢緩存對系統的額外消耗也不僅僅在寫操作,讀操作也不例外 :
1> 任何的查詢語句在開始之前都必須經過檢查,即使這條 SQL語句 永遠不會命中緩存
2> 如果查詢結果可以被緩存,那麼執行完成後,會將結果存入緩存,也會帶來額外的系統消耗
3.查詢優化
經過前面的步驟生成的語法樹被認爲是合法的了,並且由優化器將其轉化成查詢計劃。多數情況下,一條查詢可以有很多種執行方式,最後都返回相應的結果。優化器的作用就是找到這其中最好的執行計劃。MySQL使用基於成本的優化器,它嘗試預測一個查詢使用某種執行計劃時的成本,並選擇其中成本最小的一個
4.查詢執行引擎
在完成解析和優化階段以後,MySQL會生成對應的執行計劃,查詢執行引擎根據執行計劃給出的指令逐步執行得出結果。整個執行過程的大部分操作均是通過調用存儲引擎實現的接口來完成,這些接口被稱爲 handler API。查詢過程中的每一張表由一個 handler 實例表示。實際上,MySQL在查詢優化階段就爲每一張表創建了一個 handler實例,優化器可以根據這些實例的接口來獲取表的相關信息,包括表的所有列名、索引統計信息等。存儲引擎接口提供了非常豐富的功能,但其底層僅有幾十個接口,這些接口像搭積木一樣完成了一次查詢的大部分操作
5.返回結果
查詢執行的最後一個階段就是將結果返回給客戶端。即使查詢不到數據,MySQL 仍然會返回這個查詢的相關信息,比如該查詢影響到的行數以及執行時間等。如果查詢緩存被打開且這個查詢可以被緩存,MySQL也會將結果存放到緩存中。結果集返回客戶端是一個增量且逐步返回的過程。有可能 MySQL 在生成第一條結果時,就開始向客戶端逐步返回結果集。這樣服務端就無須存儲太多結果而消耗過多內存,也可以讓客戶端第一時間獲得返回結果。需要注意的是,結果集中的每一行都會以一個滿足客戶端/服務器通信協議的數據包發送,再通過 TCP協議 進行傳輸,在傳輸過程中,可能對 MySQL 的數據包進行緩存然後批量發送
————————————————
版權聲明:本文爲CSDN博主「小柴的生活觀」的原創文章,遵循 CC 4.0 BY-SA 版權協議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/chenshun123/article/details/79677037