




任何編程語言都會有一個內存模型,以便管理爲變量分配的內存空間。不同的編程語言,如C、C++、Java、C#,Python,它們的內存模型都是不相同的,本文將以現在最流行的Python語言爲例,來說明動態類型語言的內存管理方式。
1. 重複使用內存空間
賦值語句是Python語言中最簡單的語句之一,雖然賦值語言很簡單,但卻內含玄機。
例如,將一個值賦給一個變量是最常見的賦值操作。
n = 1 # 將1賦給變量n整數1是一個值,而n是一個對象。這是最簡單不過的賦值語句了。那麼在內存中是如何操作的呢?其實在Python中,任何值都可以看做是一個對象,例如,1是int類的實例,True是bool類的實例。所以將1賦給變量n,其實是n指向了int類型的對象,所以n本質上就是一個對象的引用。
Python作爲動態語言,採用了引用與對象分離的策略,這也使得任何引用都可以指向任何對象,而且可以動態改變引用指向的對象類型,也就是說,可以將一個指向int類型的對象的引用重新指向bool類型的對象。所以可以將Python語言的對象模型看做是超市裏的儲物櫃(這裏只是用儲物櫃作爲內存模型的比喻,不要與超市儲物櫃實際的操作進行比較)。

每一個小櫃子相當於一塊內存區域,這塊內存區域保存了不同類型的值。對於像C++、Java一樣的靜態語言,一旦分配了某一個小櫃子,就意味着這個櫃子只能保存特定的物品,如只能放鞋子、只能放手套、只能放衣服。而對於打開小櫃子的鑰匙(相當於變量),同時也只能打開某一個特定的小櫃子,相當於一個變量同時只能指向一個對象一樣。當然,在鑰匙上進行設置後,該鑰匙可以指向其他同類型的小櫃子(相當於改變變量指向的對象,如將一個指向int類型對象的變量指向了另外一個int類型的對象)。
不過Python語言就不一樣了。在Python版的儲物櫃中,每一個小櫃子並不限定存儲物品的類型,而一把鑰匙經過設置後,可以打開任意一個小櫃子(相當於任意改變變量指向的對象)。這樣做的好處是更靈活,沒必要爲存儲特定的物品,增加新的儲物櫃,只要還有空的小櫃子,就可以放任何物品。但缺點也很明顯,就是打開一個小櫃子後,需要多進行一步判斷的操作,判斷這個小櫃子到底是存儲的什麼物品。
當然,對於同一個特定的小櫃子,可能會配有多把鑰匙,這些鑰匙都可以打開這個特定的小櫃子,這就相當於多個變量指向同一個對象。例如,
x = 10y = 10z = 10x、y和z三個變量的值都是10,這個10就相當於要保存在小櫃子中的物品。x、y和z相當於3把鑰匙。而3個變量中的值都是10,所以被認爲是同一個值(物品),因此,就只需要動用一個小櫃子保存10,而3個變量都會指向這個小櫃子(由於計算機中值具有無限可複製性,所以只要有一個物品,就可以無限複製,所以不必考慮現實中將小櫃子中的東西拿走了就爲空的情況)。所以其實x、y和z這3個變量指向了同一個內存地址(相當於小櫃子的序號)。可以用id函數驗證這3個變量的內存地址是否相同,代碼如下:
print(id(x))print(id(y))print(id(z))輸出結果如下:
4470531424
4470531424
4470531424
也可以用下面的代碼將內存地址轉換爲十六進制形式。
print(hex(id(x)))print(hex(id(y)))print(hex(id(z)))輸出結果如下:
0x10a76e560
0x10a76e560
0x10a76e560
根據前面的輸出結果,很顯然,x、y和z指向的是同一個內存地址。讀者可以將10換成其他的對象,如True、10.12、"hello world",結果都是一樣(由於機器不同,輸出的內存地址可能不同,但3個變量的內存地址肯定都是相同的)。
也可以用is運算符判斷這3個變量是否指向同一個值。
print(x is y is z) # 輸出結果:True但要注意,只有不可變類型,如int、float、bool、string等,纔會使用同一個儲物櫃。如果是可變類型,如列表、對象,每次都會分配新的內存空間。這裏的不可變是指值一旦確定,值本身無法修改。例如int類型的10,這個10是固定的,不能修改,如果修改成11,那麼就是新的值了,需要申請新的小櫃子。而列表,如空列表[],以後還可以向空列表中添加任何類型的值,也可以修改和刪除列表中的值。所以沒有辦法爲所有的空列表分配同一個小櫃子,因爲有的空列表,現在是空,以後不一定是空。所以每一個列表類型的值都會新分配一個小櫃子,但元組就不同了,由於元組是隻讀的,所以一開始是空的元組,那麼這個元組今生今世將永遠是空,所以可以爲所有的空元組,以及所有相同元素個數和值的元組分配同一個小櫃子。看下面代碼:
class MyClass:passa = []
b = []
c = MyClass()
d = MyClass()
