




Twitter-Snowflake算法產生的背景相當簡單,爲了滿足Twitter每秒上萬條消息的請求,每條消息都必須分配一條唯一的id,這些id還需要一些大致的順序(方便客戶端排序),並且在分佈式系統中不同機器產生的id必須不同。
Snowflake算法核心
把時間戳,工作機器id,序列號組合在一起。
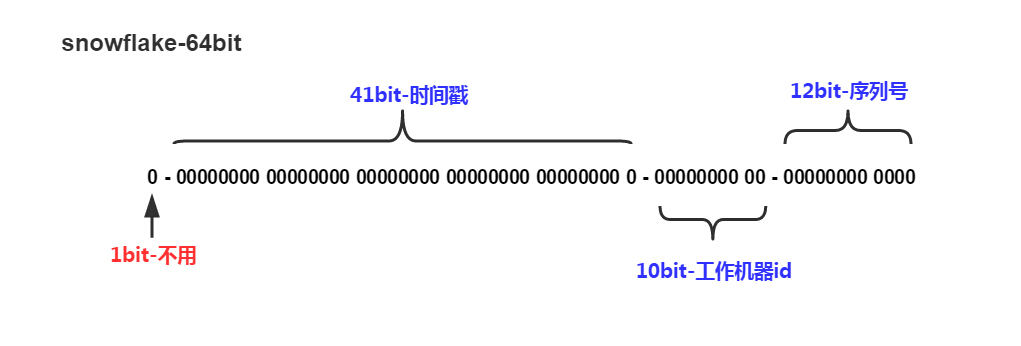
除了最高位bit標記爲不可用以外,其餘三組bit佔位均可浮動,看具體的業務需求而定。默認情況下41bit的時間戳可以支持該算法使用到2082年,10bit的工作機器id可以支持1023臺機器,序列號支持1毫秒產生4095個自增序列id。下文會具體分析。
結構爲:
0---0000000000 0000000000 0000000000 0000000000 0 --- 00000 ---00000 ---0000000000 00
在上面的字符串中,第一位爲未使用(實際上也可作爲long的符號位),接下來的41位爲毫秒級時間,然後5位datacenter標識位,5位機器ID(並不算標識符,實際是爲線程標識),然後12位該毫秒內的當前毫秒內的計數,加起來剛好64位,爲一個Long型。
這樣的好處是,整體上按照時間自增排序,並且整個分佈式系統內不會產生ID碰撞(由datacenter和機器ID作區分),並且效率較高,經測試,snowflake每秒能夠產生26萬ID左右,完全滿足需要。
**
* ID 生成策略
* 毫秒級時間41位+機器ID 10位+毫秒內序列12位。
* 0 41 51 64
+-----------+------+------+
|time |pc |inc |
+-----------+------+------+
* 最高位bit標記爲不可用
* 前41bits是以微秒爲單位的timestamp。
* 接着10bits是事先配置好的機器ID。
* 最後12bits是累加計數器。
* macheine id(10bits)標明最多只能有1024臺機器同時產生ID,sequence number(12bits)也標明1臺機器1ms中最多產生4096個ID,
*
*/
class SnowFlake{
private static $epoch = 1462264156000;
public function createID($machineId){
/*
* Time - 41 bits
*/
$time = floor(microtime(true) * 1000);
/*
* Substract custom epoch from current time
*/
$time -= SnowFlake::$epoch;
/*
* flag number - 1 bits - can not change, beacause is shoule be a positive number
*/
$suffix = 0;
/*
* Create a base and add time to it
*/
$base = decbin(pow(2,40) - 1 + $time);
//$base = sprintf("%041s", decbin($time));
/*
* Configured machine id - 10 bits - up to 512 machines
*/
$machineid = decbin(pow(2,9) - 1 + $machineId);
//$machineid = sprintf("%010s", decbin($machineId));
/*
* sequence number - 12 bits - up to 2048 random numbers per machine
*/
$random = mt_rand(1, pow(2,11)-1);
$random = decbin(pow(2,11)-1 + $random);
//$random = mt_rand(1, pow(2, 12) - 1);
//$random = sprintf("%012s", decbin($random));
/*
* 拼裝$base
*/
$base = $suffix.$base.$machineid.$random;
/*
* 講二進制的base轉換成long
*/
$base = bindec($base);
$id = sprintf('%.0f', $base);
return $id;
}
}
我這裏的PHP代碼序列號是隨機產生的,因爲我們的業務還不達不到需要有序生成的必要, 而且對於PHP來說要序列化生成必須把這個序列存儲到緩存裏面去。
詳細代碼可參考:https://github.com/twitter/snowflake

