




本文翻譯自: https://github.com/nathanmarz/storm/wiki/Tutorial
Storm是一個分佈式的、高容錯的實時計算系統。
Storm對於實時計算的的意義相當於Hadoop對於批處理的意義。Hadoop爲我們提供了Map和Reduce原語,使我們對數據進行批處理變的非常的簡單和優美。同樣,Storm也對數據的實時計算提供了簡單Spout和Bolt原語。
Storm適用的場景:
1、流數據處理:Storm可以用來用來處理源源不斷的消息,並將處理之後的結果保存到持久化介質中。
2、分佈式RPC:由於Storm的處理組件都是分佈式的,而且處理延遲都極低,所以可以Storm可以做爲一個通用的分佈式RPC框架來使用。
在這個教程裏面我們將學習如何創建Topologies, 並且把topologies部署到storm的集羣裏面去。Java將是我們主要的示範語言, 個別例子會使用python以演示storm的多語言特性。
1、準備工作
這個教程使用storm-starter項目裏面的例子。我推薦你們下載這個項目的代碼並且跟着教程一起做。先讀一下:配置storm開發環境和新建一個strom項目這兩篇文章把你的機器設置好。
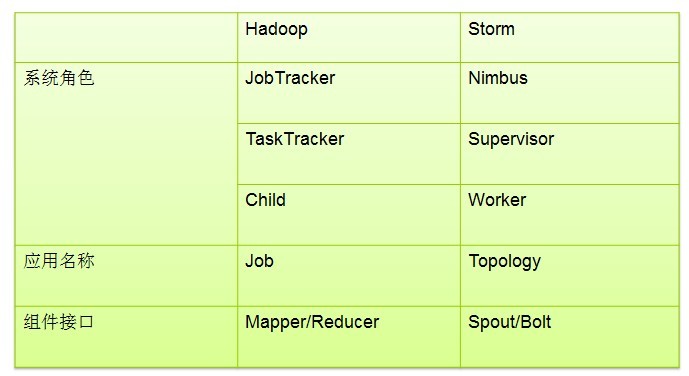
2、一個Storm集羣的基本組件
storm的集羣表面上看和hadoop的集羣非常像。但是在Hadoop上面你運行的是MapReduce的Job, 而在Storm上面你運行的是Topology。它們是非常不一樣的 — 一個關鍵的區別是: 一個MapReduce Job最終會結束, 而一個Topology運永遠運行(除非你顯式的殺掉他)。
在Storm的集羣裏面有兩種節點: 控制節點(master node)和工作節點(worker node)。控制節點上面運行一個後臺程序: Nimbus, 它的作用類似Hadoop裏面的JobTracker。Nimbus負責在集羣裏面分佈代碼,分配工作給機器, 並且監控狀態。
每一個工作節點上面運行一個叫做Supervisor的節點(類似 TaskTracker)。Supervisor會監聽分配給它那臺機器的工作,根據需要 啓動/關閉工作進程。每一個工作進程執行一個Topology(類似 Job)的一個子集;一個運行的Topology由運行在很多機器上的很多工作進程 Worker(類似 Child)組成。

storm topology結構
Storm VS MapReduce
Nimbus和Supervisor之間的所有協調工作都是通過一個Zookeeper集羣來完成。並且,nimbus進程和supervisor都是快速失敗(fail-fast)和無狀態的。所有的狀態要麼在Zookeeper裏面, 要麼在本地磁盤上。這也就意味着你可以用kill -9來殺死nimbus和supervisor進程, 然後再重啓它們,它們可以繼續工作, 就好像什麼都沒有發生過似的。這個設計使得storm不可思議的穩定。
3、Topologies
爲了在storm上面做實時計算, 你要去建立一些topologies。一個topology就是一個計算節點所組成的圖。Topology裏面的每個處理節點都包含處理邏輯, 而節點之間的連接則表示數據流動的方向。
運行一個Topology是很簡單的。首先,把你所有的代碼以及所依賴的jar打進一個jar包。然後運行類似下面的這個命令。
1 |
strom jar all-your-code.jar backtype.storm.MyTopology arg1 arg2 |
這個命令會運行主類: backtype.strom.MyTopology, 參數是arg1, arg2。這個類的main函數定義這個topology並且把它提交給Nimbus。storm jar負責連接到nimbus並且上傳jar文件。
因爲topology的定義其實就是一個Thrift結構並且nimbus就是一個Thrift服務, 有可以用任何語言創建並且提交topology。上面的方面是用JVM
-based語言提交的最簡單的方法, 看一下文章: 在生產集羣上運行topology去看看怎麼啓動以及停止topologies。
4、Stream
Stream是storm裏面的關鍵抽象。一個stream是一個沒有邊界的tuple序列。storm提供一些原語來分佈式地、可靠地把一個stream傳輸進一個新的stream。比如: 你可以把一個tweets流傳輸到熱門話題的流。
storm提供的最基本的處理stream的原語是spout和bolt。你可以實現Spout和Bolt對應的接口以處理你的應用的邏輯。