t1 = (1,2,3)
t2 = (1,2,3)print(a is b) # False 元素個數和類型相同的列表不會使用同一個內存空間(小櫃子)print(c is d) # False MyClass類的不同實例不會使用同一個內存空間(小櫃子)print(t1 is t2) # True 元素個數和類型相同的元組會使用同一個內存空間(小櫃子)
這種將相同,但不可變的值保存在同一個內存空間的方式也稱爲值的緩存,這樣做非常節省內存空間,而且程序的執行效率更高。因爲省去了大量分配內存空間的時間。
2. 引用計數器
在Python語言中是無法自己釋放變量內存的,所以Python虛擬機提供了自動回收內存的機制,那麼Python虛擬機是如何知道哪一個變量佔用的內存可以被回收呢?通常的做法是爲每一塊被佔用的內存設置一個引用計數器,如果該內存塊沒有被任何變量引用(也就是引用計數器爲0),那麼該內存塊就可以被釋放,否則無法被釋放。
在sys模塊中有一個getrefcount函數,可以用來獲取任何變量指向的內存塊的引用計數器當前的值。用法如下:
from sys import getrefcount
a = [1, 2, 3]print(getrefcount(a)) # 輸出2 b = aprint(getrefcount(b)) # 輸出3print(getrefcount(a)) # 輸出3 x = 1print(getrefcount(x)) #輸出1640y = 1print(getrefcount(x)) # 輸出1641print(getrefcount(y)) # 輸出1641
要注意,使用getrefcount函數獲得引用計數器的值時,實際上會創建一個臨時的引用,所以getrefcount函數返回的值會比實際的值多1。而對於具體的值(如本例的1),系統可能在很多地方都引用了該值,所以根據Python版本和當前運行的應用不同,getrefcount函數返回的值是不確定的。
3. 對象引用
像C++這樣的編程語言,對象的傳遞分爲值傳遞和指針傳遞。如果是值傳遞,就會將對象中的所有成員屬性的值都一起復制,而指針傳遞,只是複製了對象的內存首地址。不過在Python中,並沒有指針的概念。只有一個對象引用。也就是說,Python語言中對象的複製與C++中的對象指針複製是一樣的。只是將對象引用計數器加1而已。具體看下面的代碼:
from sys import getrefcount
# 類的構造方法傳入另外一個對象的引用class MyClass(object):def __init__(self, other_obj):
self.other_obj = other_obj # 這裏的other_obj與後面的data指向了同一塊內存地址 data = {'name':'Bill','Age':30}print(getrefcount(data)) # 輸出2my = MyClass(data)print(id(my.other_obj)) # 輸出4364264288print(id(data)) #輸出4364264288
print(getrefcount(data)) # 輸出3在Python中,一切都是對象,包括值。如1、2、3、"abcd"等。所以Python會在使用這些值時,先將其保存在一塊固定的內存區域,然後將所有賦給這些值的變量指向這塊內存區域,同時引用計數器加1。
例如,
a = 1
b = 1
其中a和b指向了同一塊內存空間,這兩個變量其實都保存了對1的引用。使用id函數查看這兩個變量的引用地址是相同的。
4. 循環引用與拓撲圖
如果對象引用非常多,就可能會構成非常複雜的拓撲結果。例如,下面代碼的引用拓撲關係就非常複雜。估計大多數同學都無法一下子看出這段程序中各個對象的拓撲關係。
class MyClass1:def __init__(self, obj):
self.obj = obj
class MyClass2:def __init__(self,obj1,obj2):
self.obj1 = obj1
self.obj2 = obj2
data1 = ['hello', 'world']
data2 = [data1, MyClass1(data1),3,dict(data = data1)]
data3 = [data1,data2,MyClass2(data1,data2),MyClass1(MyClass2(data1,data2))]
看不出來也不要緊,可以使用objgraph模塊繪製出某個變量與其他變量的拓撲關係,objgraph是第三方模塊,需要使用pip install objgraph命令安裝,如果機器上安裝了多個Python環境,要注意看看pip命令是否屬於當前正在使用的Python環境,不要將objgraph安裝在其他的Python環境中。
