




| 本博文出自51CTO博客gaochaojs博主,有任何問題請進入博主頁面互動討論! |
如前幾次博文中所述,流程結束後的實例信息可以通過統一的入口即高級查詢(可以導出excel,也預留了生成各種報表的接口)查詢。但對於一些特殊的工作流,比如轉正、離職、考勤等我們也提供了專門的查詢模塊。比如本文中所述的離職模塊:離職模塊共分三個部分,分別爲離職信息新增、審批中離職、已結束離職三個子模塊。離職信息新增功能主要是針對被動離職,也即單位勸退、辭退或單方面解除合同的離職信息新增,此類離職一旦保存即可認爲是已結束離職,所以不像審批中離職查詢邏輯中十分清晰,已結束離職需要關聯多表進行查詢。在測試系統中進行測試時,我們發現直接執行已結束離職查詢sql,在數據量爲17條時,約1s,實際較慢,但尚可接受。該功能在正式系統上線後,離職數據約400條,用戶簡單在前端計時,約需十餘秒等待,用戶體驗已經極差。拿出該查詢sql,如下:
- SELECT *
- (SELECT DISTINCT leaveinfo.id, f_sqrgh, f_sqrbm, f_sqr, f_sqbmbm
- , f_sqbm, f_lxdhfj, f_sjhm, f_sqrq, f_rzrq
- , f_ndlzrq, f_qrlzrq, f_zw, f_gw, f_gwlx
- , f_gwcj, f_szdq, f_gzdd, f_lzyy, f_lzyyzs
- , f_yggxbmtjl, f_lzlx, f_inputtype, belongCompany, postDirection
- , techLevel, idCard, staffinfo.sex, staffinfo.birthday, exec.id AS 'processExecutionId'
- , exec.status AS 'processExecutionStatus', exec.formDefineId, exec.processDefineId, exec.processInstanceId, exec.tableName
- , process.`name` AS 'processDefineName'
- FROM T_DYMC_20140625100255 leaveinfo LEFT JOIN t_per_staffinfo staffinfo ON staffinfo.staffId = leaveinfo.f_sqrgh LEFT JOIN t_bpm_process_execution exec ON exec.pkValue = leaveinfo.id LEFT JOIN t_bpm_process_define process ON process.id = exec.processDefineId
- WHERE leaveinfo.f_sqrgh = staffinfo.staffId
- AND (exec.`status` = 2
- AND leaveinfo.f_inputtype = 'FLOW'
- OR leaveinfo.f_inputtype = 'MANUAL')
- ) allData LEFT JOIN t_sys_user sysUser ON allData.f_sqrgh = sysUser.staffId
這是一個分頁查詢,查詢出所有結果的數量,如下:
- SELECT COUNT(DISTINCT allData.id)
- FROM (SELECT DISTINCT leaveinfo.id, leaveinfo.f_sqrgh
- FROM T_DYMC_20140625100255 leaveinfo LEFT JOIN t_per_staffinfo staffinfo ON staffinfo.staffId = leaveinfo.f_sqrgh LEFT JOIN t_bpm_process_execution exec ON exec.pkValue = leaveinfo.id LEFT JOIN t_bpm_process_define process ON process.id = exec.processDefineId
- WHERE leaveinfo.f_sqrgh = staffinfo.staffId
- AND (exec.`status` = 2
- AND leaveinfo.f_inputtype = 'FLOW'
- OR leaveinfo.f_inputtype = 'MANUAL')
- ) allData LEFT JOIN t_sys_user sysUser ON allData.f_sqrgh = sysUser.staffId
在測試系統我們對兩條sql在17條數據時分別進行了測試,耗時都在0.5s以下。但在正式系統,測試時數據量398條時,第一條的執行時間約爲9.313s,第二條耗時約4.341s。
顯然,398條數據僅查詢就超過10s顯然超過了用戶的忍耐,大大影響了系統的性能,在用戶體驗大打折扣。
首先我們梳理一下sql,以第一條爲例,我們關聯查詢了多張表,而這多張表是否必要,是否有從邏輯角度優化的可能。
我們查詢的主表是離職信息表,關聯了檔案、運行、流程定義三張表,最後又增加了前文提出的數據權限限制,關聯到用戶表。關聯檔案我們是希望通過檔案查詢出離職人員的信息,關聯運行表信息則是希望查詢出當前辦理者和當前辦理階段,關於流程定義表則是希望查詢出流程定義的名稱。經過分析,我們首先發現這個sql是工程師從高級查詢裏照搬過來的,因爲高級查詢應用於所有流程,流程名需要通過processDefineId查詢,而我們的離職查詢,就是查詢的離職流程,不需要再關聯一張表去查詢。我們將這一關聯去掉,直接返回"離職流程" as processDefineName。
去掉這一關聯,sql的效率有所改善,但改善並不明顯。從邏輯角度我們已經沒有優化的空間。所以希望從數據庫技術角度去進行優化。在着手進行優化之前,我們先看一看當前語句已經使用的優化技術(對於非專業DBA首先可以想到的優化一般是index),而在mysql裏提供了explain來查詢mysql如何使用索引來處理select語句以及連接表。下面,我們看看在未優化之前,在該查詢語句是不是有用優化技術,又使用了哪些優化技術。在未進行優化之前,我們已經有了針對檔案和用戶兩張表的staffid的索引,查詢索引的sql語句如下:
- show index from t_per_staffinfo
如下圖:

