




文章目錄
課堂安排
- 簡單網絡的梯度計算以及一些小提示
- 計算圖和反向傳播
- 需要掌握的知識
a. 防止過擬合的規則 b. 向量化 c. 非線性 d. 初始化 e. 優化器 f.學習率
一、反向傳播·續
1.1 的計算推導
上一節課我們得到:
假設長度爲n, 長度爲m,那麼我們現在來看看, 由於W是一個n × m的矩陣, 我們單獨看一個元素。由於只對有影響,因此:
所以有:
那麼 就應該是一個n × m的矩陣, 而 , 所以有:
1.2 梯度推導溫馨提示
- 嚴肅認真的定義變量,並且始終記得維護他們的維度一致性
- 運用鏈式法則
- 對於頂層的softmax推導,要先考慮,即正確類別,然後考慮, 即錯誤類別。
- 如果對矩陣推導感覺迷惑了,就進行元素級別的計算
- 運用維度傳播規律,任意一層的誤差信號的長度與該層的大小相同。
1.3 輸入x的偏導
對於x的偏導,輸入階段我們將窗口內的單詞拼接成了一個向量,對於反向傳播的誤差,也可以直接拆分到各個單詞向量進行更新。
如果一個單詞在同一個窗口中出現了兩次,那麼我們就對這個單詞進行兩次更新。
1.4 下游任務更新詞向量存在的風險
假如預訓練詞向量中有電視、電影、節目三個詞義相近,詞向量相似的詞語,但訓練集只有電視、電影兩個詞出現,而測試集中出現了節目這個詞。那麼如果我們在訓練階段更新了詞向量,就會導致三個詞向量之間相似度降低。
解決方案: 如果下游任務數據集較小,就不要更新詞向量。如果下游任務數據集很大,那麼可以在訓練階段更新詞向量(相當於fine-tune)
二、計算圖及其反向傳播
這之前我們要了解圖計算(graph computing) 和 **計算圖(computation graph)**是兩個不同的概念。本節課的計算圖是用圖的方式來表示計算流程的神經網絡計算框架,而圖計算是利用圖論方法研究任意數據的內在聯繫的一類算法統稱。
2.1 計算圖的概念
- 前向傳播(黑色箭頭方向):
- 起始節點x爲輸入
- 每個中間節點爲運算操作
- 箭頭爲運算操作的輸出信號
- 反向傳播(藍色箭頭方向)
- 每條邊代表Loss函數對該層輸入信號的偏導(通過鏈式法則)。
![在這裏插入圖片描述]()
對於單個節點的視圖如下:
![在這裏插入圖片描述]()


2.2 一個簡單地計算實例
注意這裏的max函數,需要跟情況討論輸入參數的梯度,並根據運行反向傳播的時刻的輸入值來決定使用哪一個梯度(相當於激活的神經元或抑制的神經元)。下圖中藍色部分爲反向傳播的梯度值,在更新時需要與學習率相乘。

