




一.Zset編碼的選擇

1.有序集合對象的編碼可以是ziplist或者skiplist。同時滿足以下條件時使用ziplist編碼:
- 元素數量小於128個
- 所有member的長度都小於64字節
- 其他:
- 不能滿足上面兩個條件的使用 skiplist 編碼。以上兩個條件也可以通過Redis配置文件zset-max-ziplist-entries 選項和 zset-max-ziplist-value 進行修改
- 對於一個
REDIS_ENCODING_ZIPLIST編碼的 Zset, 只要滿足以上任一條件, 則會被轉換爲REDIS_ENCODING_SKIPLIST編碼
2.zset操作命令
zadd(key, score, member):向名稱爲key的zset中添加元素member,score用於排序。如果該元素已經存在,則根據score更新該元素的順序。
zrem(key, member) :刪除名稱爲key的zset中的元素member
zincrby(key, increment, member) :如果在名稱爲key的zset中已經存在元素member,則該元素的score增加increment;否則向集合中添加該元素,其score的值爲increment
zrank(key, member) :返回名稱爲key的zset(元素已按score從小到大排序)中member元素的rank(即index,從0開始),若沒有member元素,返回“nil”
zrevrank(key, member) :返回名稱爲key的zset(元素已按score從大到小排序)中member元素的rank(即index,從0開始),若沒有member元素,返回“nil”
zrange(key, start, end):返回名稱爲key的zset(元素已按score從小到大排序)中的index從start到end的所有元素
zrevrange(key, start, end):返回名稱爲key的zset(元素已按score從大到小排序)中的index從start到end的所有元素
zrangebyscore(key, min, max):返回名稱爲key的zset中score >= min且score <= max的所有元素 zcard(key):返回名稱爲key的zset的基數
zscore(key, element):返回名稱爲key的zset中元素element的score zremrangebyrank(key, min, max):刪除名稱爲key的zset中rank >= min且rank <= max的所有元素 zremrangebyscore(key, min, max) :刪除名稱爲key的zset中score >= min且score <= max的所有元素
二.ziplist
1. 介紹
ziplist 編碼的 Zset 使用緊挨在一起的壓縮列表節點來保存,第一個節點保存 member,第二個保存 score。ziplist 內的集合元素按 score 從小到大排序,其實質是一個雙向鏈表。雖然元素是按 score 有序排序的, 但對 ziplist 的節點指針只能線性地移動,所以在 REDIS_ENCODING_ZIPLIST 編碼的 Zset 中, 查找某個給定元素的複雜度爲 O(N)O(N)。
2.
//操作
ZADD price 8.5 apple 5.0 banana 6.0 cherry
//存儲順序

3. 從以上的佈局中,我們可以看到ziplist內存數據結構,由如下5部分構成:

各個部分在內存上是前後相鄰的並連續的,每一部分作用如下:
-
zlbytes: 存儲一個無符號整數,固定四個字節長度(32bit),用於存儲壓縮列表所佔用的字節(也包括<zlbytes>本身佔用的4個字節),當重新分配內存的時候使用,不需要遍歷整個列表來計算內存大小。
-
zltail: 存儲一個無符號整數,固定四個字節長度(32bit),表示ziplist表中最後一項(entry)在ziplist中的偏移字節數。<zltail>的存在,使得我們可以很方便地找到最後一項(不用遍歷整個ziplist),從而可以在ziplist尾端快速地執行push或pop操作。
-
zllen: 壓縮列表包含的節點個數,固定兩個字節長度(16bit), 表示ziplist中數據項(entry)的個數。由於zllen字段只有16bit,所以可以表達的最大值爲2^16-1。
注意點:如果ziplist中數據項個數超過了16bit能表達的最大值,ziplist仍然可以表示。ziplist是如何做到的?
