




我們連接Linux來實現正則表達式
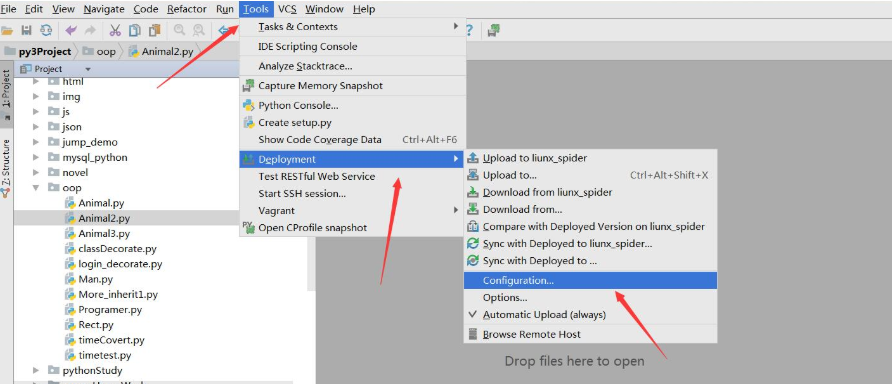
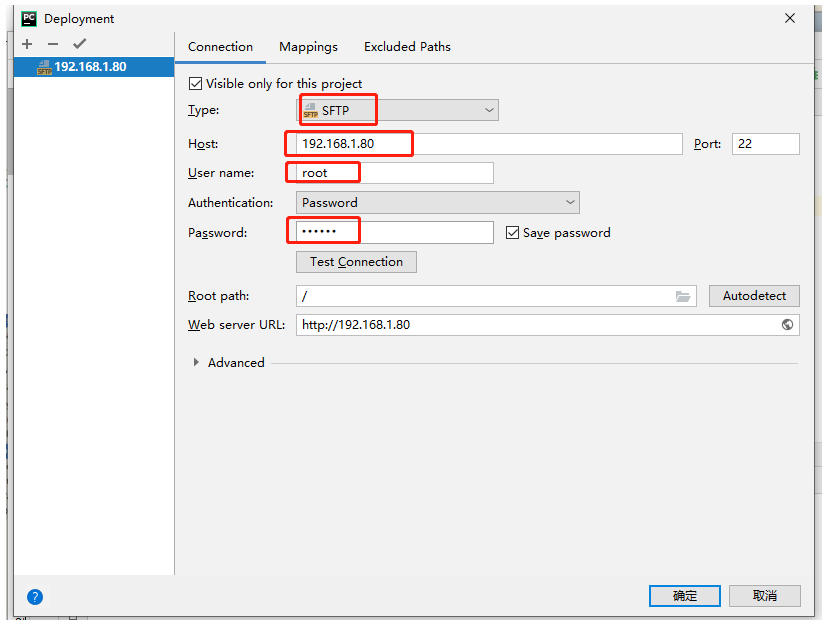
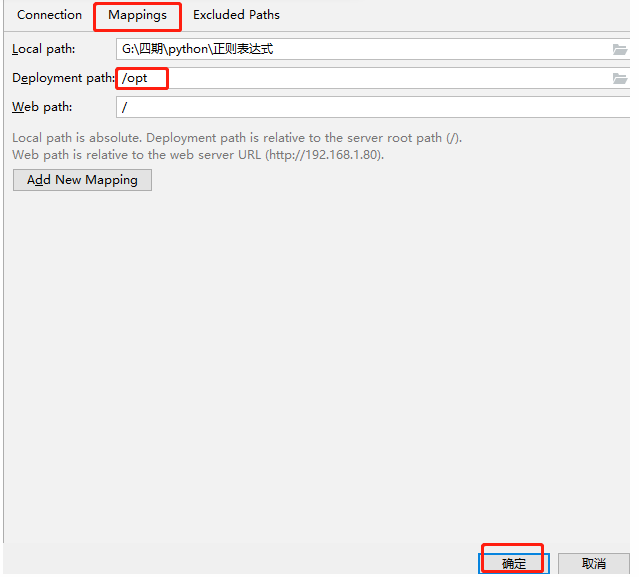
一、Python3 正則表達式

正則表達式是一個特殊的字符序列,它能幫助你方便的檢查一個字符串是否與某種模式匹配。
Python 自1.5版本起增加了re 模塊,它提供 Perl 風格的正則表達式模式。
re 模塊使 Python 語言擁有全部的正則表達式功能。
compile 函數根據一個模式字符串和可選的標誌參數生成一個正則表達式對象。該對象擁有一系列方法用於正則表達式匹配和替換。
re 模塊也提供了與這些方法,功能完全一致的函數,這些函數使用一個模式字符串做爲它們的第一個參數。
本章節主要介紹 Python 中常用的正則表達式處理函數,如果你對正則表達式不瞭解,可以查看我們的 正則表達式 - 教程。
1、re.split
split 方法按照能夠匹配的子串將字符串分割後返回列表,它的使用形式如下:
re.split(pattern, string[, maxsplit=0, flags=0])參數:
| 參數 | 描述 |
|---|---|
| pattern | 匹配的正則表達式 |
| string | 要匹配的字符串。 |
| maxsplit | 分隔次數,maxsplit=1 分隔一次,默認爲 0,不限制次數。 |
| flags | 標誌位,用於控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等。參見:正則表達式修飾符 - 可選標誌 |
例子
import re
# fLags=re.IGNORECASE:忽略大小寫
data = 'Last login: Tue Mar 31 17:56:11 2020 from 192.168.1.80'
new_data = re.split('[:.]\s*', data)
print(new_data)
print(data.split(': '))以上實例輸出結果如下:
['Last login', 'Tue Mar 31 17', '56', '11 2020 from 192', '168', '1', '80'] ['Last login', 'Tue Mar 31 17:56:11 2020 from 192.168.1.80']
以下是正則表達式的基本語法:
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的開頭 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了換行符,當re.DOTALL標記被指定時,則可以匹配包括換行符的任意字符。 |
| [...] | 用來表示一組字符,單獨列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0個或多個的表達式。 |
| re+ | 匹配1個或多個的表達式。 |
| re? | 匹配0個或1個由前面的正則表達式定義的片段,非貪婪方式 |
| re{ n} | 匹配n個前面表達式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的兩個o。 |
| re{ n,} | 精確匹配n個前面表達式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等價於"o+"。"o{0,}"則等價於"o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正則表達式定義的片段,貪婪方式 |
2、特殊字符類
| 實例 | 描述 |
|---|---|
| . | 匹配除 "\n" 之外的任何單個字符。要匹配包括 '\n' 在內的任何字符,請使用象 '[.\n]' 的模式。 |
| \d | 匹配一個數字字符。等價於 [0-9]。 |
| \D | 匹配一個非數字字符。等價於 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、製表符、換頁符等等。等價於 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等價於 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下劃線的任何單詞字符。等價於'[A-Za-z0-9_]'。 |
| \W | 匹配任何非單詞字符。等價於 '[^A-Za-z0-9_]'。 |
# ?[a-zA-Z]+
# ?用來匹配單詞前後可能出現的空格,[a-zA-Z]代表一個或多個英文字母
# 匹配一個IP地址 192.168.1.80
# [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}3、findall 函數
在字符串中找到正則表達式所匹配的所有子串,並返回一個列表,如果沒有找到匹配的,則返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
語法格式爲:
re.findall(string[, pos[, endpos]])參數:
