




博文目錄
一、索引
二、視圖
三、存儲過程
四、系統存儲過程
五、觸發器
六、事務
七、鎖
一、索引
索引提供指針以指向存儲在表中指定列的數據值,然後根據指定的次序排列這些指針,再跟隨指針到達包含該值的列。
1、什麼是索引
數據庫中的索引與書籍中的目錄相似。在一本書中,無需閱讀整本書,利用目錄就可以快速的查找到所需的信息。在數據庫中,索引使數據庫程序無須對整個表進行掃描,就可以在其中找到所需的數據。書中的目錄就是一個詞語列表,其中註明了包含各個詞的頁碼。而數據庫中的索引是某個表中一列或若干列值的集合,以及物理表示這些值得數據業的邏輯指針清單。
索引是SQL Server編排數據的內部方法,它爲SQL Server提供一種方法來編排查詢數據的路由。
索引頁是數據庫中存儲索引的數據頁。索引頁存放檢索數據行的關鍵字頁以及該數據行的地址指針。通過使用索引,可以大大提高數據庫的檢索速度,改善數據庫性能。
2、索引分類
1)唯一索引
唯一索引不允許兩行具有相同的索引值。
如果現有數據中存在重複的鍵值,則一般情況下大多數數據庫不允許創建唯一索引。當新數據使表中的鍵值重複時,數據庫也拒絕接收此數據。創建了唯一約束,將自動創建唯一索引。儘管唯一索引有助於找到信息,但是爲了獲得最佳性能,建議使用主鍵約束。
2)主鍵索引
在數據庫關係圖中爲表定義一個主鍵將自動創建主鍵索引,主鍵索引是唯一索引的特殊類型。
主建索引要求主鍵中的每個值都是唯一的。當在查詢使用主鍵索引時,它還允許快速訪問數據。
3)聚集索引
在聚集索引中,表中各行的物理順序與鍵值的邏輯(索引)順序相同。一個表中只能包含一個聚集索引。
4)非聚集索引
非聚集索引建立在索引頁上,在查詢數據是可以從索引中找到記錄存放的位置。
非聚集索引使表中各行數據存放的物理順序與鍵值的邏輯順序不匹配。聚集索引比非聚集索引有更快的數據訪問速度。在SQL Server中,一個表只能創建一個聚集索引,但可以有多個非聚集索引。設置某列爲主鍵,該列就默認爲聚集索引。
5)複合索引
在創建索引時,並不是只能對其中一列創建索引,與創建主鍵一樣,可以將多個列組合作爲索引,這種索引稱爲複合索引。
需要注意的是:只有用到複合索引的第一列或整個複合索引列作爲條件完成數據查詢時纔會用到該索引。
6)全文索引
全文索引是一種特殊類型的基於標記的功能性索引,由SQL Server中全文引擎服務創建和維護。
全文索引主要用於在大量文本中搜索字符串,此時使用全文索引的效率將大大高於使用T-SQL的LIKE關鍵字的效率。因爲全文索引的創建過程與其他類型的索引有很大的差別。
3、創建和使用索引
創建索引的方法有兩種:使用SSMS和T-SQL語句。
使用SSMS創建索引,如下:
1)products表中的名稱列創建索引

2)右擊名稱,單擊索引/鍵

3)添加索引,名字爲IX_name,單擊關閉保存表即可

4)使用索引創建查詢
select * from products with (index=IX_name) where 名稱='黃瓜';
雖然可以指定SQL Server按哪個索引進行數據查詢,但一般不需要人工指定。SQL Server將會根據所創建的索引,自動優化查詢。