spout的流的源頭。比如一個spout可能從Kestrel隊列裏面讀取消息並且把這些消息發射成一個流。又比如一個spout可以調用twitter的一個api並且把返回的tweets發射成一個流。
通常Spout會從外部數據源(隊列、數據庫等)讀取數據,然後封裝成Tuple形式,之後發送到Stream中。Spout是一個主動的角色,在接口內部有個nextTuple函數,Storm框架會不停的調用該函數。

bolt可以接收任意多個輸入stream, 作一些處理, 有些bolt可能還會發射一些新的stream。一些複雜的流轉換, 比如從一些tweet裏面計算出熱門話題, 需要多個步驟, 從而也就需要多個bolt。 Bolt可以做任何事情: 運行函數, 過濾tuple, 做一些聚合, 做一些合併以及訪問數據庫等等。
Bolt處理輸入的Stream,併產生新的輸出Stream。Bolt可以執行過濾、函數操作、Join、操作數據庫等任何操作。Bolt是一個被動的角色,其接口中有一個execute(Tuple input)方法,在接收到消息之後會調用此函數,用戶可以在此方法中執行自己的處理邏輯。
spout和bolt所組成一個網絡會被打包成topology, topology是storm裏面最高一級的抽象(類似 Job), 你可以把topology提交給storm的集羣來運行。topology的結構在Topology那一段已經說過了,這裏就不再贅述了。
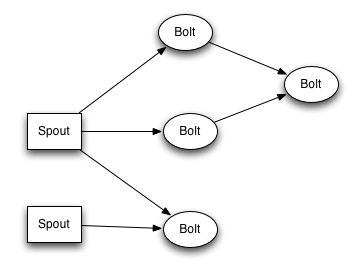 topology結構
topology結構topology裏面的每一個節點都是並行運行的。 在你的topology裏面, 你可以指定每個節點的並行度, storm則會在集羣裏面分配那麼多線程來同時計算。
一個topology會一直運行直到你顯式停止它。storm自動重新分配一些運行失敗的任務, 並且storm保證你不會有數據丟失, 即使在一些機器意外停機並且消息被丟掉的情況下。
5、數據模型(Data Model)
storm使用tuple來作爲它的數據模型。每個tuple是一堆值,每個值有一個名字,並且每個值可以是任何類型, 在我的理解裏面一個tuple可以看作一個沒有方法的java對象。總體來看,storm支持所有的基本類型、字符串以及字節數組作爲tuple的值類型。你也可以使用你自己定義的類型來作爲值類型, 只要你實現對應的序列化器(serializer)。
一個Tuple代表數據流中的一個基本的處理單元,例如一條cookie日誌,它可以包含多個Field,每個Field表示一個屬性。

Tuple本來應該是一個Key-Value的Map,由於各個組件間傳遞的tuple的字段名稱已經事先定義好了,所以Tuple只需要按序填入各個Value,所以就是一個Value List。
一個沒有邊界的、源源不斷的、連續的Tuple序列就組成了Stream。

topology裏面的每個節點必須定義它要發射的tuple的每個字段。 比如下面這個bolt定義它所發射的tuple包含兩個字段,類型分別是: double和triple。
publicclassDoubleAndTripleBoltimplementsIRichBolt {
privateOutputCollectorBase _collector;
@Override
publicvoidprepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
_collector = collector;
}
@Override
publicvoidexecute(Tuple input) {
intval = input.getInteger(0);
_collector.emit(input,newValues(val*2, val*3));
_collector.ack(input);
}
@Override
publicvoidcleanup() {
}
@Override
publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(newFields(“double”,”triple”));
}
}
declareOutputFields方法定義要輸出的字段 : ["double", "triple"]。這個bolt的其它部分我們接下來會解釋。
6、一個簡單的Topology
讓我們來看一個簡單的topology的例子, 我們看一下storm-starter裏面的ExclamationTopology:
