




1. HashMap概述:
HashMap是基於哈希表的Map接口的非同步實現。此實現提供所有可選的映射操作,並允許使用null值和null鍵。此類不保證映射的順序,特別是它不保證該順序恆久不變。
2. HashMap的數據結構:
在java編程語言中,最基本的結構就是兩種,一個是數組,另外一個是模擬指針(引用),所有的數據結構都可以用這兩個基本結構來構造的,HashMap也不例外。HashMap實際上是一個“鏈表散列”的數據結構,即數組和鏈表的結合體。
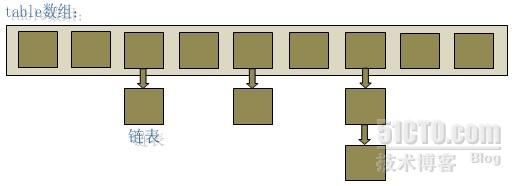
從上圖中可以看出,HashMap底層就是一個數組結構,數組中的每一項又是一個鏈表。當新建一個HashMap的時候,就會初始化一個數組。
源碼如下:
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
……
}
可以看出,Entry就是數組中的元素,每個 Map.Entry 其實就是一個key-value對,它持有一個指向下一個元素的引用,這就構成了鏈表。
3. HashMap的存取實現:
1) 存儲:
public V put(K key, V value) {
// HashMap允許存放null鍵和null值。
// 當key爲null時,調用putForNullKey方法,將value放置在數組第一個位置。
if (key == null)
return putForNullKey(value);
// 根據key的keyCode重新計算hash值。
int hash = hash(key.hashCode());
// 搜索指定hash值在對應table中的索引。
int i = indexFor(hash, table.length);
// 如果 i 索引處的 Entry 不爲 null,通過循環不斷遍歷 e 元素的下一個元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果i索引處的Entry爲null,表明此處還沒有Entry。
modCount++;
// 將key、value添加到i索引處。
addEntry(hash, key, value, i);
return null;
}
從上面的源代碼中可以看出:當我們往HashMap中put元素的時候,先根據key的hashCode重新計算hash值,根據hash值得到這個元素在數組中的位置(即下標),如果數組該位置上已經存放有其他元素了,那麼在這個位置上的元素將以鏈表的形式存放,新加入的放在鏈頭,最先加入的放在鏈尾。如果數組該位置上沒有元素,就直接將該元素放到此數組中的該位置上。
addEntry(hash, key, value, i)方法根據計算出的hash值,將key-value對放在數組table的i索引處。addEntry 是 HashMap 提供的一個包訪問權限的方法,代碼如下:
void addEntry(int hash, K key, V value, int bucketIndex) {
// 獲取指定 bucketIndex 索引處的 Entry
Entry<K,V> e = table[bucketIndex];
// 將新創建的 Entry 放入 bucketIndex 索引處,並讓新的 Entry 指向原來的 Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 如果 Map 中的 key-value 對的數量超過了極限
if (size++ >= threshold)
// 把 table 對象的長度擴充到原來的2倍。
resize(2 * table.length);
}
當系統決定存儲HashMap中的key-value對時,完全沒有考慮Entry中的value,僅僅只是根據key來計算並決定每個Entry的存儲位置。我們完全可以把 Map 集合中的 value 當成 key 的附屬,當系統決定了 key 的存儲位置之後,value 隨之保存在那裏即可。
hash(int h)方法根據key的hashCode重新計算一次散列。此算法加入了高位計算,防止低位不變,高位變化時,造成的hash衝突。
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
我們可以看到在HashMap中要找到某個元素,需要根據key的hash值來求得對應數組中的位置。如何計算這個位置就是hash算法。前面說過HashMap的數據結構是數組和鏈表的結合,所以我們當然希望這個HashMap裏面的 元素位置儘量的分佈均勻些,儘量使得每個位置上的元素數量只有一個,那麼當我們用hash算法求得這個位置的時候,馬上就可以知道對應位置的元素就是我們要的,而不用再去遍歷鏈表,這樣就大大優化了查詢的效率。