以及user表的索引:
![]()
查詢語句中還有兩張表分別爲t_bpm_process_define和t_bpm_process_execution,我們爲其創建索引,希望加入索引後查詢效率有所改善:
- ALTER TABLE t_bpm_process_execution ADD INDEX pkValue_index (pkValue);
類似的我們爲狀態status,以及t_bpm_process_define也加入了索引。
現在我們用explain看看我們目前的查詢語句,如下圖:

基於上圖我們看一下,使用explain查出的信息中的各列的含義,顧名思義,我們看下來,table指的是查詢的表名、type指的是連接使用的哪種類型(從好到差的連接類型依次是const、eq_reg、ref、range、index、all)、possible_key表示可能使用在該表中的索引、key指的是在本次查詢中實際使用到的索引(如果值爲null表示沒有使用索引,mysql在很少情況下會使用未優化的索引,但也可以使用using idex強制使用索引)、key_len表示索引長度(在不損失精度的前提下,長度越短越好)、ref則是哪一列使用了索引、rows是MySQL認爲需要檢查的用來請求返回數據的長度、Extra表示關於解析查詢的額外信息。通過分析Extra,我們可以看出哪些index需要優化以及如何優化。
Extra的值有Distinct、Not Exist、Range cheched for each record、using filesort、using temporary、Using index、where used、system、const、eq_ref、ref、index、all。當出現using filesort(需要額外的步驟進行排序)、using temporary(需要臨時表存儲中間結果)時表示查詢需要進行優化。
由圖中我們可以看出,一些索引還需要進一步優化,但我們查詢的速率已經由近10s縮減爲0.088s。對於非專業的DBA這次優化已經算是成功了。優化到此結束,關於更進一步優化using temporary的問題我會進一步與DBA溝通,將優化進行到底。
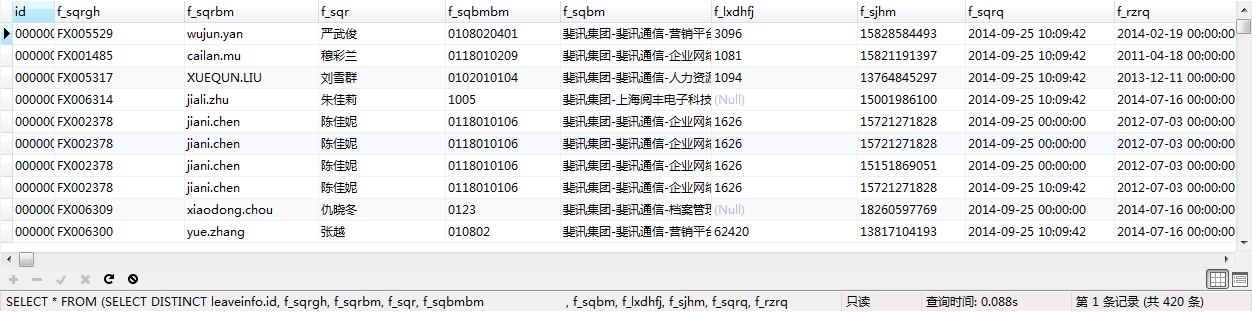
接下來,我們談一下查詢的基礎理論、索引對於查詢的改善和和索引的基礎知識。
對於MySQL的查詢機制,MySQL manual(7.2.1)中一段這樣的描述:
| “The tables are listed in the output in the order that MySQL would read them while processing the query. MySQL resolves all joins using a single-sweep multi-join method. This means that MySQL reads a row from the first table, then finds a matching row in the second table, then in the third table, and so on. When all tables are processed, MySQL outputs the selected columns and backtracks through the table list until a table is found for which there are more matching rows. The next row is read from this table and the process continues with the next table.” |
我們從第三句開始做一下簡單的翻譯:Mysql從第一張表讀取第一行數據,然後在第二張表中查找匹配行,然後在查找第三張表,以此類推。當所有表處理完畢,Mysql輸出選中的列然後回溯表的列表一直到能夠匹配更多行的表出現。從這張表中讀取下一行,然後繼續查詢下一張表。這個關聯查詢的過程的關鍵就是從上一張表來查詢當前表的內容。
瞭解到從上一張表查詢當前表的原理後,我們創建index的目的就是告訴MySQL如何直接查詢下一張表的數據,以及如何按照需要的順序來join下一張表。
上文中我們也介紹了查看和創建索引的語句,更進一步瞭解其他操作方法可以查看一些關於索引的基礎知識。