2.3 分支網絡的處理
如果一個節點輸出被下一層的多個節點使用,那麼反向更新時這個節點就會接受到兩個誤差信號(如圖),我們只需要將這兩個輸入信號相加(事實上就是多元複合函數求偏導的公式呀)。 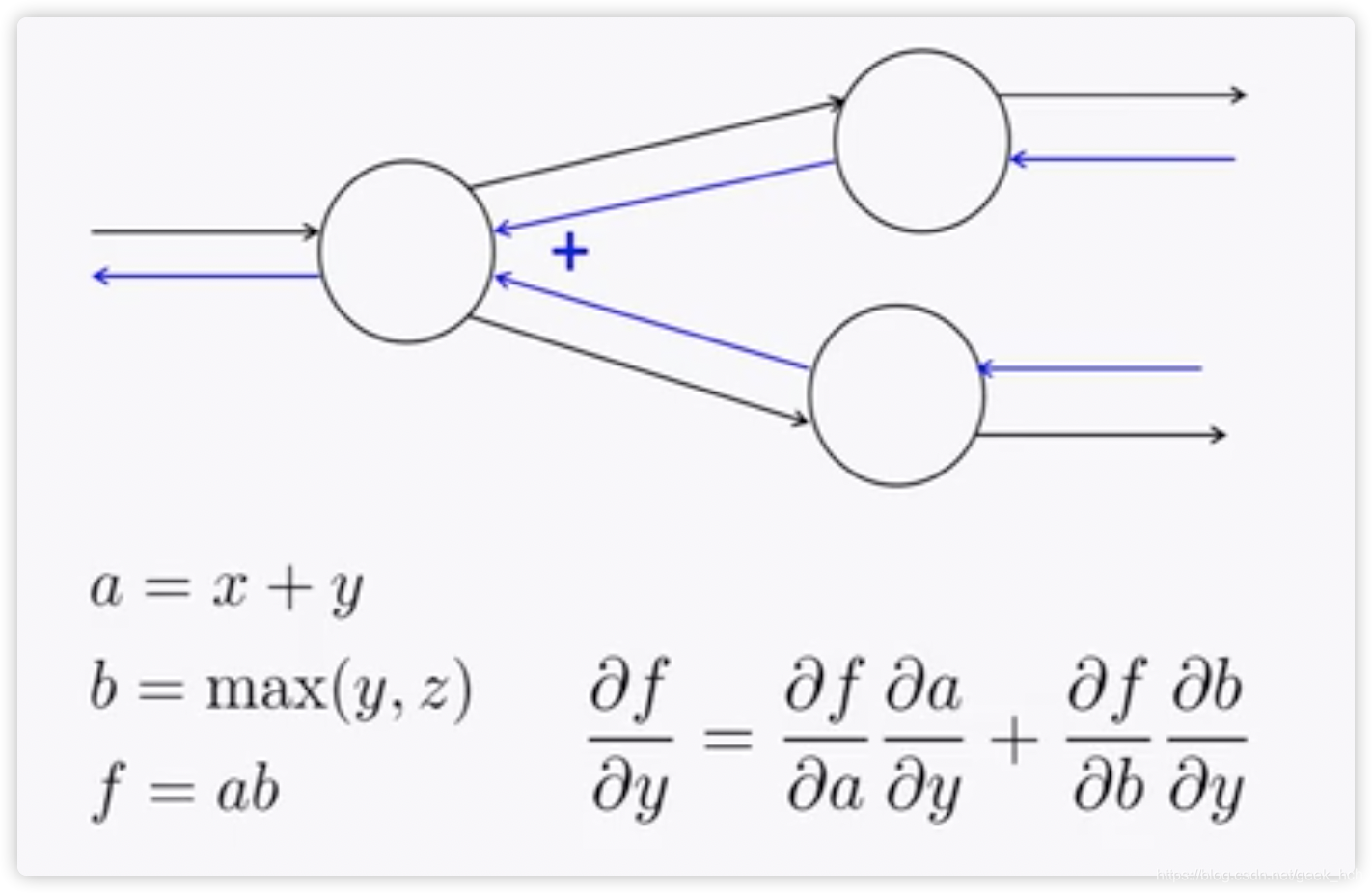 ## 2.4 反向傳播運算規律 觀察2.2節中的計算過程,可以得出以下規律: + +運算將上游梯度分發複製到下游每個分支 + max運算將上游梯度路由到下游中最大值的那一個分支 + *運算將下游的值交換後作爲梯度發送給下游分支。但這只是針對上游分支只有兩個的情況。如果有多個呢?(當然就是一個分支的梯度等於其他分支的前向傳播值的乘積)
2.5 高效計算:每個局部誤差信號僅計算一遍
對於如下計算圖,如果我們直接計算,這是極其低效的,因爲這樣的話我們計算時又會重複計算上游的梯度。
高效的計算方式是Top-Down,從loss反向一層層的傳播,每一次計算都通過鏈式法則,利用上一層的梯度信息。