對於任意給定的對象,只要它的 hashCode() 返回值相同,那麼程序調用 hash(int h) 方法所計算得到的 hash 碼值總是相同的。我們首先想到的就是把hash值對數組長度取模運算,這樣一來,元素的分佈相對來說是比較均勻的。但是,“模”運算的消耗還是比較大的,在HashMap中是這樣做的:調用 indexFor(int h, int length) 方法來計算該對象應該保存在 table 數組的哪個索引處。indexFor(int h, int length) 方法的代碼如下:
static int indexFor(int h, int length) {
return h & (length-1);
}
這個方法非常巧妙,它通過 h & (table.length -1) 來得到該對象的保存位,而HashMap底層數組的長度總是 2 的 n 次方,這是HashMap在速度上的優化。在 HashMap 構造器中有如下代碼:
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
這段代碼保證初始化時HashMap的容量總是2的n次方,即底層數組的長度總是爲2的n次方。
當length總是 2 的n次方時,h& (length-1)運算等價於對length取模,也就是h%length,但是&比%具有更高的效率。
這看上去很簡單,其實比較有玄機的,我們舉個例子來說明:
假設數組長度分別爲15和16,優化後的hash碼分別爲8和9,那麼&運算後的結果如下:
h & (table.length-1) hash table.length-1
8 & (15-1): 0100 & 1110 = 0100
9 & (15-1): 0101 & 1110 = 0100
--------------------------------------------------------------------------------------
8 & (16-1): 0100 & 1111 = 0100
9 & (16-1): 0101 & 1111 = 0101
從上面的例子中可以看出:當它們和15-1(1110)“與”的時候,產生了相同的結果,也就是說它們會定位到數組中的同一個位置上去,這就產生了碰撞,8和9會被放到數組中的同一個位置上形成鏈表,那麼查詢的時候就需要遍歷這個鏈 表,得到8或者9,這樣就降低了查詢的效率。同時,我們也可以發現,當數組長度爲15的時候,hash值會與15-1(1110)進行“與”,那麼 最後一位永遠是0,而0001,0011,0101,1001,1011,0111,1101這幾個位置永遠都不能存放元素了,空間浪費相當大,更糟的是這種情況中,數組可以使用的位置比數組長度小了很多,這意味着進一步增加了碰撞的機率,減慢了查詢的效率!而當數組長度爲16時,即爲2的n次方時,2n-1得到的二進制數的每個位上的值都爲1,這使得在低位上&時,得到的和原hash的低位相同,加之hash(int
h)方法對key的hashCode的進一步優化,加入了高位計算,就使得只有相同的hash值的兩個值纔會被放到數組中的同一個位置上形成鏈表。
所以說,當數組長度爲2的n次冪的時候,不同的key算得得index相同的機率較小,那麼數據在數組上分佈就比較均勻,也就是說碰撞的機率小,相對的,查詢的時候就不用遍歷某個位置上的鏈表,這樣查詢效率也就較高了。
根據上面 put 方法的源代碼可以看出,當程序試圖將一個key-value對放入HashMap中時,程序首先根據該 key 的 hashCode() 返回值決定該 Entry 的存儲位置:如果兩個 Entry 的 key 的 hashCode() 返回值相同,那它們的存儲位置相同。如果這兩個 Entry 的 key 通過 equals 比較返回 true,新添加 Entry 的 value 將覆蓋集合中原有 Entry 的 value,但key不會覆蓋。如果這兩個 Entry 的 key 通過 equals
比較返回 false,新添加的 Entry 將與集合中原有 Entry 形成 Entry 鏈,而且新添加的 Entry 位於 Entry 鏈的頭部——具體說明繼續看 addEntry() 方法的說明。
2) 讀取:
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
有了上面存儲時的hash算法作爲基礎,理解起來這段代碼就很容易了。從上面的源代碼中可以看出:從HashMap中get元素時,首先計算key的hashCode,找到數組中對應位置的某一元素,然後通過key的equals方法在對應位置的鏈表中找到需要的元素。
3) 歸納起來簡單地說,HashMap 在底層將 key-value 當成一個整體進行處理,這個整體就是一個 Entry 對象。HashMap 底層採用一個 Entry[] 數組來保存所有的 key-value 對,當需要存儲一個 Entry 對象時,會根據hash算法來決定其在數組中的存儲位置,在根據equals方法決定其在該數組位置上的鏈表中的存儲位置;當需要取出一個Entry時,也會根據hash算法找到其在數組中的存儲位置,再根據equals方法從該位置上的鏈表中取出該Entry。