TopologyBuilder builder =newTopologyBuilder();
builder.setSpout(1,newTestWordSpout(),10);
builder.setBolt(2,newExclamationBolt(),3)
.shuffleGrouping(1);
builder.setBolt(3,newExclamationBolt(),2)
.shuffleGrouping(2);
這個Topology包含一個Spout和兩個Bolt。Spout發射單詞, 每個bolt在每個單詞後面加個”!!!”。這三個節點被排成一條線: spout發射單詞給第一個bolt, 第一個bolt然後把處理好的單詞發射給第二個bolt。如果spout發射的單詞是["bob"]和["john"], 那麼第二個bolt會發射["bolt!!!!!!"]和["john!!!!!!"]出來。
我們使用setSpout和setBolt來定義Topology裏面的節點。這些方法接收我們指定的一個id, 一個包含處理邏輯的對象(spout或者bolt), 以及你所需要的並行度。
這個包含處理的對象如果是spout那麼要實現IRichSpout的接口, 如果是bolt,那麼就要實現IRichBolt接口.
最後一個指定並行度的參數是可選的。它表示集羣裏面需要多少個thread來一起執行這個節點。如果你忽略它那麼storm會分配一個線程來執行這個節點。
setBolt方法返回一個InputDeclarer對象, 這個對象是用來定義Bolt的輸入。 這裏第一個Bolt聲明它要讀取spout所發射的所有的tuple — 使用shuffle grouping。而第二個bolt聲明它讀取第一個bolt所發射的tuple。shuffle grouping表示所有的tuple會被隨機的分發給bolt的所有task。給task分發tuple的策略有很多種,後面會介紹。
如果你想第二個bolt讀取spout和第一個bolt所發射的所有的tuple, 那麼你應該這樣定義第二個bolt:
builder.setBolt(3,newExclamationBolt(),5)
.shuffleGrouping(1)
.shuffleGrouping(2);
讓我們深入地看一下這個topology裏面的spout和bolt是怎麼實現的。Spout負責發射新的tuple到這個topology裏面來。TestWordSpout從["nathan", "mike", "jackson", "golda", "bertels"]裏面隨機選擇一個單詞發射出來。TestWordSpout裏面的nextTuple()方法是這樣定義的:
public void nextTuple() {
Utils.sleep(100);
finalString[] words =newString[] {“nathan”,”mike”,
“jackson”,”golda”,”bertels”};
finalRandom rand =newRandom();
finalString word = words[rand.nextInt(words.length)];
_collector.emit(newValues(word));
}
可以看到,實現很簡單。
ExclamationBolt把”!!!”拼接到輸入tuple後面。我們來看下ExclamationBolt的完整實現。
publicstaticclassExclamationBoltimplementsIRichBolt {
OutputCollector _collector;
publicvoidprepare(Map conf, TopologyContext context,
OutputCollector collector) {
_collector = collector;
}
publicvoidexecute(Tuple tuple) {
_collector.emit(tuple,newValues(tuple.getString(0) +”!!!”));
_collector.ack(tuple);
}
publicvoidcleanup() {
}
publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(newFields(“word”));
}
}
prepare方法提供給bolt一個Outputcollector用來發射tuple。Bolt可以在任何時候發射tuple — 在prepare, execute或者cleanup方法裏面, 或者甚至在另一個線程裏面異步發射。這裏prepare方法只是簡單地把OutputCollector作爲一個類字段保存下來給後面execute方法使用。