2.6 更復雜的計算圖
對於以下計算圖,有了前面的知識,我們可以輕易地進行Fprop和Bprop,如果方法正確,Fprop和Bprop的計算複雜度應該相同。根據2.3節:

對於一些規範的圖(大多數神經網絡),我們都可以利用矩陣和雅克比來簡化計算
三、神經網絡代碼實現及相關框架
3.1 自動求導
對於每個節點,如果滿足下面的條件,那麼由這些節點構成的網絡就能夠自動求導,反向傳播。
+ 定義節點的輸入與輸出
+ 定義該節點輸出對每個輸入的偏導
現代神經網絡框架正式利用這個原理,通過程序員定義每一層/節點的手寫梯度計算,來實現整個深度神經網絡的自動求導。求偏導公式是一個符號計算過程,tf, torch等框架只提供數值計算,所以需要程序員給出所有可能的計算公式(前向、反向)
3.2 計算圖的代碼(僞代碼)
這是pytorch框架計算圖的定義,可以很清晰地看到前向傳播、反向傳播的邏輯:

對於單個單元,這裏以簡單的乘法運算爲例,實現代碼如下,這裏要注意forward和backword的接口參數
3.3 梯度檢查:數值梯度
(注意區分梯度的數值計算和符號計算)
根據偏導的定義,我們可以通過以下公式計算梯度的近似值,但由於計算中h(1e-4)不是無窮小的數,所以並不是真實的梯度值。
理論上我們可以用這個方法實現完全自動的求導,但我們可以看到這個方法要求每次計算梯度時都要重新計算f(x+h)、f(x-h),並且每次更新對每個參數都要計算一次,性能較低。通常使用這個方法來檢查我們的代碼實現。
3.4 瞭解梯度的計算過程的意義
- 有助於我們思考如何提升模型性能
- 可能存在的bug: 梯度消失和爆炸
四、其他細節
4.1 參數正則化
當網絡參數量很大的時候,爲了防止過擬合,我們需要在一般的loss後面添加一個L2正則項來限制參數。(通過懲罰偏離0較遠的參數值,限制模型的擬合能力)
4.2 向量化運算
向量化是指,儘可能的將循環計算轉換爲更高維的向量計算,因爲計算框架對向量運算有優化,比一般的循環快很多。比如下面兩行,計算輸入和輸出一樣,但時間卻相差了40多倍,如果使用GPU, 差距會遠大得多。

4.3 非線性激活函數
早起使用的非線性激活函數如下,其中tanh(z) = 2*sigmod(z) - 1, sigmod 和 tanh現在仍然會在某些特殊情況下被用到,但不再是默認的激活函數:
- sigmod
- tanh
- hard-tanh(出現的原因是爲了加速運算,雖然在每一段上都是線性的,但其分段打破了線性,因此是有效的激活函數)
![在這裏插入圖片描述]()
這之後,激活函數不斷被改進,出現了更加簡化且高效的版本ReLU及其改進版本,ReLU的功能就是簡單地賦予神經元(抑制、有效)兩種狀態,求導非常容易,是在構建網絡時推薦的默認激活函數。leaky ReLU只在部分論文中被稱有效。
![在這裏插入圖片描述]()


4.4 參數初始化
通常需要將權重初始化爲較小的值
- biases初始化爲0,
- 其他權重初始化爲uniform(-r, r)(r爲一個較小的數)
4.5 優化器
一般來說,簡單地SGD就會很有效。但一些複雜的網絡可能需要適應性更強的優化器,這些優化器可能通過給每個變量設置不同的學習率並記錄,來提高其優化效率(Adagrad、RMSprp、Adam(推薦作爲默認使用)、sparseAdam)
4.6 學習率
一般默認起始學習率0.001, 可以以10倍減小,太大會導致不收斂,太小則優化過程很慢。
最好允許學習率在學習過程中逐漸減小,比如每k個epoch減半或使用如下公式: