




在聲明變量,函數,和大多數其他類型實體的時候,C++要求我們使用指定的類型。然而,有許多代碼,除了類型不同之外,其餘部分看起來都是相同的,比如,下面這個例子:
bool IsEqual (int left, int right)
{
return left == right;
}
bool IsEqual (const string& left , const string& right)
{
return left == right;
}
void test()
{
string s1 ("s1"), s2("s2");
cout<<IsEqual (s1, s2)<<endl;
cout<<IsEqual (1,1)<<endl;
} 上面這個例子,是爲了比較兩個變量是否相等的重載函數。這兩個函數功能相同,只是處理的參數類型不同,那如果你需要處理float,double,等一系列類型時,你就要一一寫出這些類型的重載函數,這樣代碼會顯得十分繁瑣,這時,就需要使用模板函數來處理了,模板函數只需要寫一個就可以處理上面這種問題。
template<typename T>
bool IsEqual (const T& left , const T& right )
{
return left == right;
}
void test1 ()
{
string s1 ("s1"), s2("s2" );
cout<<IsEqual (s1, s2)<<endl ;
cout<<IsEqual (1,1)<<endl;
}在編譯模板函數時,編譯器會根據傳入的參數,自動推演出模板形參類型,並自動生成相應的代碼,這樣就相對於上面使用函數重載方式,代碼量就大大減少,因爲編譯器會幫助你推演出相應代碼。
當上面處理left,right類型不同時,使用模板函數時就需要作如下處理:
template <typename T>
bool IsEqual (const T& left , const T& right )
{
return left == right;
}
void test2()
{
cout<<IsEqual (1,1)<<endl;
//cout<<IsEqual(1,1.2)<<endl; // 模板參數不匹配
cout<<IsEqual<int>(1,1.2)<< endl; // 顯示實例化
cout<<IsEqual<double>(1,1.2)<< endl; // 顯示實例化
}那麼我們就知道使用模板函數就要注意模板參數的匹配問題,你也可以使用顯示實例化方式,強制處理這種情況的發生。要是你就是想要比較兩種不同類型,那就需要重載函數模板,使它可以接受兩種類型,下面就是重載之後的:
bool IsEqual (const int& left , const int& right)
{
return left == right;
}
template <typename T>
bool IsEqual (const T& left , const T& right )
{
return left == right;
}
template <typename T1, typename T2>
bool IsEqual (const T1& left , const T2& right)
{
return left == right;
}
void test3()
{
cout<<IsEqual(1,1)<<endl;
cout<<IsEqual<int>(1,1)<< endl;
cout<<IsEqual(1,1.2)<<endl;
}模板類
/*模板類的格式*/
template<class name1, class name2, ...class namen>
class name
{ ... }; 以前在處理順序表時,要更改其中的data類型,往往是通過修改typedef int DataType ,來修改其存放的數據類型,那麼現在就可以使用模板類來不需要手動去修改其類型,下面是使用模板類實現順序表:
#include <string>
#include <cassert>
using namespace std;
template <class T>
class SeqList
{
public:
SeqList()
:_data(NULL)
,_size(0)
,_capacity(0)
{
CheakCapacity();
}
~SeqList()
{
if(_data != NULL)
{
delete[] _data;
}
}
public:
void PushBack(const T& d)
{
CheakCapacity();
_data[_size] = d;
_size++;
}
void PushFront(const T& d)
{
CheakCapacity();
int i = _size;
for(i; i>0; i--)
{
_data[i] = _data[i-1];
}
_data[i] = d;
_size++;
}
void PopBack()
{
if(_size == 0)
{
cout<<"List is empty!!"<<endl;
return;
}
_size--;
}
void PopFront()
{
int i = 0;
if(_size == 0)
{
cout<<"List is empty!!"<<endl;
return;
}
for(i; i<_size; i++)
{
_data[i] = _data[i+1];
}
_size--;
}
public:
void CheakCapacity()
{
if(_size == _capacity)
{
T* tmp = new T[_capacity+3];
memcpy(tmp, _data, (_capacity)*sizeof(T));
delete[] _data;
_data = tmp;
_capacity = _capacity+3;
}
}
void Display()
{
int i = 0;
for(i; i<_size; i++)
{
cout<<_data[i]<<" ";
}
cout<<"over"<<endl;
}
private:
T* _data;
int _size;
int _capacity;
};
void test4()
{
SeqList<int> L;
L.PushBack(1);
L.PushBack(2);
L.PushBack(3);
L.PushBack(4);
L.PushBack(5);
L.Display();
}
int main()
{
test4();
system("pause");
return 0;
}結果:
![650) this.width=650;" src="http://s4.51cto.com/wyfs02/M02/7E/83/wKioL1cDX-6j46f0AAAK6LcRYRY943.png" title="T~}~WNYN)(1~Q47P0]_(PF4.png" alt="wKioL1cDX-6j46f0AAAK6LcRYRY943.png" />](http://s4.51cto.com/wyfs02/M02/7E/83/wKioL1cDX-6j46f0AAAK6LcRYRY943.png){kind=link}
當測試爲下面test5()時:
void test5()
{
SeqList<string> L;
L.PushBack("11111111111");
L.PushBack("21111111111");
L.PushBack("31111111111");
L.PushBack("41111111111");
L.PushBack("51111111111");
L.PushBack("61111111111");
L.Display();
}結果:
![650) this.width=650;" src="http://s2.51cto.com/wyfs02/M01/7E/83/wKioL1cDYlKS2rMtAABXoC3TiEU193.png" title="[B~$NR5_}~V`R`V{0]8%R_5.png " alt="wKioL1cDYlKS2rMtAABXoC3TiEU193.png" />](http://s2.51cto.com/wyfs02/M01/7E/83/wKioL1cDYlKS2rMtAABXoC3TiEU193.png){kind=link}
這爲什麼會崩潰呢?