execute方法從bolt的一個輸入接收tuple(一個bolt可能有多個輸入源). ExclamationBolt獲取tuple的第一個字段,加上”!!!”之後再發射出去。如果一個bolt有多個輸入源,你可以通過調用Tuple#getSourceComponent方法來知道它是來自哪個輸入源的。
execute方法裏面還有其它一些事情值得一提: 輸入tuple被作爲emit方法的第一個參數,並且輸入tuple在最後一行被ack。這些呢都是Storm可靠性API的一部分,後面會解釋。
cleanup方法在bolt被關閉的時候調用, 它應該清理所有被打開的資源。但是集羣不保證這個方法一定會被執行。比如執行task的機器down掉了,那麼根本就沒有辦法來調用那個方法。cleanup設計的時候是被用來在local mode的時候才被調用(也就是說在一個進程裏面模擬整個storm集羣), 並且你想在關閉一些topology的時候避免資源泄漏。
最後,declareOutputFields定義一個叫做”word”的字段的tuple。
以local mode運行ExclamationTopology
讓我們看看怎麼以local mode運行ExclamationToplogy。
storm的運行有兩種模式: 本地模式和分佈式模式. 在本地模式中, storm用一個進程裏面的線程來模擬所有的spout和bolt. 本地模式對開發和測試來說比較有用。 你運行storm-starter裏面的topology的時候它們就是以本地模式運行的, 你可以看到topology裏面的每一個組件在發射什麼消息。
在分佈式模式下, storm由一堆機器組成。當你提交topology給master的時候, 你同時也把topology的代碼提交了。master負責分發你的代碼並且負責給你的topolgoy分配工作進程。如果一個工作進程掛掉了, master節點會把認爲重新分配到其它節點。關於如何在一個集羣上面運行topology, 你可以看看Running topologies on a production cluster文章。
下面是以本地模式運行ExclamationTopology的代碼:
Config conf =newConfig();
conf.setDebug(true);
conf.setNumWorkers(2);
LocalCluster cluster =newLocalCluster();
cluster.submitTopology(“test”, conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology(“test”);
cluster.shutdown();
首先, 這個代碼定義通過定義一個LocalCluster對象來定義一個進程內的集羣。提交topology給這個虛擬的集羣和提交topology給分佈式集羣是一樣的。通過調用submitTopology方法來提交topology, 它接受三個參數:要運行的topology的名字,一個配置對象以及要運行的topology本身。
topology的名字是用來唯一區別一個topology的,這樣你然後可以用這個名字來殺死這個topology的。前面已經說過了, 你必須顯式的殺掉一個topology, 否則它會一直運行。
Conf對象可以配置很多東西, 下面兩個是最常見的:
- TOPOLOGY_WORKERS(setNumWorkers) 定義你希望集羣分配多少個工作進程給你來執行這個topology. topology裏面的每個組件會被需要線程來執行。每個組件到底用多少個線程是通過setBolt和setSpout來指定的。這些線程都運行在工作進程裏面. 每一個工作進程包含一些節點的一些工作線程。比如, 如果你指定300個線程,60個進程, 那麼每個工作進程裏面要執行6個線程, 而這6個線程可能屬於不同的組件(Spout, Bolt)。你可以通過調整每個組件的並行度以及這些線程所在的進程數量來調整topology的性能。
- TOPOLOGY_DEBUG(setDebug), 當它被設置成true的話, storm會記錄下每個組件所發射的每條消息。這在本地環境調試topology很有用, 但是在線上這麼做的話會影響性能的。
感興趣的話可以去看看Conf對象的Javadoc去看看topology的所有配置。
可以看看創建一個新storm項目去看看怎麼配置開發環境以使你能夠以本地模式運行topology.