4. HashMap的resize(rehash):
當HashMap中的元素越來越多的時候,hash衝突的機率也就越來越高,因爲數組的長度是固定的。所以爲了提高查詢的效率,就要對HashMap的數組進行擴容,數組擴容這個操作也會出現在ArrayList中,這是一個常用的操作,而在HashMap數組擴容之後,最消耗性能的點就出現了:原數組中的數據必須重新計算其在新數組中的位置,並放進去,這就是resize。
那麼HashMap什麼時候進行擴容呢?當HashMap中的元素個數超過數組大小*loadFactor時,就會進行數組擴容,loadFactor的默認值爲0.75,這是一個折中的取值。也就是說,默認情況下,數組大小爲16,那麼當HashMap中元素個數超過16*0.75=12的時候,就把數組的大小擴展爲 2*16=32,即擴大一倍,然後重新計算每個元素在數組中的位置,而這是一個非常消耗性能的操作,所以如果我們已經預知HashMap中元素的個數,那麼預設元素的個數能夠有效的提高HashMap的性能。
5. HashMap的性能參數:
HashMap 包含如下幾個構造器:
HashMap():構建一個初始容量爲 16,負載因子爲 0.75 的 HashMap。
HashMap(int initialCapacity):構建一個初始容量爲 initialCapacity,負載因子爲 0.75 的 HashMap。
HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的負載因子創建一個 HashMap。
HashMap的基礎構造器HashMap(int initialCapacity, float loadFactor)帶有兩個參數,它們是初始容量initialCapacity和加載因子loadFactor。
initialCapacity:HashMap的最大容量,即爲底層數組的長度。
loadFactor:負載因子loadFactor定義爲:散列表的實際元素數目(n)/ 散列表的容量(m)。
負載因子衡量的是一個散列表的空間的使用程度,負載因子越大表示散列表的裝填程度越高,反之愈小。對於使用鏈表法的散列表來說,查找一個元素的平均時間是O(1+a),因此如果負載因子越大,對空間的利用更充分,然而後果是查找效率的降低;如果負載因子太小,那麼散列表的數據將過於稀疏,對空間造成嚴重浪費。
HashMap的實現中,通過threshold字段來判斷HashMap的最大容量:
threshold = (int)(capacity * loadFactor);
結合負載因子的定義公式可知,threshold就是在此loadFactor和capacity對應下允許的最大元素數目,超過這個數目就重新resize,以降低實際的負載因子。默認的的負載因子0.75是對空間和時間效率的一個平衡選擇。當容量超出此最大容量時, resize後的HashMap容量是容量的兩倍:
if (size++ >= threshold)
resize(2 * table.length);
6. Fail-Fast機制:
我們知道java.util.HashMap不是線程安全的,因此如果在使用迭代器的過程中有其他線程修改了map,那麼將拋出ConcurrentModificationException,這就是所謂fail-fast策略。
這一策略在源碼中的實現是通過modCount域,modCount顧名思義就是修改次數,對HashMap內容的修改都將增加這個值,那麼在迭代器初始化過程中會將這個值賦給迭代器的expectedModCount。
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
}
在迭代過程中,判斷modCount跟expectedModCount是否相等,如果不相等就表示已經有其他線程修改了Map:
注意到modCount聲明爲volatile,保證線程之間修改的可見性。
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
在HashMap的API中指出:
由所有HashMap類的“collection 視圖方法”所返回的迭代器都是快速失敗的:在迭代器創建之後,如果從結構上對映射進行修改,除非通過迭代器本身的 remove 方法,其他任何時間任何方式的修改,迭代器都將拋出 ConcurrentModificationException。因此,面對併發的修改,迭代器很快就會完全失敗,而不冒在將來不確定的時間發生任意不確定行爲的風險。
注意,迭代器的快速失敗行爲不能得到保證,一般來說,存在非同步的併發修改時,不可能作出任何堅決的保證。快速失敗迭代器盡最大努力拋出 ConcurrentModificationException。因此,編寫依賴於此異常的程序的做法是錯誤的,正確做法是:迭代器的快速失敗行爲應該僅用於檢測程序錯誤。
本文出自 “風輕雲淡” 博客,請務必保留此出處http://beyond99.blog.51cto.com/1469451/429789