安裝完objgraph後,可以使用下面命令看看data3與其他對象的引用關係。
import objgraph
objgraph.show_refs([data3], filename='對象引用關係.png')show_refs函數會在當前目錄下生成一個”對象引用關係.png“的圖像文件,如下圖所示。
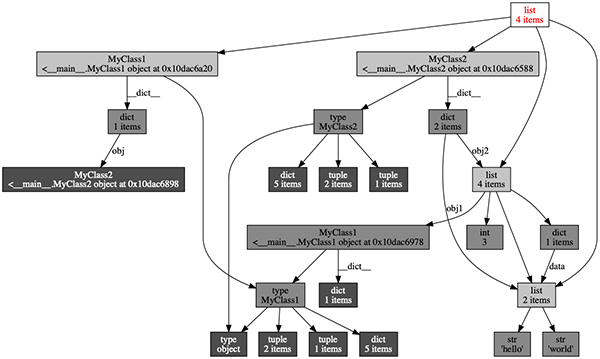
如果對象之間互相引用,有可能會形成循環引用。也就是a引用b,b引用a,見下面的代碼。
import objgraphfrom sys import getrefcount
a = {}
b = {'data':a}
a['value'] = b
objgraph.show_refs([b], filename='循環引用1.png')在這段代碼中。a和b都是一個字典,b中的一個value引用了a,而a的一個value引用了b,所以產生了一個循環引用。這段代碼的引用拓撲圖如下: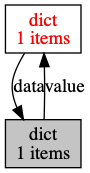
很明顯,這兩個字典是循環引用的。
不光是多個對象之間的引用可以產生循環引用,只有一個對象也可以產生循環引用,代碼如下:
a = {}
a['value'] = a
a = []
a.append(a)print(getrefcount(a))
objgraph.show_refs([a], filename='循環引用2.png')在這段代碼中,字典a的一個值是自身,拓撲圖如下:
5. 減少引用計數的兩種方法
前面一直說讓引用計數器增加的方法,那麼如何讓引用計數器減少呢?通常有如下兩種方法:
(1)用del刪除某一個引用
(2)將變量指向另外一個引用,或設置爲None,也就是引用重定向。
用del刪除某一個引用
del語句可以刪除一個變量對某一個塊內存空間的引用,也可以刪除集合對象中的某個item,代碼如下:
from sys import getrefcount
person = {'name':'Bill','age':40}
person1 = personprint(getrefcount(person1)) # 輸出3
del person # 刪除person對字典的引用print(getrefcount(person1)) # 由於引用少了一個,所以輸出爲2# print(person) # 拋出異常 # 被刪除的變量相當於重來沒定義過,所以這條語句會拋出異常
del person1['age'] # 刪除字典中key爲age的值對print(person1)引用重定向
from sys import getrefcount
value1 = [1,2,3,4]
value2 = value1
value3 = value2print(getrefcount(value2)) # 輸出4value1 = 20print(getrefcount(value2)) # 輸出3,因爲value1重新指向了20value3 = Noneprint(getrefcount(value2)) # 輸出2,因爲value3被設置爲None,也就是不指向任何內存空間,相當於空指針6. 垃圾回收
像Java、JavaScript、Python這樣的編程語言,都不允許直接通過代碼釋放變量佔用的內存,虛擬機會自動釋放這些內存區域。所以很多程序員就會認爲在這些語言中可以放心大膽地申請各種類型的變量,並不用擔心變量的釋放問題,因爲系統會自動替我們完成這些煩人的工作。
沒錯,這些語言的虛擬機會自動釋放一些不需要的內存塊,用專業術語描述就是:垃圾回收。 相當於爲系統減肥或減負。因爲不管你的計算機有多少內存,只要不斷創建新的變量,哪怕該變量只佔用了1個字節的內存空間,內存也有用完的一天。所以虛擬機會在適當的時候釋放掉不需要的內存塊。
在前面已經提到過,虛擬機會回收引用計數爲0的內存塊,因爲這些內存塊沒有任何變量指向他們,所以留着沒有任何意義。那麼到底虛擬機在什麼時候纔會回收這些內存塊呢?通常來講,虛擬機會設置一個內存閾值,一旦超過了這個閾值,就會自動啓動垃圾回收器來回收不需要的內存空間。對於不同編程語言的這個閾值是不同的。對於Python來說,會記錄其中分配對象(object allocation)和取消分配對象(object deallocation)的次數。當兩者的差值高於某個閾值時,垃圾回收纔會啓動。
我們可以通過gc模塊的get_threshold()方法,查看該閾值:
import gcprint(gc.get_threshold())輸出的結果爲:
(700, 10, 10)