運行中的Topology主要由以下三個組件組成的:
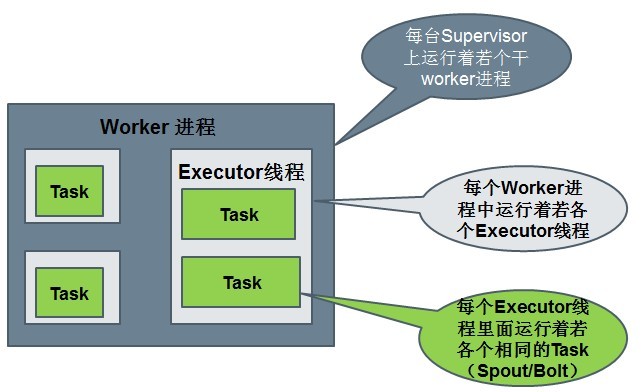
Spout或者Bolt的Task個數一旦指定之後就不能改變了,而Executor的數量可以根據情況來進行動態的調整。默認情況下# executor = #tasks即一個Executor中運行着一個Task
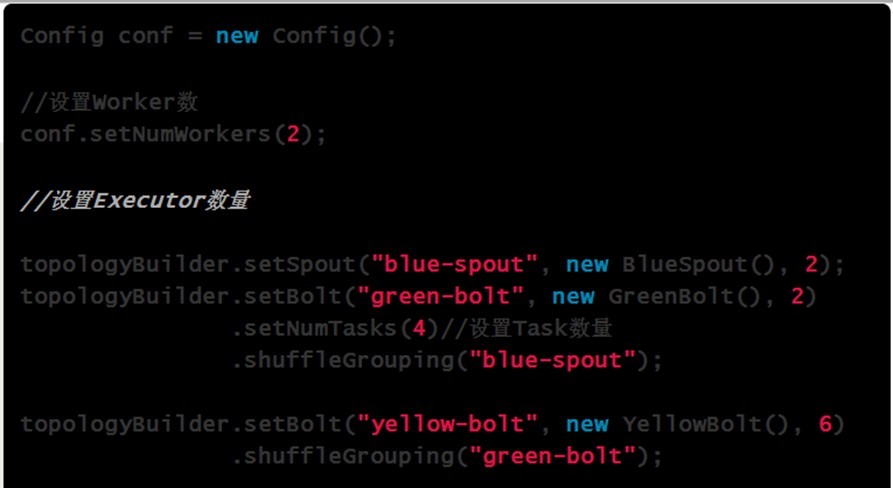


7、流分組策略(Stream grouping)
流分組策略告訴topology如何在兩個組件之間發送tuple。 要記住, spouts和bolts以很多task的形式在topology裏面同步執行。如果從task的粒度來看一個運行的topology, 它應該是這樣的:
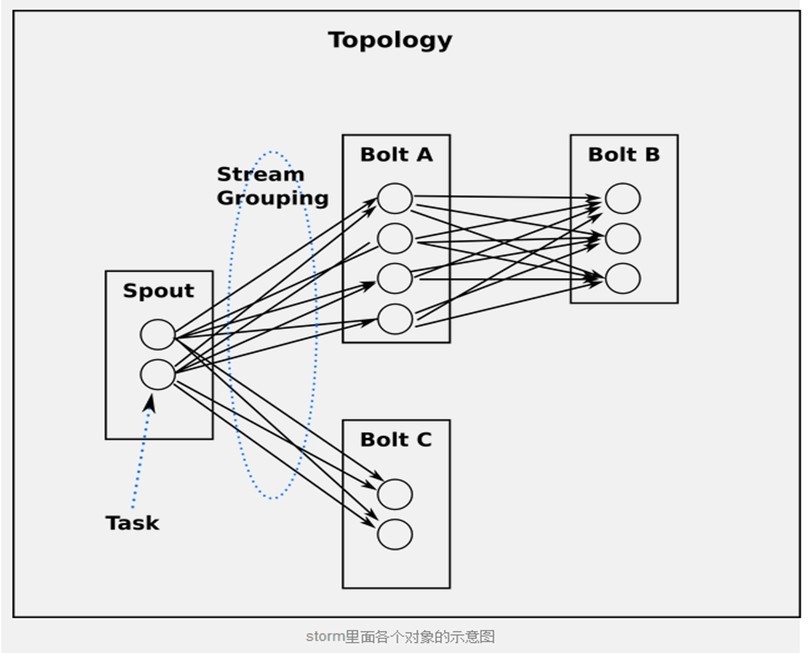
從task角度來看topology
當Bolt A的一個task要發送一個tuple給Bolt B, 它應該發送給Bolt B的哪個task呢?