- string 待匹配的字符串。
- pos 可選參數,指定字符串的起始位置,默認爲 0。
- endpos 可選參數,指定字符串的結束位置,默認爲字符串的長度。
查找字符串中的所有數字:
import re
pattern = re.compile(r'\d+') # 查找數字
result1 = pattern.findall('runoob 123 google 456')
result2 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)以上實例輸出結果如下:
['123', '456'] ['88', '12']
4、compile 函數
compile 函數用於編譯正則表達式,生成一個正則表達式( Pattern )對象,供 match() 和 search() 這兩個函數使用。
語法格式爲:
re.compile(pattern[, flags])參數:
- pattern : 一個字符串形式的正則表達式
- flags 可選,表示匹配模式,比如忽略大小寫,多行模式等,具體參數爲:
-
-
re.I 忽略大小寫
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依賴於當前環境
- re.M 多行模式
- re.S 即爲' . '並且包括換行符在內的任意字符(' . '不包括換行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依賴於 Unicode 字符屬性數據庫
- re.X 爲了增加可讀性,忽略空格和' # '後面的註釋
-
例子1
>>>import re
>>> pattern = re.compile(r'\d+') # 用於匹配至少一個數字
>>> m = pattern.match('one12twothree34four') # 查找頭部,沒有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 從'e'的位置開始匹配,沒有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 從'1'的位置開始匹配,正好匹配
>>> print( m ) # 返回一個 Match 對象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)在上面,當匹配成功時返回一個 Match 對象,其中:
group([group1, …])方法用於獲得一個或多個分組匹配的字符串,當要獲得整個匹配的子串時,可直接使用group()或group(0);start([group])方法用於獲取分組匹配的子串在整個字符串中的起始位置(子串第一個字符的索引),參數默認值爲 0;end([group])方法用於獲取分組匹配的子串在整個字符串中的結束位置(子串最後一個字符的索引+1),參數默認值爲 0;span([group])方法返回(start(group), end(group))。
例子2
import re
# flags=re. IGNORECASE:忽略大小寫
data = 'Linux系統內置Python 2.7.5,我們安裝了Python 3.8.1。'
print(re.findall( 'python [0-9]\.[0-9]\.[0-9]', data, flags=re.IGNORECASE))
#
re_obj = re.compile('python [0-9]\.[0-9]\.[0-9]', flags=re.IGNORECASE)
print(re_obj.findall(data))以上實例輸出結果如下:
['Python 2.7.5', 'Python 3.8.1'] ['Python 2.7.5', 'Python 3.8.1']
5、測試findall和compile的讀取速度
(1)Linux生成數字文件
[root@python ~]# seq 10000 > data.txt(2)pycharm創建findall和compile的讀取data.txt的文件
findall
import re
def main():
pattern = "[0-9]+"
with open('~/data.txt') as f:
for line in f:
re.findall(pattern, line)
if __name__ == 'main':
main()compile
import re
def main() :
pattern = "[0-9]+"
re_obj = re.compile(pattern)
with open("~/data.txt") as f:
for line in f:
re_obj.findall(line)
if __name__ == "main":
main( )(3)上傳文件到Linux

底部出現以下信息,上傳成功

(4)Linux測試下載速度
進入上傳的目錄/opt
[root@python ~]# cd /opt/
[root@python opt]# cd 練習
[root@python 練習]# ls
001.py findall.py compile.py測試
[root@python 練習]# time python3 findall.py
real 0m0.058s
user 0m0.005s
sys 0m0.029s
[root@python 練習]# time python3 compile.py
real 0m0.018s
user 0m0.014s
sys 0m0.004s經測試可看出compile讀取的方式更快
二、常用的re函數

data = 'What is the difference between python 2.7.5 and Python 3.8.1 ?'
import re
print(re.findall('[0-9]\.[0-9]\.[0-9]',data))
print(re.findall('python [0-9]\.[0-9]\.[0-9]',data))
print(re.findall('Python [0-9]\.[0-9]\.[0-9]',data))
print(re.findall('ython [0-9]\.[0-9]\.[0-9]',data))
print(data.startswith('What'))
print(data.endswith('?'))
print(re.match('What',data))
word = "123 is one hender and twentyu-there"
print(re.match('\d+',word))
r = re.match('\d+',word)
print(r)
print(r.start())
print(r.end())
print(r.re)
print(r.group())
print(r.string)
rr = re.finditer('[0-9]\.[0-9]\.[0-9]',data)
print(rr)
# print([r for r in rr])
for it in rr:
print(it.group(0))以上實例輸出結果:
# 輸出'x.x.x'類型的數字 ['2.7.5', '3.8.1'] # 輸出'python x.x.x'類型的數字 ['python 2.7.5'] # 輸出'Python x.x.x'類型的數字 ['Python 3.8.1'] # 輸出'ython x.x.x'類型的數字 ['ython 2.7.5', 'ython 3.8.1'] # 查找data中是否有'What' True # 查找data中是否有'J' True # 查找data中是否有'What' <re.Match object; span=(0, 4), match='What'> # 查找data中是否有'數字字符' <re.Match object; span=(0, 3), match='123'> # 查找data中是否有'數字字符' <re.Match object; span=(0, 3), match='123'> # 匹配的子串在整個字符串中的起始位置 0 # 匹配的子串在整個字符串中的結束位置 3 # 獲取re函數的類型 re.compile('\\d+') # 獲得一個或多個分組匹配的字符串 123 # 匹配的字符串 123 is one hender and twentyu-there # 輸出rr <callable_iterator object at 0x000001B92D1613D0> # 一行一行輸出rr文件的'x.x.x'類型的數字 2.7.5 3.8.1
(一)匹配類
1、re.match函數
re.match 嘗試從字符串的起始位置匹配一個模式,如果不是起始位置匹配成功的話,match()就返回none。
函數語法:
re.match(pattern, string, flags=0)函數參數說明:
| 參數 | 描述 |
|---|---|
| pattern | 匹配的正則表達式 |
| string | 要匹配的字符串。 |
| flags | 標誌位,用於控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等。參見:正則表達式修飾符 - 可選標誌 |
匹配成功re.match方法返回一個匹配的對象,否則返回None。
我們可以使用group(num) 或 groups() 匹配對象函數來獲取匹配表達式。
| 匹配對象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整個表達式的字符串,group() 可以一次輸入多個組號,在這種情況下它將返回一個包含那些組所對應值的元組。 |
| groups() | 返回一個包含所有小組字符串的元組,從 1 到 所含的小組號。 |
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配以上實例輸出結果:
(0, 3) None
import re
line = "Cats are smarter than dogs"
# .* 表示任意匹配除換行符(\n、\r)之外的任何單個或多個字符
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")以上實例輸出結果:
matchObj.group() : Cats are smarter than dogs matchObj.group(1) : Cats matchObj.group(2) : smarter
2、compile 函數
compile 函數用於編譯正則表達式,生成一個正則表達式( Pattern )對象,供 match() 和 search() 這兩個函數使用。
語法格式爲:
re.compile(pattern[, flags])參數:
- pattern : 一個字符串形式的正則表達式
- flags 可選,表示匹配模式,比如忽略大小寫,多行模式等,具體參數爲:
-
-
re.I 忽略大小寫
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依賴於當前環境
- re.M 多行模式
- re.S 即爲' . '並且包括換行符在內的任意字符(' . '不包括換行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依賴於 Unicode 字符屬性數據庫
- re.X 爲了增加可讀性,忽略空格和' # '後面的註釋
-
實例
>>>import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小寫
>>> m = pattern.match('Hello World Wide Web')
>>> print( m ) # 匹配成功,返回一個 Match 對象
<_sre.SRE_Match object at 0x10bea83e8>
>>> m.group(0) # 返回匹配成功的整個子串
'Hello World'
>>> m.span(0) # 返回匹配成功的整個子串的索引
(0, 11)
>>> m.group(1) # 返回第一個分組匹配成功的子串
'Hello'
>>> m.span(1) # 返回第一個分組匹配成功的子串的索引
(0, 5)
>>> m.group(2) # 返回第二個分組匹配成功的子串
'World'
>>> m.span(2) # 返回第二個分組匹配成功的子串索引
(6, 11)
>>> m.groups() # 等價於 (m.group(1), m.group(2), ...)
('Hello', 'World')
>>> m.group(3) # 不存在第三個分組
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group在上面,當匹配成功時返回一個 Match 對象,其中:
group([group1, …])方法用於獲得一個或多個分組匹配的字符串,當要獲得整個匹配的子串時,可直接使用group()或group(0);start([group])方法用於獲取分組匹配的子串在整個字符串中的起始位置(子串第一個字符的索引),參數默認值爲 0;end([group])方法用於獲取分組匹配的子串在整個字符串中的結束位置(子串最後一個字符的索引+1),參數默認值爲 0;span([group])方法返回(start(group), end(group))。
3、re.search方法
re.search 掃描整個字符串並返回第一個成功的匹配。
函數語法:
re.search(pattern, string, flags=0)函數參數說明:
| 參數 | 描述 |
|---|---|
| pattern | 匹配的正則表達式 |
| string | 要匹配的字符串。 |
| flags | 標誌位,用於控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等。參見:正則表達式修飾符 - 可選標誌 |
匹配成功re.search方法返回一個匹配的對象,否則返回None。
我們可以使用group(num) 或 groups() 匹配對象函數來獲取匹配表達式。
| 匹配對象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整個表達式的字符串,group() 可以一次輸入多個組號,在這種情況下它將返回一個包含那些組所對應值的元組。 |
| groups() | 返回一個包含所有小組字符串的元組,從 1 到 所含的小組號。 |
實例
import re
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配以上實例輸出結果:
(0, 3) (11, 14)
4、re.match與re.search的區別
re.match 只匹配字符串的開始,如果字符串開始不符合正則表達式,則匹配失敗,函數返回 None,而 re.search 匹配整個字符串,直到找到一個匹配。
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
matchObj = re.search( r'dogs', line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")以上實例輸出結果:
No match!! search --> matchObj.group() : dogs
5、參數:
| 參數 | 描述 |
|---|---|
| pattern | 匹配的正則表達式 |
| string | 要匹配的字符串。 |
| flags | 標誌位,用於控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等。參見:正則表達式修飾符 - 可選標誌 |
實例
import re
it = re.finditer(r"\d+","12a32bc43jf3")
for match in it:
print (match.group() )輸出結果:
12 32 43 3
(二)修改類
1、檢索和替換
Python 的re模塊提供了re.sub用於替換字符串中的匹配項。
語法:
re.sub(pattern, repl, string, count=0, flags=0)參數:
- pattern : 正則中的模式字符串。
- repl : 替換的字符串,也可爲一個函數。
- string : 要被查找替換的原始字符串。
- count : 模式匹配後替換的最大次數,默認 0 表示替換所有的匹配。
- flags : 編譯時用的匹配模式,數字形式。
前三個爲必選參數,後兩個爲可選參數。
import re
phone = "2004-959-559 # 這是一個電話號碼"
# 刪除註釋
num = re.sub(r'#.*$', "", phone)
print ("電話號碼 : ", num)
# 移除非數字的內容
num = re.sub(r'\D', "", phone)
print ("電話號碼 : ", num)輸出結果:
電話號碼 : 2004-959-559 電話號碼 : 2004959559
repl 參數是一個函數
以下實例中將字符串中的匹配的數字乘於 2:
import re
# 將匹配的數字乘於 2
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s))輸出結果:
A46G8HFD1134
2、re.split
split 方法按照能夠匹配的子串將字符串分割後返回列表,它的使用形式如下:
re.split(pattern, string[, maxsplit=0, flags=0])| 參數 | 描述 |
|---|---|
| pattern | 匹配的正則表達式 |
| string | 要匹配的字符串。 |
| maxsplit | 分隔次數,maxsplit=1 分隔一次,默認爲 0,不限制次數。 |
| flags | 標誌位,用於控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等。參見:正則表達式修飾符 - 可選標誌 |
>>>import re
>>> re.split('\W+', 'runoob, runoob, runoob.')
['runoob', 'runoob', 'runoob', '']
>>> re.split('(\W+)', ' runoob, runoob, runoob.')
['', ' ', 'runoob', ', ', 'runoob', ', ', 'runoob', '.', '']
>>> re.split('\W+', ' runoob, runoob, runoob.', 1)
['', 'runoob, runoob, runoob.']
>>> re.split('a*', 'hello world') # 對於一個找不到匹配的字符串而言,split 不會對其作出分割
['hello world'](三)貪婪和非貪婪模式
1、概念
首先舉個例子:
example = "abbbbbbc"
pattern = re.compile("ab+")貪婪模式:正則表達式一般趨向於最大長度匹配,也就是所謂的貪婪匹配。如上面使用模式pattern 匹配字符串example,匹配到的結果就是”abbbbbb”整個字符串。
非貪婪模式:在整個表達式匹配成功的前提下,儘可能少的匹配。如上面使用模式pattern 匹配字符串example,匹配到的結果就只是”ab”整個字符串。
2、使用方法
在python中默認採用的是貪婪模式,使用非貪婪模式的話,只需要在量詞後面直接加上一個問號”?”。
在第一篇文章中介紹了正則表達式當中的量詞一共有五種:
3、原理分析
在正則表達式中一般默認採用的是貪婪模式,在上面的例子當中已經匹配到了“ab”時已經可以使整個表達式匹配成功,但是由於採用的是貪婪模式,所以還需要往後繼續匹配,檢查時候存在更長的可以匹配成功的字符串。一直到匹配到最後一個”b”的時候,後面已經沒有可以成功匹配的字符串了,匹配結束。返回匹配結果“abbbbbb”。
所以,我們可以將貪婪模式理解爲:在整個表達式匹配成功的前提下,儘可能多的匹配。
非貪婪模式也就是將我們例子中的正則表達式“ab+”改爲”ab+?”,當匹配到“ab”時,已經匹配成功,直接結束匹配,不在向後繼續嘗試,返回匹配成功的字符串”ab”。
所以,我們可以將非貪婪模式理解爲:在整個表達式匹配成功的前提下,儘可能少的匹配
4、實例
import re
text = 'Beautifulis better than ugly. Explicit is better than implicit.'
print(re.findall('Beautifulis.*\.',text))
print(re.findall('Beautifulis.*?\.',text))輸出結果:
['Beautifulis better than ugly. Explicit is better than implicit.'] ['Beautifulis better than ugly.']
5、總結
1.從應用角度看貪婪與非貪婪
貪婪與非貪婪模式影響的是被量詞修飾的子表達式的匹配行爲,貪婪模式在整個表達式匹配成功的前提下,儘可能多的匹配;而非貪婪模式在整個表達式匹配成功的前提下,儘可能少的匹配。
2.從匹配原理角度看貪婪與非貪婪
能達到同樣匹配結果的貪婪與非貪婪模式,通常是貪婪模式的匹配效率較高。 所有的非貪婪模式,都可以通過修改量詞修飾的子表達式,轉換爲貪婪模式。 貪婪模式可以與固化分組結合,提升匹配效率,而非貪婪模式卻不可以。
(四)Python3 replace()方法
描述
replace() 方法把字符串中的 old(舊字符串) 替換成 new(新字符串),如果指定第三個參數max,則替換不超過 max 次。
語法
replace()方法語法:
str.replace(old, new[, max])參數
- old -- 將被替換的子字符串。
- new -- 新字符串,用於替換old子字符串。
- max -- 可選字符串, 替換不超過 max 次
返回值
返回字符串中的 old(舊字符串) 替換成 new(新字符串)後生成的新字符串,如果指定第三個參數max,則替換不超過 max 次。
實例
以下實例展示了replace()函數的使用方法:
data = 'What is the difference between python 2.7.5 and Python 3.8.1 ?'
print(data)
import re
r_data = data.replace('2.7.5','x.x.x')
r_data2 = r_data.replace('3.8.1','x.x.x')
print(r_data2)
print(re.sub('[0-9]\.[0-9]\.[0-9]','x.x.x',data))
print(data.split())
print(re.split('[ .]+',data))輸出結果:
What is the difference between python 2.7.5 and Python 3.8.1 ? What is the difference between python x.x.x and Python x.x.x ? What is the difference between python x.x.x and Python x.x.x ? ['What', 'is', 'the', 'difference', 'between', 'python', '2.7.5', 'and', 'Python', '3.8.1', '?'] ['What', 'is', 'the', 'difference', 'between', 'python', '2', '7', '5', 'and', 'Python', '3', '8', '1', '?']
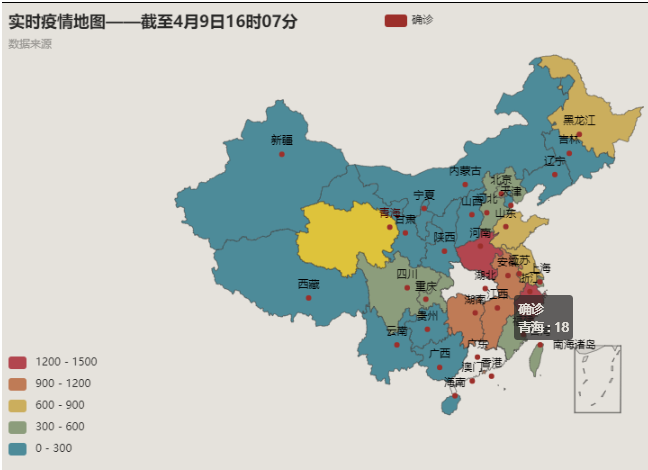
(五)繪製一個簡單的疫情地圖
from pyecharts.charts import Map
from pyecharts import options as opt
import requests
import json
#獲取數據
data = requests.get( 'https://gwpre.sina.cn/interface/fymap2020_data.json').content
data = json.loads(data)
print(data)
#篩選數據
sub_data = list()
for i in data['data']['list']:
sub_data.append((i['name'],i['value']))
print(sub_data)
#繪製中國地圖
map_info = Map()
#設置地圖的基本信息
map_info.set_global_opts(title_opts=opt.TitleOpts('實時疫情地圖——'+data['data' ]['times']
,subtitle='數據來源',
subtitle_link='https://news.sina.cn/zt_d/yiqing0121?vt=4&pos=222')
,visualmap_opts=opt.VisualMapOpts (max_=1500,is_piecewise=True))
map_info.add('確診', sub_data, maptype='china')
#生成網頁文件
map_info.render( '20200403.html' )輸出之後會生成一個網頁信息,執行一下這個網頁即可看到:
(六)使用正則表達式解析拉勾網某頁面內的所有http或者https鏈接
import re
import requests
r = requests.get('https://www.lagou.com/beijing')
# print(r)
result = re.findall('"(https?://.*?)"',r.content.decode('utf-8'))
print(result)輸出結果:
['https://www.lagou.com/beijing/', 'https://www.lagou.com/', 'https://www.lagou.com/about.html', 'http://www.beian.gov.cn/portal/registerSystemInfo?recordcode=11010802024043', 'https://www.lagou.com/upload/oss.js?v=1010']
-----