使用索引可加快數據檢索速度,但爲每個列都建立索引沒有必要。因爲索引本身也是需要維護,並佔用一定的資源,可以按照以下標準選擇建立索引的列。
頻繁搜索的列;
經常用於查詢選擇的列;
經常排序、分組的列;
- 經常用於連接的列(主鍵/外鍵);
不要使用下面的列創建索引:
僅包含幾個不同值的列;
- 表中僅包含幾行;
二、視圖
視圖是保存在數據庫中的select查詢。因此,對查詢指定的大多數操作也可以在視圖上進行。使用視圖的原因有兩個,其一是處於安全考慮,用戶不必看到整個數據庫結構,而隱藏部分數據;其二是符合用戶日常業務邏輯,使其對數據更容易理解。
1、什麼是視圖
視圖是另一種查看數據庫中一個或多個表中的數據的方法。視圖是一種虛擬表,通常是作爲來自一個或多個表的行或列的子集創建的。當然,視圖也可以包含全部的行和列。但是,視圖並不是數據庫中存儲的數據值的集合,它的行和列來自查詢中引用的表。在執行時,視圖直接顯示來自表中的數據。
視圖充當着查詢中指定的表的篩選器。定義視圖的查詢可以基於一個或多個表,也可以基於其他視圖、當前數據庫或其他數據庫。
如下圖所示,以表T和表T1爲例,該視圖可以包含這些表中的全部列或選定的部分列。如下圖所示爲一個用表T的A列和B列及表T1的B1、C1和D1列創建的視圖:
視圖通常用來進行以下三種操作:
篩選表中的行;
防止未經許可的用戶訪問敏感的信息;
- 將多個物理數據表抽象爲一個邏輯數據表;
1)使用視圖帶來的好處
對最終用戶的好處:
- 結果更容易理解;
- 獲得數據更容易;
對開發人員的好處:
- 限制數據檢索更容易;
- 維護應用程序更方便;
2、創建和使用視圖
1)創建視圖
在SQL Server中,創建視圖的方法有兩種:使用SSMS和使用T-SQL語句。
①展開數據庫test,如圖所示,右擊“視圖”,在彈出的快捷菜單中選擇“新建視圖”命令(自行創建多個表插入數據)
②將A、B、C三張表添加出來
③選擇希望看到列:學員名稱、學員年齡、成績,然後中下方自動生成T-SQL語句,按“crtl+R”快捷鍵執行語句
④選擇T-SQL語句按“crtl+R”快捷鍵執行即可
2)使用視圖的注意事項
每個視圖可以使用多個表;
與查詢相似,一個視圖可以嵌套另一個視圖,最好不要超過三層;
- 視圖定義中的select語句不能包含以下內容:
order by子句,除非子啊select語句的選擇列表中也有一個TOP子句;
into關鍵字;
引用臨時表或表變量;
三、存儲過程
SQL Server使用存儲過程來避免遠程發送並執行SQL代碼帶來的安全隱患。
1、爲什麼需要存儲過程
當今的軟件大多應用於網絡中,而一般應用程序所運用的數據保存在數據庫中。在沒有使用存儲過程的數據庫應用程序中,用戶大多從本地極端及客戶端通過網絡向服務器端發送SQL代碼編寫的請求,服務器端對接收到SQL代碼進行語法編譯後執行,並經指定結果傳送回客戶端,再由客戶端的應用軟件處理後輸出。如果開發者對服務器的安全性考慮不全面,就會爲非法者提供盜取數據的機會。如下圖所示: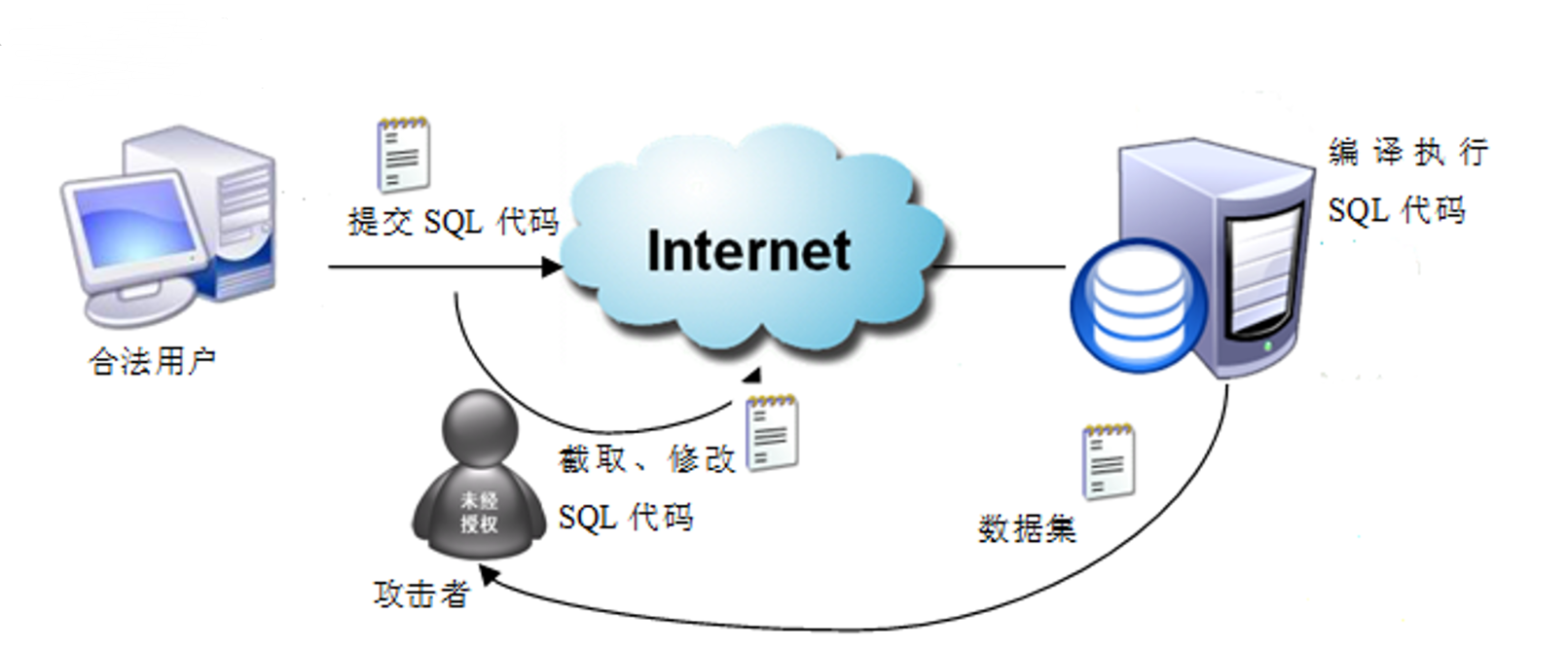
未經授權的非法者在網絡中截取用戶想服務器發送的SQL代碼,改寫後的惡意SQL代碼提交到服務器編譯並執行,最後非法者就比較容易地獲得他所需的數據。