這個700就是這個閾值。後面的兩個10是與分代回收相關的閾值,後面會詳細介紹。可以使用gc模塊中的set_threshold方法設置這個閾值。
由於垃圾回收是一項昂貴的工作,所以如果計算機的內存足夠大,可以將這個閾值設置的大一點,這樣可以避免垃圾回收器頻繁調用。
當然,如果覺得必要,也可以使用下面的代碼手工啓動垃圾回收器。不過要注意,手工啓動垃圾回收器後,垃圾回收器也不一定會立刻啓動,通常會在系統空閒時啓動垃圾回收器。
gc.collect()7. 變量不用了要設置爲None
有大量內存被佔用,是一定要被釋放的。但釋放這些內存有一個前提條件,就是這個內存塊不能有任何變量引用,也就是引用計數器爲0。如果有多個變量指向同一個內存塊,而且有一些變量已經不再使用了,一個好的習慣是將變量設置爲None,或用del刪除該變量。
person = {'Name':'Bill'}
value = [1,2,3]del person
value = None當刪除person變量,以及將value設置爲None後,就不會再有任何變量指向字典和列表了,所以字典和列表佔用的內存空間會被釋放。
8. 解決循環引用的回收問題
在前面講了Python GC(垃圾回收器)的一種算法策略,就是引用計數法,這種方法是Python GC採用的主要方法。不過這種策略也有其缺點。下面就看一下引用計數法的優缺點。
優點:簡單,實時(一旦爲0就會立刻釋放內存空間,毫不猶豫)
缺點: 維護性高(簡單實時,但是額外佔用了一部分資源,雖然邏輯簡單,但是麻煩。好比你吃草莓,吃一次洗一下手,而不是吃完洗手。),不能解決循環引用的問題。
那麼Python到底是如何解決循環引用釋放的問題呢?先看下面的代碼。
import objgraphfrom sys import getrefcount
a = {}
b = {'data':a}
a['value'] = bdel adel b在這段代碼中,很明顯,a和b互相引用。最後通過del語句刪除a和b。由於a和b是循環引用,如果按前面引用計數器的方法,在刪除a和b之前,兩個字典分別由兩個引用(引用計數器爲2),一個是自身引用,另一個是a或b中的value引用的自己。如果只是刪除了a和b,似乎這兩個字典各自還剩一個引用。但其實這兩個字典的內存空間已經釋放。那麼Python是如何做到的呢?
其實Python GC在檢測所有引用時,會檢測哪些引用之間是循環引用,如果檢測到某些變量之間循環引用,例如,a引用b,b引用a,就會在檢測a時,將b的引用計數器減1,在檢測b時,會將a的引用計數器減1。也就是說,Python GC當發現某些引用是循環引用後,會將這些引用的計數器多減一個1。所以這些循環引用指向的空間仍然會被釋放。
9. 分代回收
如果是多年的朋友,或一起做了多年的生意,有多年的業務往來,往往會產生一定的信任。通常來講,合作的時間越長,產生的信任感就會越深。Python GC採用的垃圾回收策略中,也會使用這種信任感作爲輔助算法,讓GC運行得更有效率。這種策略就是分代(generation)回收。
分代回收的策略有一個基本假設,就是存活的越久,越可能被經常使用,所以出於信任和效率,對這些“長壽”對象給予特殊照顧,在GC對所有對象進行檢測時,就會儘可能少地檢測這些“長壽”對象。就是現在有很多企業是免檢企業一樣,政府出於對這些企業的信任,給這些企業生產出的產品予以免檢的特殊優待。
那麼Python對什麼樣的對象會給予哪些特殊照顧呢?Python將對象共分爲3代,分別用0、1、2表示。任何新創建的對象是0代,不會給予任何特殊照顧,當某一個0代對象經過若干次垃圾回收後仍然存活,那麼就會將這個對象歸入1代對象,如果這個1代對象,再經過若干次回收後,仍然存活,就會將該對象歸爲2代對象。
在前面的描述中,涉及到一個“若干次”回收,那麼這個“若干次”是指什麼呢?在前面使用get_threshold函數獲取閾值時返回了(700,10,10),這個700就是引用計數策略的閾值,而後面的兩個10與分代策略有關。第1個10是指第0代對象經過了10次垃圾回收後仍然存在,就會將其歸爲第1代對象。第2個10是指第1代對象經過了10次垃圾回收後仍然存在,就會將其歸爲第2代對象。也就是說,GC需要執行100次,纔會掃描到第2代對象。當然,也可以通過set_threshold函數來調整這些值。
import gc
gc.set_threshold(600, 5, 6)總結
本文主要講了Python如何自動釋放內存。主要有如下3種策略:
-
引用計數策略(爲0時釋放)
-
循環引用策略(將相關引用計數器多減1)
- 分代策略(解決了GC的效率問題)
通過這些策略的共同作用,可以讓Python更加有效地管理內存,更進一步地提高Python的性能。