如果<zllen>小於等於2^16-2(也就是不等於2^16-1),那麼<zllen>就表示ziplist中數據項的個數;否則,也就是<zllen>等於16bit全爲1的情況,那麼<zllen>就不表示數據項個數了,這時候要想知道ziplist中數據項總數,那麼必須對ziplist從頭到尾遍歷各個數據項,才能計數出來。
-
entry,表示真正存放數據的數據項,長度不定。一個數據項(entry)也有它自己的內部結構。
三.skiplist
1.介紹
skiplist 編碼的 Zset 底層爲一個被稱爲 zset 的結構體,這個結構體中包含一個字典和一個跳躍表。跳躍表按 score 從小到大保存所有集合元素,查找時間複雜度爲平均
O(logN)O(logN),最壞 O(N
O(N) 。字典則保存着從 member 到 score 的映射,這樣就可以用 O(1)O(1) 的複雜度來查找 member 對應的 score 值。雖然同時使用兩種結構,但它們會通過指針來共享相同元素的 member 和 score,因此不會浪費額外的內存。
2.詳解
跳錶(skip List)是一種隨機化的數據結構,基於並聯的鏈表,實現簡單,插入、刪除、查找的複雜度均爲O(logN)。簡單說來跳錶也是鏈表的一種,只不過它在鏈表的基礎上增加了跳躍功能,正是這個跳躍的功能,使得在查找元素時,跳錶能夠提供O(logN)的時間複雜度。
先來看一個有序鏈表,如下圖(最左側的灰色節點表示一個空的頭結點):

在這樣一個鏈表中,如果我們要查找某個數據,那麼需要從頭開始逐個進行比較,直到找到包含數據的那個節點,或者找到第一個比給定數據大的節點爲止(沒找到)。也就是說,時間複雜度爲O(n)。同樣,當我們要插入新數據的時候,也要經歷同樣的查找過程,從而確定插入位置。
假如我們每相鄰兩個節點增加一個指針,讓指針指向下下個節點,如下圖:

這樣所有新增加的指針連成了一個新的鏈表,但它包含的節點個數只有原來的一半(上圖中是7, 19, 26)。現在當我們想查找數據的時候,可以先沿着這個新鏈表進行查找。當碰到比待查數據大的節點時,再回到原來的鏈表中進行查找。比如,我們想查找23,查找的路徑是沿着下圖中標紅的指針所指向的方向進行的:

- 23首先和7比較,再和19比較,比它們都大,繼續向後比較。
- 但23和26比較的時候,比26要小,因此回到下面的鏈表(原鏈表),與22比較。
- 23比22要大,沿下面的指針繼續向後和26比較。23比26小,說明待查數據23在原鏈表中不存在,而且它的插入位置應該在22和26之間。
在這個查找過程中,由於新增加的指針,我們不再需要與鏈表中每個節點逐個進行比較了。需要比較的節點數大概只有原來的一半。
利用同樣的方式,我們可以在上層新產生的鏈表上,繼續爲每相鄰的兩個節點增加一個指針,從而產生第三層鏈表。如下圖:

在這個新的三層鏈表結構上,如果我們還是查找23,那麼沿着最上層鏈表首先要比較的是19,發現23比19大,接下來我們就知道只需要到19的後面去繼續查找,從而一下子跳過了19前面的所有節點。可以想象,當鏈表足夠長的時候,這種多層鏈表的查找方式能讓我們跳過很多下層節點,大大加快查找的速度。