從圖中,我們可以看到應用程序執行的過程是不安全的,主要在於以下幾個方面:
數據不安全:網絡傳送SQL代碼,容易被未經授權者截取;
每次提交SQL代碼都要經過語法編譯後再執行,影響應用程序的運行性能;
- 網絡流量大。對於反覆執行的相同SQL代碼,將會在網絡上多次傳送,增加網絡傳輸流量;
爲了解決這些問題,我們可以採用存儲過程把對數據庫操作的SQL代碼預先編譯好並保存在服務器端,用戶只需在本機上輸入要執行的存儲過程名稱和必要的數據就可以直接調用執行存儲過程完成行管的操作。這樣。既減少了網絡傳輸流量,又能保證應用程序的運行性能,同時也防止了未經授權者想截獲SQL代碼的行爲。
2、什麼是存儲過程
存儲過程是SQL語句和控制語句的預編譯集合,保存在數據庫中,可由應用程序調用執行,而且允許用戶聲明變量,邏輯控制語句及其他強大的編程功能。
存儲過程可包含邏輯控制語句和數據操作語句,可以接收參數、輸出參數、返回單個或多個結果集及返回值。
1)使用存儲過程的優點:
存儲過程的優點如下:
模塊化程序設計;
執行速度快、效率高;
減少網絡流量;
- 具有良好的安全性;
2)存儲過程分爲以下兩類
- 系統存儲過程;
- 用戶自定義的存儲過程;
四、系統存儲過程
SQL Server提供系統存儲過程,它們是一組預編譯的T-SQL語句。系統存儲過程提供了管理數據庫和更新表的機制,並充當從系統表中檢索信息的快捷方式。
通過配置SQL Server,可以生成對象、用戶、權限的信息和定義,這些信息和定義存儲在系統表中。每個數據庫分別有一個包含配置信息的系統表集,用戶數據庫的系統表是在創建數據庫時自動創建的,用戶可以通過系統存儲過程訪問和更新系統表。
1、常用的系統存儲過程
SQL Server的系統存儲過程的名稱以“sp-”開頭,並存放在Resource數據庫中。系統管理員擁有這些存儲過程的使用權限。可以在任何數據庫中運行系統存儲過程,但執行的結果會反映在當前數據庫中。
示例如下:
<!--顯示數據庫-->
exec sp_databases;
<!--顯示某個數據庫對象的信息-->
exec sp_help A;
<!--顯示所有數據庫的信息-->
exec sp_helpdb;
<!--更改數據庫名字-->
exec sp_renamedb 'xsh','benet';
<!--顯示products表的約束-->
exec sp_helpconstraint products;
<!--顯示products表的索引-->
exec sp_helpindex products;上面示例的輸出結果集較多,在此不一一列舉,請自行逐句運行,查看相應的輸出結果。
2、常用的擴展存儲過程
根據系統存儲過程的不同作用,系統存儲過程可以分爲不同類。擴展存儲過程是SQL Server提供的各類系統存儲過程中的一類。
擴展存儲過程允許使用其他編程語言(如 C##語言)創建外部存儲過程,爲數據庫用戶提供從SQL Server實例到外部程序的接口,以便進行各種維護活動。它通常以“xp_”開頭,以DLL形式單獨存在。