因爲使用memcpy()時:當我們拷貝的是基本類型時,只用拷貝所傳遞指針上的數據,如果是string類型呢,我們則需要在堆上開闢空間,所傳遞的指針如 果被直接複製,則有可能(vs下的string類型的實現原理是若字符串不長則以數組保存,若字符串過長,則通過指針在堆上開闢空間進行保存)出現同一地 址,析構兩次這樣的常見錯誤。
那麼要解決上面的問題,就要使用c++中的類型萃取技術。
類型萃取是一種常用的編程技巧,其目的是實現不同類型數據面對同一函數實現不同的操作,它與類封裝的區別是,我們並不用知道我 們所調用的對象是什麼類型,類型萃取是編譯後知道類型,先實現,而類的封裝則是先定義類型,後實現方法。在這裏我們可以用模板的特化實現其編程思想。
再來實現上面的順序表:
#include <iostream>
#include <string>
#include <cassert>
using namespace std;
template <class T>
class SeqList
{
public:
SeqList()
:_data(NULL)
,_size(0)
,_capacity(0)
{
CheakCapacity();
}
~SeqList()
{
if(_data != NULL)
{
delete[] _data;
}
}
public:
void PushBack(const T& d)
{
CheakCapacity();
_data[_size] = d;
_size++;
}
void PushFront(const T& d)
{
CheakCapacity();
int i = _size;
for(i; i>0; i--)
{
_data[i] = _data[i-1];
}
_data[i] = d;
_size++;
}
void PopBack()
{
if(_size == 0)
{
cout<<"List is empty!!"<<endl;
return;
}
_size--;
}
void PopFront()
{
int i = 0;
if(_size == 0)
{
cout<<"List is empty!!"<<endl;
return;
}
for(i; i<_size; i++)
{
_data[i] = _data[i+1];
}
_size--;
}
public:
int Find(const T& d)
{
int i = 0;
for(i; i<_size; i++)
{
if(_data[i] == d)
{
return i;
}
}
return -1;
}
void Insert(int pos, const T& d)
{
CheakCapacity();
int i = 0;
for(i=_size; i>pos; i--)
{
_data[i] = _data[i-1];
}
_data[pos] = d;
_size++;
}
void Erase(int pos)
{
assert(pos>0);
assert(pos<_size);
int i = pos;
for(i; i<_size; i++)
{
_data[i] = _data[i+1];
}
_size--;
}
void Sort()
{
int i,j;
for(i=0; i<_size; i++)
{
for(j=0; j<_size-1-i; j++)
{
if(_data[j]>_data[j+1])
{
T tmp = _data[j];
_data[j] = _data[j+1];
_data[j+1] = tmp;
}
}
}
}
public:
void CheakCapacity()
{
if(_size == _capacity)
{
T* tmp = new T[_capacity+3];
if(TypeTraits<T>::isPODType().Get())
{
memcpy(tmp, _data, (_capacity)*sizeof(T));
}
else
{
for(int i=0; i<_size; i++)
{
tmp[i] = _data[i];
}
}
delete[] _data;
_data = tmp;
_capacity = _capacity+3;
}
}
void Display()
{
int i = 0;
for(i; i<_size; i++)
{
cout<<_data[i]<<" ";
}
cout<<"over"<<endl;
}
private:
T* _data;
int _size;
int _capacity;
};
struct FalseType
{
bool Get()
{
return false;
}
};
struct TrueType
{
bool Get()
{
return true;
}
};
template <class T>
struct TypeTraits
{
typedef FalseType isPODType;//內嵌型別
};
struct TypeTraits<char>
{
typedef TrueType isPODType;//內嵌型別
};
template<>
struct TypeTraits<int>
{
typedef TrueType isPODType;//內嵌型別
};/*還有許多基本類型沒有顯示寫出來,bool,float,double...*/
void test6()
{
SeqList<string> L;
L.PushBack("11111111111");
L.PushBack("21111111111");
L.PushBack("31111111111");
L.PushBack("41111111111");
L.PushBack("51111111111");
L.PushBack("61111111111");
L.Display();
}
int main()
{
test6();
system("pause");
return 0;
}結果:
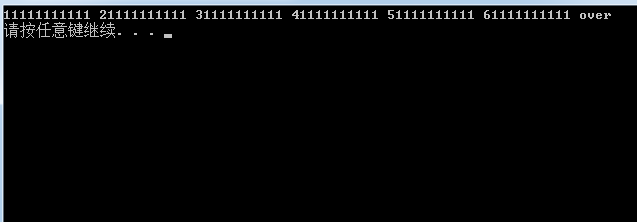{kind=link}
模板總結
優點:
1. 模板複用了代碼,節省資源,更快的迭代開發,C++的標準模板庫(STL)因此而產生。
2. 增強了代碼的靈活性。
缺點:
1. 模板讓代碼變得凌亂複雜,不易維護,編譯代碼時間變長。
2. 出現模板編譯錯誤時,錯誤信息非常凌亂,不易定位錯誤。
類型萃取總結:
類型萃取技術可以大大加快代碼的效率,也可以讓思路變得更清晰。
要是上面在拷貝時,其實不用memcpy()也可以,只要將對象一個一個的拷貝,也是可行的,但程序的效率就會大大降低。
在調試的時候會讓本人思路更加清晰。
本文出自 “Pzd流川楓” 博客,請務必保留此出處http://xujiafan.blog.51cto.com/10778767/1760483