stream grouping專門回答這種問題的。在我們深入研究不同的stream grouping之前, 讓我們看一下storm-starter裏面的另外一個topology。WordCountTopology讀取一些句子, 輸出句子裏面每個單詞出現的次數.
TopologyBuilder builder =newTopologyBuilder();
builder.setSpout(1,newRandomSentenceSpout(),5);
builder.setBolt(2,newSplitSentence(),8)
.shuffleGrouping(1);
builder.setBolt(3,newWordCount(),12)
.fieldsGrouping(2,newFields(“word”));
SplitSentence對於句子裏面的每個單詞發射一個新的tuple, WordCount在內存裏面維護一個單詞->次數的mapping, WordCount每收到一個單詞, 它就更新內存裏面的統計狀態。
有好幾種不同的stream grouping:
- 最簡單的grouping是shuffle grouping, 它隨機發給任何一個task。上面例子裏面RandomSentenceSpout和SplitSentence之間用的就是shuffle grouping, shuffle grouping對各個task的tuple分配的比較均勻。
- 一種更有趣的grouping是fields grouping, SplitSentence和WordCount之間使用的就是fields grouping, 這種grouping機制保證相同field值的tuple會去同一個task, 這對於WordCount來說非常關鍵,如果同一個單詞不去同一個task, 那麼統計出來的單詞次數就不對了。
fields grouping是stream合併,stream聚合以及很多其它場景的基礎。在背後呢, fields grouping使用的一致性哈希來分配tuple的。
還有一些其它類型的stream grouping. 你可以在Concepts一章裏更詳細的瞭解。
下面是一些常用的 “路由選擇” 機制:
Storm的Grouping即消息的Partition機制。當一個Tuple被髮送時,如何確定將它發送個某個(些)Task來處理??
8、使用別的語言來定義Bolt
Bolt可以使用任何語言來定義。用其它語言定義的bolt會被當作子進程(subprocess)來執行, storm使用JSON消息通過stdin/stdout來和這些subprocess通信。這個通信協議是一個只有100行的庫, storm團隊給這些庫開發了對應的Ruby, Python和Fancy版本。
下面是WordCountTopology裏面的SplitSentence的定義:
publicstaticclassSplitSentenceextendsShellBoltimplementsIRichBolt {
publicSplitSentence() {
super(“python”,”splitsentence.py”);
}
publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(newFields(“word”));
}
}
SplitSentence繼承自ShellBolt並且聲明這個Bolt用python來運行,並且參數是: splitsentence.py。下面是splitsentence.py的定義:
importstorm
classSplitSentenceBolt(storm.BasicBolt):
defprocess(self, tup):
words=tup.values[0].split(” “)
forwordinwords:
storm.emit([word])
SplitSentenceBolt().run()
更多有關用其它語言定義Spout和Bolt的信息, 以及用其它語言來創建topology的 信息可以參見: Using non-JVM languages with Storm.