一個常用的擴展存儲過程爲xp_cmdshell,它可以完成DOS命令下的一些操作,如創建文件夾、列出文件夾列表等,其語法如下:
開啓系統cmdshell功能
<!--開啓系統cmdshell功能-->
exec sp_configure 'show advanced options',1
reconfigure
exec sp_configure 'xp_cmdshell',1
reconfigure;<!--創建目錄-->
exec xp_cmdshell 'mkdir D:\test', no_output;
<!--顯示創建目錄-->
exec xp_cmdshell 'dir d:\';
五、觸發器
觸發器是一種特殊類型的存儲過程,當表中的數據發生更新時將自動調用,以響應INSERT、UPDATE或DELETE語句。
1、什麼是觸發器
1)觸發器的概念
觸發器是在對錶進行插入、更新或刪除操作時自動執行的存儲過程。觸發器通常用於強制業務規則,是一種高級約束,可以定義比用CHECK約束更爲複雜的約束,可以行發雜的SQL語句(如IF/WHILE/CASE),可引用其他表中的列。觸發器主要是通過事件進行觸發而被執行的,而存儲過程可以通過存儲過程名稱而被直接調用。當對某一表進行修改,,如UPDATE、INSERT和DELETE這些操作時,SQL Server會自動執行觸發器所定義的SQL語句,從而確保對數據的處理必須符合由這些SQL語句所定義的規則。由此觸發器可分爲以下幾種:
- INSERT觸發器:當向表中插入數據時觸發,自動執行觸發器定義的SQL語句;
- UPDATE觸發器:當更新表中某列、多列時觸發,自動執行觸發器所定義的SQL語句;
- DELETE觸發器:當刪除表中記錄時觸發,自動執行觸發器定義的SQL語句。
2)deleted表和insertd表

2、觸發器的作用
觸發器的主要作用是,實現由主鍵和外鍵所不能保證的複雜的參照完整性和數據的一致性。
3、觸發器的功能
- 強化約束;
- 跟蹤變化;
- 級聯運行;
4、如何創建觸發器
使用T-SQL語句創建觸發器的語法如下:
CREATE TRIGGER trigger_name
ON table_name
[WITH ENCRYPTION]
FOR { [DELETE, INSERT, UPDATE] }
AS SQL語句
創建觸發器時需要注意以下問題:
CREATE TRIGGER必須是批處理中的第一條語句,並且只能應用到一個表中;
觸發器只能在當前的數據庫中創建,不過觸發器可以引用當前數據庫的外部對象;
- 在同一條CREATE TRIGGER語句中,可以爲多種用戶操作(如INSERT和UPDATE)定義相同的觸發器操作;
六、事務
1、什麼是事務
事務是一種機制、一個操作序列,包含了一組數據庫操作命令,並且把所有的命令作爲一個整體一起向系統提交或撤銷操作請求,即這一組數據庫命令要麼都執行,要麼都不執行。因此,事務是一個不可分隔的工作邏輯單元,在數據庫系統上執行併發操作時,事務是作爲最小的控制單元來使用的,它特別適用於多用戶同時操作的數據庫系統。
事務是作爲單個邏輯工作單元執行的一系列操作。一個邏輯工作單元必須有四個屬性,即原子性、一致性、隔離性及持久性,這些特性通常簡稱爲ACID。
1)原子性
事務是一個完整的操作。事務的各元素是不可分的(原子的)。事務中的所有元素必須作爲一個整體提交或回滾。如果事務中的任何元素失敗、則整個事務將失敗。
2)一致性
當事務完成時,數據必須處於一致狀態。也就是說,在事務開始之前,數據庫中存儲的數據處於一致狀態。在正在進行的事務中,數據可能處於不一致的狀態,如數據可能有部分修改。然而,當事務成功完成時,數據必須再次回到已知的一致狀態。通過事務對數據所做的修改不能損壞數據,或者說事務不能使數據存儲處於不穩定的狀態。
3)隔離性
對數據進行修改的所有併發事務使彼此隔離的,這表明事務必須是獨立的,它不應以任何方式依賴於或影響其他事務。修改數據的事務可以在另一個使用相同數據的事務開始之前訪問這些數據,或者在另一個使用相同的數據,則直到該事務成功提交之後,對數據的修改才能生效。
4)持久性
事務的持久性指不管系統是否發生了故障,事務處理的結果都是永久的。
2、執行事務的語法
1)開始事務語法如下:
BEGIN TRANSACTION2)提交事務語法如下:
COMMIT TRANSACTION3)回滾(撤銷)事務語法如下:
ROLLBACK TRANSACTIONBEGIN TRANSACTION語句後面的SQL語句對數據庫的更新操作都將記錄在事務日誌中,直至遇到ROLLBACK TRANSACTION語句或COMMIT TRANSACTION語句。如果事務中某一操作失敗且執行ROLLBACK TRANSACTION語句,那麼在BEGIN TRANSACTION語句之後所有更新的數據都能回滾到事務開始前的狀態。如果事務中的所有操作都全部正確完成,並且使用COMMIT TRANSACTION語句向數據庫提交更新數據,那麼這時候的數據又處在新的一致狀態。
七、鎖
1、什麼是鎖
多個用戶能夠同時操縱同一個數據庫中的數據,會發生數據不一致現象。也就是說,如果沒有鎖定且多個用戶同時訪問一個數據庫,則當事務同時使用相同的數據時可能會發生問題。這些問題包括丟失、更新、髒讀、不可重複讀和幻覺讀。數據庫加鎖就是爲了解決以上的問題。
2、鎖的模式
共享鎖(S鎖):用於讀取資源所加的鎖;
排他鎖(X鎖):和其他任何鎖都不兼容,包括其他排他鎖,排他鎖用於數據修改;
- 更新鎖(U鎖):U鎖可以看作S鎖和X鎖的結合,用於更新數據,更新數據時首先需要找到被更新的數據,此時可以理解爲被查找的數據上了S鎖。當找到需要修改的數據時,需要對被修改的資源上X鎖。SQL Server通過U鎖來避免死鎖問題;
3、查看鎖的方法
使用sys.dm_tran_locks動態管理視圖;
- 使用profiler來捕捉鎖信息;
4、死鎖形成的條件
死鎖的本質是一種僵持狀態,是由多個主體對資源的爭用而導致的。要理解SQL Server中的死鎖,可以參考如下圖:
發生死鎖需要如下四個必要條件:
互斥條件;
請求和等待條件;
不剝奪條件;
- 環路等待條件;
5、預防死鎖
預防死鎖就是破壞四個必要條件中的某一個和幾個,使其不能形成死鎖,常用方法如下:
破壞互斥條件;
破壞請求和等待條件;
- 破壞不剝奪條件;
———————— 本文至此結束,感謝閱讀 ————————