




卷積運算與相關運算
在計算機視覺領域,卷積核、濾波器通常爲較小尺寸的矩陣,比如3×33×3。從這個角度看,多層卷積是在進行逐層映射,整體構成一個複雜函數,訓練過程是在學習每個局部映射所需的權重,訓練過程可以看成是函數擬合的過程。
從模版匹配的角度理解。 前面我們已經知道,卷積與相關在計算上可以等價,相關運算常用模板匹配,即認爲卷積覈定義了某種模式,卷積(相關)運算是在計算每個位置與該模式的相似程度,或者說每個位置具有該模式的分量有多少,當前位置與該模式越像,響應越強。下圖爲圖像層面的模板匹配(圖片來自鏈接),右圖爲響應圖,可見狗頭位置的響應最大。當然,也可以在特徵層面進行模版匹配,卷積神經網絡中的隱藏層即可以看成是在特徵層面進行模板匹配。這時,響應圖中每個元素代表的是當前位置與該模式的相似程度,單看響應圖其實看不出什麼,可以想像每個位置都有個“狗頭”,越亮的地方越像“狗頭”,若給定模板甚至可以通過反捲積的方式將圖像復原出來。這裏多說一句,我們真的是想把圖像復原出來嗎,我們希望的是在圖像中找到需要的模式,若是通過一個非線性函數,將響應圖中完全不像“狗頭”的地方清零,而將像“狗頭”的地方保留,然後再將圖像復原,發現復原圖中只有一個“狗頭”,這是不是更美好——因爲我們明確了圖像中的模式,而減少了其他信息的干擾!

本篇文章將傾向於從第2個角度來理解卷積神經網絡。
卷積能抽取特徵
上一節中提到了“狗頭”模板,如果把卷積覈定爲“狗頭”模板會有什麼問題?將缺乏靈活性,或者說泛化能力不夠,因爲狗的姿態變化是多樣的,如果直接把卷積覈定義得這麼“死板”,狗換個姿勢或者換一條狗就不認得了。
那麼,爲了適應目標的多樣性,卷積核該怎麼設計呢?這個問題,我們在下一節回答,這裏先看看人工定義的卷積核是如何提取特徵的。
以下圖sobel算子爲例(圖片來自鏈接),對圖像進行卷積,獲得圖像的邊緣響應圖,當我們看到響應圖時,要知道圖中每個位置的響應代表着這個位置在原圖中有個形似sobel算子的邊緣,信息被壓縮了,響應圖裏的一個數值其實代表了這個位置有個相應強度的sobel邊緣模式,我們通過卷積抽取到了特徵。

人工能定義邊緣這樣的簡單卷積核來描述簡單模式,但是更復雜的模式怎麼辦,像人臉、貓、狗等等,儘管每個狗長得都不一樣,但是我們即使從未見過某種狗,當看到了也會知道那是狗,所以對於狗這個羣體一定是存在着某種共有的模式,讓我們人能夠辨認出來,但問題是這種模式如何定義?在上一節,我們知道“死板”地定義個狗的模板是不行的,其缺乏泛化能力,我們該怎麼辦?
通過多層卷積,來將簡單模式組合成複雜模式,通過這種靈活的組合來保證具有足夠的表達能力和泛化能力。
多層卷積能抽取複雜特徵
爲了直觀,我們先上圖,圖片出自論文《Visualizing and Understanding Convolutional Networks》,作者可視化了卷積神經網絡每層學到的特徵,當輸入給定圖片時,每層學到的特徵如下圖所示,注意,我們上面提到過每層得到的特徵圖直接觀察是看不出什麼的,因爲其中每個位置都代表了某種模式,需要在這個位置將模式復現出來才能形成人能夠理解的圖像,作者在文中將這個復現過程稱之爲deconvolution,詳細查看論文(前文已經有所暗示,讀者可以先獨自思考下復現會怎麼做)。

從圖中可知,淺層layer學到的特徵爲簡單的邊緣、角點、紋理、幾何形狀、表面等,到深層layer學到的特徵則更爲複雜抽象,爲狗、人臉、鍵盤等等,有幾點需要注意:
卷積神經網絡每層的卷積核權重是由數據驅動學習得來,不是人工設計的,人工只能勝任簡單卷積核的設計,像邊緣,但在邊緣響應圖之上設計出能描述複雜模式的卷積核則十分困難。
數據驅動卷積神經網絡逐層學到由簡單到複雜的特徵(模式),複雜模式是由簡單模式組合而成,比如Layer4的狗臉是由Layer3的幾何圖形組合而成,Layer3的幾何圖形是由Layer2的紋理組合而成,Layer2的紋理是由Layer1的邊緣組合而成,從特徵圖上看的話,Layer4特徵圖上一個點代表Layer3某種幾何圖形或表面的組合,Layer3特徵圖上一個點代表Layer2某種紋理的組合,Layer2特徵圖上一個點代表Layer1某種邊緣的組合。
這種組合是一種相對靈活的方式在進行,不同的邊緣→不同紋理→不同幾何圖形和表面→不同的狗臉、不同的物體……,前面層模式的組合可以多種多樣,使後面層可以描述的模式也可以多種多樣,所以具有很強的表達能力,不是“死板”的模板,而是“靈活”的模板,泛化能力更強。
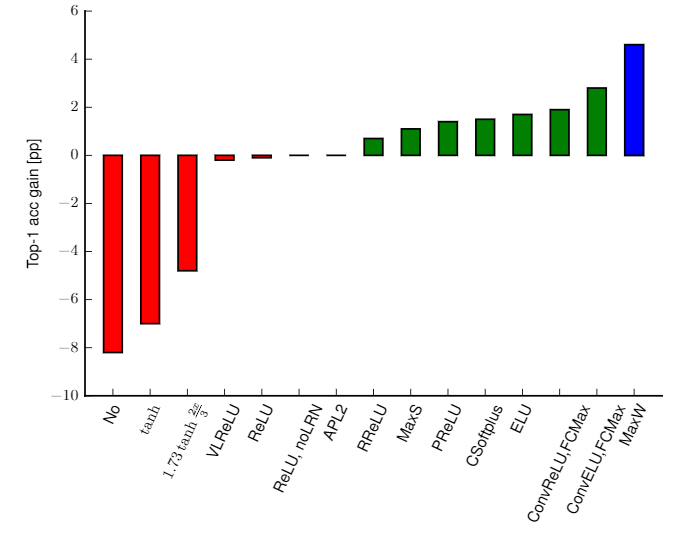
卷積神經網絡真正使用時,還需要配合池化、激活函數等,以獲得更強的表達能力,但模式蘊含在卷積核中,如果沒有非線性激活函數,網絡仍能學到模式,但表達能力會下降,由論文《Systematic evaluation of CNN advances on the ImageNet》,在ImageNet上,使用調整後的caffenet,不使用非線性激活函數相比使用ReLU的性能會下降約8個百分點,如下圖所示。通過池化和激活函數的配合,可以看到復現出的每層學到的特徵是非常單純的,狗、人、物體是清晰的,少有其他其他元素的干擾,可見網絡學到了待檢測對象區別於其他對象的模式。
總結
本文僅對卷積神經網絡中的卷積計算、作用以及其中隱含的思想做了介紹,有些個人理解難免片面甚至錯誤,歡迎交流指正。