9、可靠的消息處理
在這個教程的前面,我們跳過了有關tuple的一些特徵。這些特徵就是storm的可靠性API: storm如何保證spout發出的每一個tuple都被完整處理。看看《storm如何保證消息不丟失》以更深入瞭解storm的可靠性API.
Storm允許用戶在Spout中發射一個新的源Tuple時爲其指定一個MessageId,這個MessageId可以是任意的Object對象。多個源Tuple可以共用同一個MessageId,表示這多個源Tuple對用戶來說是同一個消息單元。Storm的可靠性是指Storm會告知用戶每一個消息單元是否在一個指定的時間內被完全處理。完全處理的意思是該MessageId綁定的源Tuple以及由該源Tuple衍生的所有Tuple都經過了Topology中每一個應該到達的Bolt的處理。
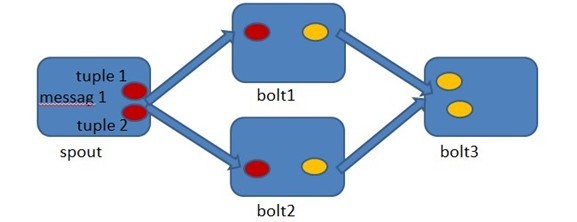
在Spout中由message 1綁定的tuple1和tuple2分別經過bolt1和bolt2的處理,然後生成了兩個新的Tuple,並最終流向了bolt3。當bolt3處理完之後,稱message 1被完全處理了。
Storm中的每一個Topology中都包含有一個Acker組件。Acker組件的任務就是跟蹤從Spout中流出的每一個messageId所綁定的Tuple樹中的所有Tuple的處理情況。如果在用戶設置的最大超時時間內這些Tuple沒有被完全處理,那麼Acker會告訴Spout該消息處理失敗,相反則會告知Spout該消息處理成功。
那麼Acker是如何記錄Tuple的處理結果呢??
A xor A = 0.
A xor B…xor B xor A = 0,其中每一個操作數出現且僅出現兩次。
在Spout中,Storm系統會爲用戶指定的MessageId生成一個對應的64位的整數,作爲整個Tuple Tree的RootId。RootId會被傳遞給Acker以及後續的Bolt來作爲該消息單元的唯一標識。同時,無論Spout還是Bolt每次新生成一個Tuple時,都會賦予該Tuple一個唯一的64位整數的Id。
當Spout發射完某個MessageId對應的源Tuple之後,它會告訴Acker自己發射的RootId以及生成的那些源Tuple的Id。而當Bolt處理完一個輸入Tuple並產生出新的Tuple時,也會告知Acker自己處理的輸入Tuple的Id以及新生成的那些Tuple的Id。Acker只需要對這些Id進行異或運算,就能判斷出該RootId對應的消息單元是否成功處理完成了。
10、單機版安裝指南
環境:centos 6.4
安裝步驟請參考:http://blog.sina.com.cn/s/blog_546abd9f0101cce8.html
要注意上面的本地模式運行WordCount其實並沒有使用到上述安裝的工具,只是一個storm的虛擬環境下測試demo。那我們怎樣將程序運行在剛剛搭建的單機版的環境裏面呢,
很簡單,官方的例子:
注意看官方實例中WordCountTopology類如果不帶參數其實是執行的本地模式,也就是剛說的虛擬的環境,帶上參數就是將jar發送到了storm執行了。
首先弄好環境:
啓動zookeeper:
/usr/local/zookeeper/bin/zkServer.sh 單機版直接啓動,不用修改什麼配置,如集羣就需要修改zoo.cfg另一篇文章會講到。
配置storm:
文件在/usr/local/storm/conf/storm.yaml
內容:
storm.zookeeper.servers:
- 127.0.0.1
storm.zookeeper.port: 2181
nimbus.host: “127.0.0.1″
storm.local.dir: “/tmp/storm”
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
這個腳本文件寫的不咋地,所以在配置時一定注意在每一項的開始時要加空格,冒號後也必須要加空格,否則storm就不認識這個配置文件了。
說明一下:storm.local.dir表示storm需要用到的本地目錄。nimbus.host表示那一臺機器是master機器,即nimbus。storm.zookeeper.servers表示哪幾臺機器是zookeeper服務器。storm.zookeeper.port表示zookeeper的端口號,這裏一定要與zookeeper配置的端口號一致,否則會出現通信錯誤,切記切記。當然你也可以配superevisor.slot.port,supervisor.slots.ports表示supervisor節點的槽數,就是最多能跑幾個worker進程(每個sprout或bolt默認只啓動一個worker,但是可以通過conf修改成多個)。
執行:
# bin/storm nimbus(啓動主節點)
# bin/storm supervisor(啓動從節點)
執行命令:# storm jar StormStarter.jar storm.starter.WordCountTopology test
此命令的作用就是用storm將jar發送給storm去執行,後面的test是定義的toplogy名稱。
搞定,任務就發送到storm上運行起來了,還可以通過命令:
# bin/storm ui
然後執行 jps 會看到 3 個進程:zookeeper 、nimbus、 supervisor
啓動ui,可以通過瀏覽器, ip:8080/ 查看運行i情況。
配置後,執行 storm jar sm.jar main.java.TopologyMain words.txt
也許會報:java.lang.NoClassDefFoundError: clojure.core.protocols$seq_reduce
這是由於我使用了 oracle JDK 1.7 的緣故,換成 open JDK 1.6 就正常了,
1 |
su -c "yum
install java-1.6.0-openjdk-devel" |
具體參考:https://github.com/technomancy/leiningen/issues/676
測試代碼:
https://github.com/storm-book/examples-ch02-getting_started
運行結果:
storm jar sm.jar main.java.TopologyMain words.txt
…
6020 [main] INFO backtype.storm.messaging.loader – Shutdown receiving-thread: [Getting-Started-Toplogie-1-1374946750, 4]
6020 [main] INFO backtype.storm.daemon.worker – Shut down receive thread
6020 [main] INFO backtype.storm.daemon.worker – Terminating zmq context
6020 [main] INFO backtype.storm.daemon.worker – Shutting down executors
OK:is
6021 [main] INFO backtype.storm.daemon.executor – Shutting down executor word-counter:[2 2]
OK:an
OK:storm
OK:simple
6023 [Thread-16] INFO backtype.storm.util – Async loop interrupted!
OK:application
OK:but
OK:very
OK:powerfull
OK:really
OK:
OK:StOrm
OK:is
OK:great
6038 [Thread-15] INFO backtype.storm.util – Async loop interrupted!
– Word Counter [word-counter-2] –
really: 1
but: 1
application: 1
is: 2
great: 2
are: 1
test: 1
simple: 1
an: 1
powerfull: 1
storm: 3
very: 1
6043 [main] INFO backtype.storm.daemon.executor – Shut down executor word-counter:[2 2]
6044 [main] INFO backtype.storm.daemon.executor – Shutting down executor word-normalizer:[3 3]
6045 [Thread-18] INFO backtype.storm.util – Async loop interrupted!
6052 [Thread-17] INFO backtype.storm.util – Async loop interrupted!
6056 [main] INFO backtype.storm.daemon.executor – Shut down executor word-normalizer:[3 3]
6056 [main] INFO backtype.storm.daemon.executor – Shutting down executor word-reader:[4 4]
6058 [Thread-19] INFO backtype.storm.util – Async loop interrupted!
其它參考地址:
https://github.com/philipgao/storm-demo
http://blog.sina.com.cn/s/blog_8ae7b3fe010124mr.html
分佈式安裝指南:
http://hitina.lofter.com/post/a8c5e_136579#
注:本文主體部分來源於 徐明明同學 翻譯的 storm wiki 教程,
http://xumingming.sinaapp.com/138/twitter-storm%E5%85%A5%E9%97%A8/
原文地址:http://my.oschina.net/leejun2005/blog/147607?from=20130804