skiplist正是受這種多層鏈表的想法的啓發而設計出來的。實際上,按照上面生成鏈表的方式,上面每一層鏈表的節點個數,是下面一層的節點個數的一半,這樣查找過程就非常類似於一個二分查找,使得查找的時間複雜度可以降低到O(log n)。但是,這種方法在插入數據的時候有很大的問題。新插入一個節點之後,就會打亂上下相鄰兩層鏈表上節點個數嚴格的2:1的對應關係。如果要維持這種對應關係,就必須把新插入的節點後面的所有節點(也包括新插入的節點)重新進行調整,這會讓時間複雜度重新蛻化成O(n)。刪除數據也有同樣的問題。
skiplist爲了避免這一問題,它不要求上下相鄰兩層鏈表之間的節點個數有嚴格的對應關係,而是爲每個節點隨機出一個層數(level)。比如,一個節點隨機出的層數是3,那麼就把它鏈入到第1層到第3層這三層鏈表中。爲了表達清楚,下圖展示瞭如何通過一步步的插入操作從而形成一個skiplist的過程:
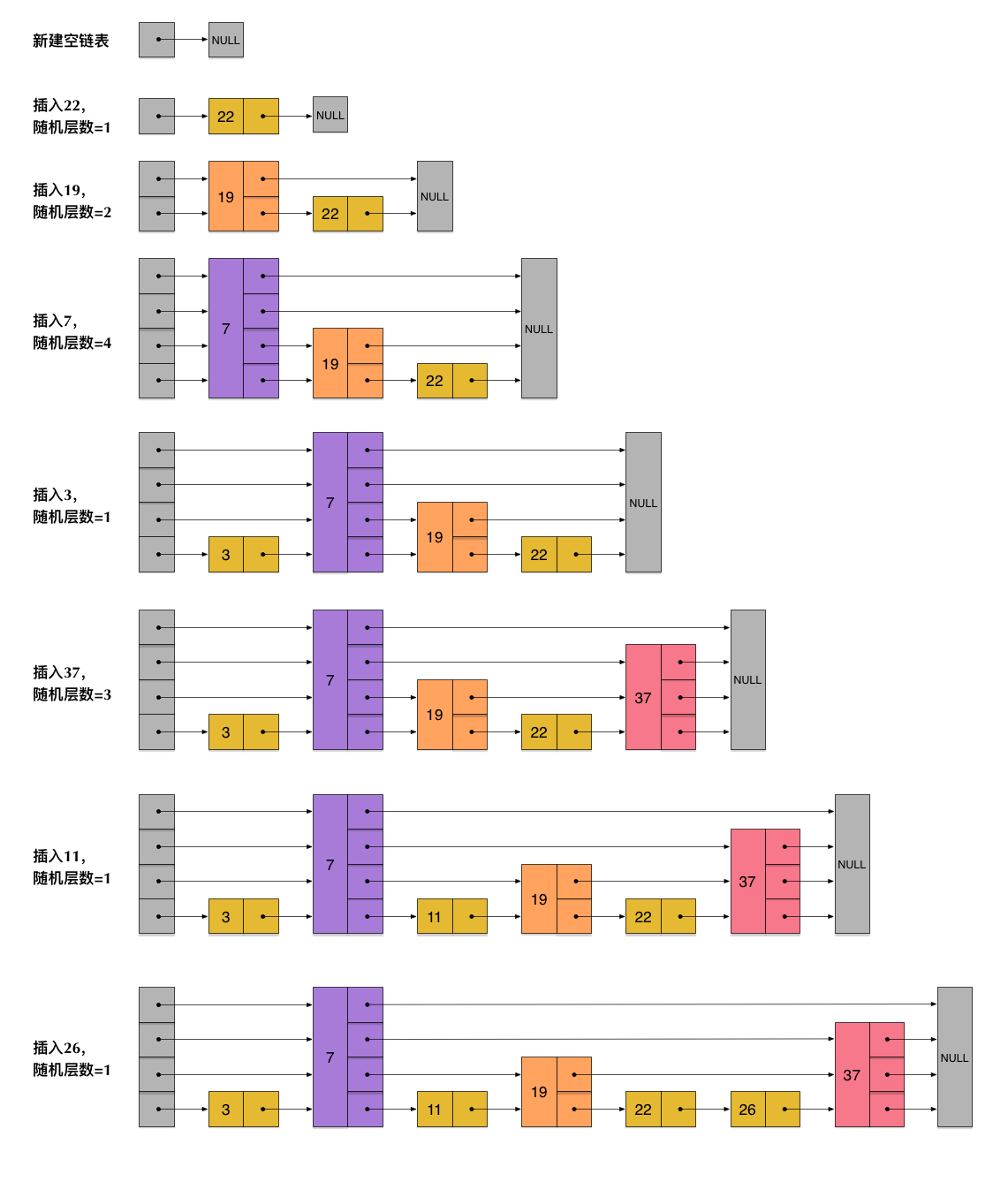
從上面skiplist的創建和插入過程可以看出,每一個節點的層數(level)是隨機出來的,而且新插入一個節點不會影響其它節點的層數。因此,插入操作只需要修改插入節點前後的指針,而不需要對很多節點都進行調整。這就降低了插入操作的複雜度。實際上,這是skiplist的一個很重要的特性,這讓它在插入性能上明顯優於平衡樹的方案。這在後面我們還會提到。
skiplist,指的就是除了最下面第1層鏈表之外,它會產生若干層稀疏的鏈表,這些鏈表裏面的指針故意跳過了一些節點(而且越高層的鏈表跳過的節點越多)。這就使得我們在查找數據的時候能夠先在高層的鏈表中進行查找,然後逐層降低,最終降到第1層鏈表來精確地確定數據位置。在這個過程中,我們跳過了一些節點,從而也就加快了查找速度。
剛剛創建的這個skiplist總共包含4層鏈表,現在假設我們在它裏面依然查找23,下圖給出了查找路徑:
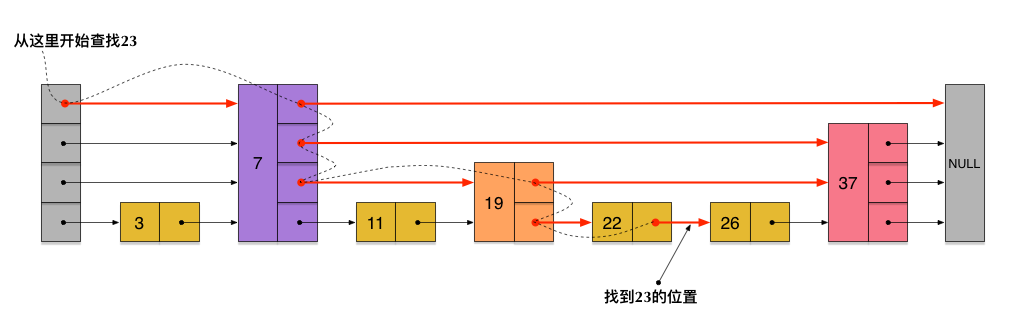
需要注意的是,前面演示的各個節點的插入過程,實際上在插入之前也要先經歷一個類似的查找過程,在確定插入位置後,再完成插入操作。
實際應用中的skiplist每個節點應該包含key和value兩部分。前面的描述中我們沒有具體區分key和value,但實際上列表中是按照key(score)進行排序的,查找過程也是根據key在比較。
執行插入操作時計算隨機數的過程,是一個很關鍵的過程,它對skiplist的統計特性有着很重要的影響。這並不是一個普通的服從均勻分佈的隨機數,它的計算過程如下:
- 首先,每個節點肯定都有第1層指針(每個節點都在第1層鏈表裏)。
- 如果一個節點有第i層(i>=1)指針(即節點已經在第1層到第i層鏈表中),那麼它有第(i+1)層指針的概率爲p。
- 節點最大的層數不允許超過一個最大值,記爲MaxLevel。
這個計算隨機層數的僞碼如下所示:
randomLevel()
level := 1
// random()返回一個[0...1)的隨機數
while random() < p and level < MaxLevel do
level := level + 1
return level
randomLevel()的僞碼中包含兩個參數,一個是p,一個是MaxLevel。在Redis的skiplist實現中,這兩個參數的取值爲:
p = 1/4
MaxLevel = 32
四.skiplist與平衡樹、哈希表的比較
- skiplist和各種平衡樹(如AVL、紅黑樹等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做單個key的查找,不適宜做範圍查找。所謂範圍查找,指的是查找那些大小在指定的兩個值之間的所有節點。
- 在做範圍查找的時候,平衡樹比skiplist操作要複雜。在平衡樹上,我們找到指定範圍的小值之後,還需要以中序遍歷的順序繼續尋找其它不超過大值的節點。如果不對平衡樹進行一定的改造,這裏的中序遍歷並不容易實現。而在skiplist上進行範圍查找就非常簡單,只需要在找到小值之後,對第1層鏈表進行若干步的遍歷就可以實現。
- 平衡樹的插入和刪除操作可能引發子樹的調整,邏輯複雜,而skiplist的插入和刪除只需要修改相鄰節點的指針,操作簡單又快速。
- 從內存佔用上來說,skiplist比平衡樹更靈活一些。一般來說,平衡樹每個節點包含2個指針(分別指向左右子樹),而skiplist每個節點包含的指針數目平均爲1/(1-p),具體取決於參數p的大小。如果像Redis裏的實現一樣,取p=1/4,那麼平均每個節點包含1.33個指針,比平衡樹更有優勢。
- 查找單個key,skiplist和平衡樹的時間複雜度都爲O(log n),大體相當;而哈希表在保持較低的哈希值衝突概率的前提下,查找時間複雜度接近O(1),性能更高一些。所以我們平常使用的各種Map或dictionary結構,大都是基於哈希表實現的。
- 從算法實現難度上來比較,skiplist比平衡樹要簡單得多。
五.Redis中的skiplist實現
skiplist的數據結構定義:
#define ZSKIPLIST_MAXLEVEL 32
#define ZSKIPLIST_P 0.25
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
簡單分析一下幾個查詢命令:
- zrevrank由數據查詢它對應的排名,這在前面介紹的skiplist中並不支持。
- zscore由數據查詢它對應的分數,這也不是skiplist所支持的。
- zrevrange根據一個排名範圍,查詢排名在這個範圍內的數據。這在前面介紹的skiplist中也不支持。
- zrevrangebyscore根據分數區間查詢數據集合,是一個skiplist所支持的典型的範圍查找(score相當於key,數據相當於value)。
實際上,Redis中sorted set的實現是這樣的:
- 當數據較少時,sorted set是由一個ziplist來實現的。
- 當數據多的時候,sorted set是由一個dict + 一個skiplist來實現的。簡單來講,dict用來查詢數據到分數的對應關係,而skiplist用來根據分數查詢數據(可能是範圍查找)。
看一下sorted set與skiplist的關係,:
- zscore的查詢,不是由skiplist來提供的,而是由那個dict來提供的。
- 爲了支持排名(rank),Redis裏對skiplist做了擴展,使得根據排名能夠快速查到數據,或者根據分數查到數據之後,也同時很容易獲得排名。而且,根據排名的查找,時間複雜度也爲O(log n)。
- zrevrange的查詢,是根據排名查數據,由擴展後的skiplist來提供。
- zrevrank是先在dict中由數據查到分數,再拿分數到skiplist中去查找,查到後也同時獲得了排名。
總結起來,Redis中的skiplist跟前面介紹的經典的skiplist相比,有如下不同:
- 分數(score)允許重複,即skiplist的key允許重複。這在最開始介紹的經典skiplist中是不允許的。
- 在比較時,不僅比較分數(相當於skiplist的key),還比較數據本身。在Redis的skiplist實現中,數據本身的內容唯一標識這份數據,而不是由key來唯一標識。另外,當多個元素分數相同的時候,還需要根據數據內容來進字典排序。
- 第1層鏈表不是一個單向鏈表,而是一個雙向鏈表。這是爲了方便以倒序方式獲取一個範圍內的元素。
- 在skiplist中可以很方便地計算出每個元素的排名(rank)。
六.Redis爲什麼用skiplist而不用平衡樹?
這裏從內存佔用、對範圍查找的支持和實現難易程度這三方面總結的原因。
There are a few reasons:
1) They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
1) 也不是非常耗費內存,實際上取決於生成層數函數裏的概率 p,取決得當的話其實和平衡樹差不多。
2) A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
2) 因爲有序集合經常會進行 ZRANGE 或 ZREVRANGE 這樣的範圍查找操作,跳錶裏面的雙向鏈表可以十分方便地進行這類操作。
3) They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
3) 實現簡單,ZRANK 操作還能達到 o(logn)的時間複雜度O
參考:https://zsr.github.io/2017/07/03/redis-zset%E5%86%85%E9%83%A8%E5%AE%9E%E7%8E%B0/